Python 实现导入三份EXCEL表自动生成每周的考核周报WORD文档
入手新部门,需要每周做一份维护组的考核报表,当初开始的时候做第一份考核报表花了近2个小时才做出一份考核报表。
后来想想作为一个小程序员,不能这么傻乎乎的做这些机械的工作,要做点自动化报表的小程序,经常近一个星期的晚上的修修补补终于完成。
本文采用了以下第三方包:
# coding=utf-8
from Tkinter import *
from tkFileDialog import *
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import Border, Side, Font # 设置字体和边框需要的模块
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
from docx.enum.text import WD_ALIGN_PARAGRAPH # 段落居中
import random
import os
import sys
import xlrd #读excel要用到xlrd模块
import xlwt #写excel表要用到xlwt模块
from datetime import date,datetime
要读取的是三份文件:第一份是地区基站与维护人员对应关系表(openpyxl读取xlsx文档),需要该文档的1张表;第二份是地区故障数据EXCEL文档(openpyxl读取xlsx文档),计算为基准分,需要该文档的4张表;第三份是目前未恢复的地区与维护人员对应关系表(用到xlrd模块读xls文档,用到xlwt模块写xls文档),作为减分项,需要该文档的1张表;
最后需要对6张表进行操作,然后自动生成考核分析WORD文档。

对地区故障数据,计算为考核分时:
当小于等于挑战值,得100;
当大于挑战值,但小于基准值,按挑战值与基准值之间的线性关系得分。(60-100之间)
当大于基准值,就不能按线性得分,因为线性一次函数与X轴有交点,交点之后为负值,但考核分起码为正数才合理。该部分的 得分为60/(退服时长/基准值)。即为一个反函数,反函数会不断趋近于0,而不接近0.
程序运行打开的界面如下:

# coding=utf-8
from Tkinter import *
from tkFileDialog import *
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import Border, Side, Font # 设置字体和边框需要的模块
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
from docx.enum.text import WD_ALIGN_PARAGRAPH # 段落居中
import random
import os
import sys
import xlrd
import datetime #获取时间
import time
from docx.enum.style import WD_STYLE_TYPE #获取所有word表格样式
class App:
def __init__(self, root):
frame = Frame(root) # container
frame.pack()
# self.quitButton = Button(frame, text='quit', command=frame.quit)
# self.quitButton.pack()
#
# self.hiButton = Button(frame, text='Say Hi', command=self.sayHi)
# self.hiButton.pack()
self.button1 = Button(frame, text="退服周报文件", command=self.filefound1, width=20, height=1).grid(row=0, column=0)
self.button2 = Button(frame, text="街道基站文件", command=self.filefound2, width=20, height=1).grid(row=1, column=0)
self.button3 = Button(frame, text="站点激活文件", command=self.filefound3, width=20, height=1).grid(row=2, column=0)
self.button4 = Button(frame, text="运行", command=self.execuate, width=20, height=1).grid(row=3, column=0)
self.button5 = Button(frame, text="退出", command=frame.quit, width=20, height=1).grid(row=4, column=0)
# self.button1.pack()
# self.button2.pack()
# self.button3.pack()
# self.button4.pack()
# self.button5.pack()
self.e = Entry(frame)
self.e.grid(row=0, column=2)
self.e.delete(0, END) # 将输入框里面的内容清空
self.e.insert(0, '显示文件路径')
self.e1 = Entry(frame)
self.e1.grid(row=1, column=2)
self.e1.delete(0, END) # 将输入框里面的内容清空
self.e1.insert(0, '显示文件路径')
self.e2 = Entry(frame)
self.e2.grid(row=2, column=2)
self.e2.delete(0, END) # 将输入框里面的内容清空
self.e2.insert(0, '显示文件路径')
self.filepath1 = StringVar()
self.filepath2 = StringVar()
self.filepath3 = StringVar()
# 打开文档
self.document = Document()
def get_week_of_month(self):
"""
获取指定的某天是某个月中的第几周
周一作为一周的开始
"""
t = time.gmtime()
end = int(datetime.datetime(t.tm_year, t.tm_mon, t.tm_mday).strftime("%W"))
begin = int(datetime.datetime(t.tm_year, t.tm_mon, 1).strftime("%W"))
return end - begin + 1
def filefound1(self):
self.filepath1 = askopenfilename()
print self.filepath1
self.e.delete(0, END) # 将输入框里面的内容清空
self.e.insert(0, self.filepath1)
return self.filepath1
def filefound2(self):
self.filepath2 = askopenfilename()
print self.filepath2
self.e1.delete(0, END) # 将输入框里面的内容清空
self.e1.insert(0, self.filepath2)
return self.filepath2
def filefound3(self):
self.filepath3 = askopenfilename()
print self.filepath3
self.e2.delete(0, END) # 将输入框里面的内容清空
self.e2.insert(0, self.filepath3)
return self.filepath3
def execuate(self):
# print self.filepath1, self.filepath2, self.filepath3
# 修改正文的中文字体类型,示例代码:(全局设置)
self.document.styles['Normal'].font.name = u'仿宋'
self.document.styles['Normal'].font.size = Pt(16) # 16对应仿宋三号
self.document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋')
styles = self.document.styles
cur = datetime.datetime.now() #当前时间
head_str = u'%s月份第%s周考核通报\n'%(cur.month,self.get_week_of_month()) # 文章标题
# document.add_heading(head_str,0)
head_paragraph = self.document.add_paragraph('') # 添加一个段落
head_paragraph.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER # 段落居中
run = head_paragraph.add_run(head_str)
run.bold = True # 粗体是
run.italic = False # 斜体否
self.document.styles['Normal'].font.size = Pt(12) # 12对应仿宋小四号
#上载excel文件
wb = load_workbook(self.filepath1, data_only=True)
wb_site_details = load_workbook(self.filepath2, data_only=True)
daily_retire_list = xlrd.open_workbook(self.filepath3) # 每日退服清单
sheets = wb.get_sheet_names()
print sheets
outofservice_sheet = wb.get_sheet_by_name(sheets[2]) # 当月清单
Retirement_index_sheet = wb.get_sheet_by_name(sheets[4]) # 各县市小区退服指标
Deactivation_2G_sheet = wb.get_sheet_by_name(sheets[5]) # 2G去激活清单
Deactivation_4G_sheet = wb.get_sheet_by_name(sheets[6]) # 4G去激活清单
sheet_site_details = wb_site_details.get_sheet_names() # 基站清单
print sheet_site_details
site_details_sheet = wb_site_details.get_sheet_by_name(sheet_site_details[0]) # 所有基站清单
site_dict = {u'基站清单': u'西湖基站'}
print u"基站清单"
print 'len=', len(site_dict)
for i in range(1, site_details_sheet.max_row): # 建立基站与维护经理的字典对应关系
site_dict[site_details_sheet.cell(row=i, column=1).value] = site_details_sheet.cell(row=i, column=7).value
print 'len=', len(site_dict)
ws = wb.active
rows = []
for row in ws.iter_rows():
rows.append(row)
print u"行高:", outofservice_sheet.max_row
print u"列宽:", outofservice_sheet.max_column
j = 1
print u"退服当月清单"
outofservice_dict_2G = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0, u'汤': 0.0, u'邵': 0.0, u'胡': 0.0,
u'陈': 0.0}
outofservice_dict_4G = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0, u'汤': 0.0, u'邵': 0.0, u'胡': 0.0,
u'陈': 0.0}
print 'outofservice_sheet.max_row = ', outofservice_sheet.max_row
print 'Deactivation_2G_sheet.max_row = ', Deactivation_2G_sheet.max_row
print 'Deactivation_4G_sheet.max_row = ', Deactivation_4G_sheet.max_row
for i in range(1, outofservice_sheet.max_row): # row
if outofservice_sheet.cell(row=i, column=1).value == u'西湖' and outofservice_sheet.cell(row=i,
column=1).value != u'':
# print j, outofservice_sheet.cell(row=i, column=4).value, outofservice_sheet.cell(row=i, column=5).value, outofservice_sheet.cell(row=i, column=18).value, '\n' # 获取第一行第一列的单元格对象的值
if not site_dict.has_key(outofservice_sheet.cell(row=i, column=5).value): # 基站与维护经理对应关系字典中找不到,另存在txt文件
# f.write(outofservice_sheet.cell(row=i, column=5).value)
print outofservice_sheet.cell(row=i, column=5).value
else:
weihu_name = site_dict[outofservice_sheet.cell(row=i, column=5).value]
if type(outofservice_sheet.cell(row=i, column=18).value).__name__ == 'NoneType' :
# print i, ' NoneType=',outofservice_sheet.cell(row=i, column=18).value, type(outofservice_sheet.cell(row=i, column=18).value)
continue
str = outofservice_sheet.cell(row=i, column=18).value.encode('raw_unicode_escape')
value = float(str)
#print i,weihu_name,outofservice_sheet.cell(row=i, column=5).value
if not outofservice_dict_2G.has_key(weihu_name) and not outofservice_dict_4G.has_key(weihu_name) :#有些基站属于拱墅区,无对应维护经理
continue
if outofservice_sheet.cell(row=i, column=4).value == '2G':
outofservice_dict_2G[weihu_name] += value
else:
outofservice_dict_4G[weihu_name] += value
j += 1
print u"\n2G退服清单"
print u'\n责任人,2G退服时长'
for key, value in outofservice_dict_2G.items():
# print u'2G %d,key = %s, value = %s' % (j, key, value)
print u'%s, %s' % (key, value)
print u"\n4G退服清单"
print u'\n责任人,4G退服时长'
for key, value in outofservice_dict_4G.items():
# print u'4G %d,key = %s, value = %s' % (j, key, value)
print u'%s, %s' % (key, value)
Deactivation_dict_2G = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0, u'汤': 0.0, u'邵': 0.0, u'胡': 0.0,
u'陈': 0.0}
Deactivation_dict_4G = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0, u'汤': 0.0, u'邵': 0.0, u'胡': 0.0,
u'陈': 0.0}
j = 1
print u"\n2G去激活清单"
print u'\n责任人,2G退服时长'
for i in range(1, Deactivation_2G_sheet.max_row): # row
if Deactivation_2G_sheet.cell(row=i, column=7).value == u'西湖' and Deactivation_2G_sheet.cell(row=i,column=7).value != u'':
if not site_dict.has_key(
Deactivation_2G_sheet.cell(row=i, column=5).value): # 基站与维护经理对应关系字典中找不到,另存在txt文件
print Deactivation_2G_sheet.ell(row=i, column=5).value
else:
weihu_name = site_dict[Deactivation_2G_sheet.cell(row=i, column=5).value]
if type(Deactivation_2G_sheet.cell(row=i, column=27).value).__name__ == 'NoneType':
continue
str = Deactivation_2G_sheet.cell(row=i, column=27).value.encode('raw_unicode_escape')
value = float(str)
Deactivation_dict_2G[weihu_name] += value
# print j, Deactivation_2G_sheet.cell(row=i, column=5).value, Deactivation_2G_sheet.cell(row=i, column=27).value, '\n' # 获取第一行第一列的单元格对象的值
j += 1
for key, value in Deactivation_dict_2G.items():
# print u'2G %d,key = %s, value = %s' % (j, key, value)
print u'%s, %s' % (key, value)
j = 1
print u"\n4G去激活清单"
print u'\n责任人,4G退服时长'
for i in range(1, Deactivation_4G_sheet.max_row): # row
if Deactivation_4G_sheet.cell(row=i, column=7).value == u'西湖' and Deactivation_4G_sheet.cell(row=i,
column=7).value != u'':
# print j, Deactivation_4G_sheet.cell(row=i, column=5).value, Deactivation_4G_sheet.cell(row=i, column=27).value, '\n' # 获取第一行第一列的单元格对象的值
if not site_dict.has_key(
Deactivation_4G_sheet.cell(row=i, column=5).value): # 基站与维护经理对应关系字典中找不到,另存在txt文件
str_no_site = Deactivation_4G_sheet.cell(row=i, column=5).value.encode('raw_unicode_escape')
# f.write(str_no_site)
print Deactivation_4G_sheet.cell(row=i, column=5).value
else:
weihu_name = site_dict[Deactivation_4G_sheet.cell(row=i, column=5).value]
if type(Deactivation_4G_sheet.cell(row=i, column=27).value).__name__ == 'NoneType':
continue
# print i,u'Deactivation_4G_sheet.cell(row=i, column=27)= ',Deactivation_4G_sheet.cell(row=i, column=27).value
if type(Deactivation_4G_sheet.cell(row=i, column=27).value).__name__ == 'long' or type(
Deactivation_4G_sheet.cell(row=i, column=27).value).__name__ == 'float':
Deactivation_dict_4G[weihu_name] += Deactivation_4G_sheet.cell(row=i, column=27).value
continue
str = Deactivation_4G_sheet.cell(row=i, column=27).value.encode('raw_unicode_escape')
value = float(str)
Deactivation_dict_4G[weihu_name] += value
j += 1
for key, value in Deactivation_dict_4G.items():
# print u'4G %d,key = %s, value = %s' % (j, key, value)
print u'%s, %s' % (key, value)
total_dict_2G = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0, u'汤': 0.0, u'邵': 0.0, u'胡': 0.0,
u'陈': 0.0}
total_dict_4G = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0, u'汤': 0.0, u'邵': 0.0, u'胡': 0.0,
u'陈': 0.0}
for key, value in Deactivation_dict_4G.items():
total_dict_2G[key] = Deactivation_dict_2G[key] / 2.0 + outofservice_dict_2G[key]
total_dict_4G[key] = Deactivation_dict_4G[key] / 2.0 + outofservice_dict_4G[key]
print u'\n总退服2G和4G统计清单'
print u'\n2G退服总统计'
print u'\n责任人,2G退服时长'
for key, value in total_dict_2G.items():
# print u'4G %d,key = %s, value = %s' % (j, key, value)
print u'%s, %s' % (key, value)
print u'\n4G退服总统计'
print u'\n责任人,4G退服时长'
for key, value in total_dict_4G.items():
# print u'4G %d,key = %s, value = %s' % (j, key, value)
print u'%s, %s' % (key, value)
Assessment_2G_dict = {u'周': [376, 101.52, 67.68, 0.0], u'郑': [596, 160.92, 107.28, 0.0], u'吴': [229, 61.83, 41.22, 0.0],
u'邬': [658, 177.66, 118.44, 0.0],
u'汤': [796, 214.92, 143.28, 0.0], u'邵': [295, 79.65, 53.1, 0.0], u'胡': [283, 76.41, 50.94, 0.0],
u'陈': [434, 117.18, 78.12, 0.0]}
Assessment_4G_dict = {u'周': [1994, 538.38, 358.92, 0.0], u'郑': [763, 206.01, 137.34, 0.0],
u'吴': [692, 186.84, 124.56, 0.0],
u'邬': [1076, 290.52, 193.68, 0.0],
u'汤': [2585, 697.95, 465.3, 0.0], u'邵': [1776, 479.52, 319.68, 0,0],
u'胡': [1846, 498.42, 332.28, 0.0],
u'陈': [498, 134.46, 89.64, 0.0]}
Weight_2G_dict = {u'周': [0.0, 0.0], u'郑': [0.0, 0.0], u'吴': [0.0, 0.0], u'邬': [0.0, 0.0],
u'汤': [0.0, 0.0],
u'邵': [0.0, 0.0], u'胡': [0.0, 0.0], u'陈': [0.0, 0.0]}
Weight_4G_dict = {u'周': [0.0, 0.0], u'郑': [0.0, 0.0], u'吴': [0.0, 0.0], u'邬': [0.0, 0.0],
u'汤': [0.0, 0.0],
u'邵': [0.0, 0.0], u'胡': [0.0, 0.0], u'陈': [0.0, 0.0]}
print u"\n\n2G考核分数"
print u"\n责任人,当前2G退服时长,(基站数,基准值,挑战值),得分"
one_para = u'1、街道退服时长考核统计\n'
one_para += u'2G退服总时长为%s小时,4G退服总时长为%s小时\n\n' % (round(Retirement_index_sheet.cell(row=7, column=6).value,2), round(Retirement_index_sheet.cell(row=7, column=16).value,2) )
one_para += u'当前退服执行情况,预计第一名为邬,所在街道2G与4G退服时长总体最小,2G达到市公司分解到街道退服时长指标的挑战值要求,4G退服时长也较小;第二名周,也达到街道退服时长指标的基准值要求。排名后续的同事得加把油力争减少退服时长,再接再励达到退服基准值。'
one_para += u'\n\n2G考核分数'
self.document.add_paragraph(one_para)
table_1 = self.document.add_table(rows=9, cols=6,style = "Light Shading Accent 1")
table_1.rows[0].cells[0].text = u"责任人"
table_1.rows[0].cells[1].text = u"当前2G退服时长"
table_1.rows[0].cells[2].text = u"基站数"
table_1.rows[0].cells[3].text = u"基准值"
table_1.rows[0].cells[4].text = u"挑战值"
table_1.rows[0].cells[5].text = u"得分"
for key, value in total_dict_2G.items():
if value <= Assessment_2G_dict[key][2]:
dagree = 100
elif value > Assessment_2G_dict[key][2] and value <= Assessment_2G_dict[key][1]:
dagree = 40.0 * (value - Assessment_2G_dict[key][1]) / (
Assessment_2G_dict[key][2] - Assessment_2G_dict[key][1]) + 60.0
else:
dagree = 60.0 / (value / (Assessment_2G_dict[key][1]))
Weight_2G_dict[key][0] = Assessment_2G_dict[key][0]
Weight_2G_dict[key][1] = dagree
Assessment_2G_dict[key][3] = round(dagree, 2) #保存用于排序
print u'%s, %s ,%s, %.2f' % (key, value, Assessment_2G_dict[key], dagree)
# sorted()都接受一个参数reverse(True or False)来表示升序或降序排序。
Assessment_2G_Rank = sorted(Assessment_2G_dict.items(), key=lambda item: item[1][3], reverse = True)
#print Assessment_2G_dict_Rank # 返回的Assessment_2G_Rank为list
i = 1
for item in Assessment_2G_Rank:
hdr_cells = table_1.rows[i].cells
hdr_cells[0].text = u'%s' % item[0]
hdr_cells[1].text = u'%s' % round(total_dict_2G[item[0]], 2)
hdr_cells[2].text = u'%s' % item[1][0]
hdr_cells[3].text = u'%s' % round(item[1][1], 2)
hdr_cells[4].text = u'%s' % round(item[1][2], 2)
hdr_cells[5].text = u'%s' % round(item[1][3], 2)
i += 1
print u"\n\n4G考核分数"
print u"\n责任人,当前4G退服时长,(基站数,基准值,挑战值),得分"
two_para = u'\n4G考核分数'
self.document.add_paragraph(two_para)
table_2 = self.document.add_table(rows=9, cols=6,style = "Light Shading Accent 1")
table_2.rows[0].cells[0].text = u"责任人"
table_2.rows[0].cells[1].text = u"当前4G退服时长"
table_2.rows[0].cells[2].text = u"基站数"
table_2.rows[0].cells[3].text = u"基准值"
table_2.rows[0].cells[4].text = u"挑战值"
table_2.rows[0].cells[5].text = u"得分"
for key, value in total_dict_4G.items():
if value <= Assessment_4G_dict[key][2]:
dagree = 100
elif value > Assessment_4G_dict[key][2] and value <= Assessment_4G_dict[key][1]:
dagree = 40.0 * (value - Assessment_4G_dict[key][1]) / (
Assessment_4G_dict[key][2] - Assessment_4G_dict[key][1]) + 60.0
else:
dagree = 60.0 / (value / (Assessment_4G_dict[key][1]))
Weight_4G_dict[key][0] = Assessment_4G_dict[key][0]
Weight_4G_dict[key][1] = dagree
Assessment_4G_dict[key][3] = round(dagree, 2) # 保存用于排序
print u'%s, %s ,%s, %.2f' % (key, value, Assessment_4G_dict[key], dagree)
# sorted()都接受一个参数reverse(True or False)来表示升序或降序排序。
Assessment_4G_Rank = sorted(Assessment_4G_dict.items(), key=lambda item: item[1][3], reverse=True)
# print Assessment_2G_dict_Rank # 返回的Assessment_2G_Rank为list
i = 1
for item in Assessment_4G_Rank:
hdr_cells = table_2.rows[i].cells
hdr_cells[0].text = u'%s' % item[0]
hdr_cells[1].text = u'%s' % round(total_dict_4G[item[0]], 2)
hdr_cells[2].text = u'%s' % item[1][0]
hdr_cells[3].text = u'%s' % round(item[1][1], 2)
hdr_cells[4].text = u'%s' % round(item[1][2], 2)
hdr_cells[5].text = u'%s' % round(item[1][3], 2)
i += 1
print u"\n每日导出退服清单"
daily_retire_dict = {u'周': 0.0, u'郑': 0.0, u'吴': 0.0, u'邬': 0.0,
u'汤': 0.0, u'邵': 0.0, u'胡': 0.0, u'陈': 0.0}
# table = data.sheets()[0] # 通过索引顺序获取
# table = data.sheet_by_index(0) # 通过索引顺序获取
table = daily_retire_list.sheet_by_name(u'详细') # 通过名称获取每日退服清单
# 获取行数和列数 # table.nrows # table.ncols
total_day = 0.0
for i in range(table.nrows): # 显示每日退服清单
# print table.cell(i, 0).value, table.cell(i, 1).value, table.cell(i, 3).value, table.cell(i, 4).value
if daily_retire_dict.has_key(table.cell(i, 3).value):
daily_retire_dict[table.cell(i, 3).value] += table.cell(i, 4).value
total_day += table.cell(i, 4).value
three_para = u'\n2、当前基站退服开销时间统计(扣分项,一天扣0.1分)'
three_para += u"\n总计 基站退服开销时间为%d天。" % round(total_day,2)
three_para += u"\n当前退服开销天数情况,汤开销天数最多,排名较前的同事得加把油力争减少退服开销天数。"
self.document.add_paragraph(three_para)# 保存段落到文档中
table_3 = self.document.add_table(rows=9, cols=3,style = "Light Shading Accent 1")
table_3.rows[0].cells[0].text = u"责任人"
table_3.rows[0].cells[1].text = u"开销天数"
table_3.rows[0].cells[2].text = u"开销减分"
print u"\n开销天数"
# sorted()都接受一个参数reverse(True or False)来表示升序或降序排序。# 返回的Assessment_2G_Rank为list
daily_retire_Rank = sorted(daily_retire_dict.items(), key=lambda item: item[1])
i = 1
for item in daily_retire_Rank:
hdr_cells = table_3.rows[i].cells
hdr_cells[0].text = u'%s' % item[0]
hdr_cells[1].text = u'%s' % round(item[1], 2)
hdr_cells[2].text = u'%s' % round(item[1]*0.1, 2)
i += 1
print u"\n根据开销天数、2G和4G基站数加权计算最终考核分数"
print u"\n责任人,所在街道分数,开销减分,总和得分,折算考核分"
four_para = u'\n\n最后的得分数'
four_para += u"\n根据开销天数、2G和4G基站数加权计算最终考核分数"
self.document.add_paragraph(four_para)# 保存段落到文档中
table_4 = self.document.add_table(rows=9, cols=5,style = "Light Shading Accent 1")
table_4.rows[0].cells[0].text = u"责任人"
table_4.rows[0].cells[1].text = u"所在街道分数"
table_4.rows[0].cells[2].text = u"开销减分"
table_4.rows[0].cells[3].text = u"总和得分"
table_4.rows[0].cells[4].text = u"折算考核分"
# Final_Score_dict 储存 责任人 所在街道分数 开销减分 总和得分 折算考核分 等信息
Final_Score_dict = {u'周': [0.0, 0.0, 0.0, 0.0], u'郑': [0.0, 0.0, 0.0, 0.0],
u'吴': [0.0, 0.0, 0.0, 0.0],
u'邬': [0.0, 0.0, 0.0, 0.0],
u'汤': [0.0, 0.0, 0.0, 0.0], u'邵': [0.0, 0.0, 0.0, 0.0],
u'胡': [0.0, 0.0, 0.0, 0.0],
u'陈': [0.0, 0.0, 0.0, 0.0]}
i = 1
for key, value in total_dict_4G.items():
total_site = Weight_2G_dict[key][0] + Weight_4G_dict[key][0]
kaixiao_score = 0.1 * daily_retire_dict[key]
Final_Score_dict[key][1] = kaixiao_score #开销减分
score = 1.0 * Weight_2G_dict[key][1] * Weight_2G_dict[key][0] / total_site + 1.0 * Weight_4G_dict[key][1] * Weight_4G_dict[key][0] / total_site
Final_Score_dict[key][0] = score # 所在街道分数
final_score = score - kaixiao_score
Final_Score_dict[key][2] = final_score # 总和得分
Final_Score_dict[key][3] = 12.0 * 1.1 * final_score/100.00 # 折算考核分
if Final_Score_dict[key][3] < 0:
Final_Score_dict[key][3] = 0
print u'%s, %.2f , %.2f, %.2f, %.2f ' % (key, score, kaixiao_score, final_score, 12.0 * 1.1 * final_score / 100)
# sorted()都接受一个参数reverse(True or False)来表示升序或降序排序。 # 返回的Assessment_2G_Rank为list
Final_Score_Rank = sorted(Final_Score_dict.items(), key=lambda item: item[1][2], reverse=True)
i = 1
for item in Final_Score_Rank:
hdr_cells = table_4.rows[i].cells
hdr_cells[0].text = u'%s' % item[0]
hdr_cells[1].text = u'%s' % round(item[1][0], 2)
hdr_cells[2].text = u'%s' % round(item[1][1], 2)
hdr_cells[3].text = u'%s' % round(item[1][2], 2)
hdr_cells[4].text = u'%s' % round(item[1][3], 2)
i += 1
# 保存文件
length = len(self.filepath1)
for i in range(length - 1, -1, -1):
if ( self.filepath1[i] == '/'):
break
savepath = u""
for j in range(0, i + 1):
savepath += self.filepath1[j]
# file_extension=u".docx"
savepath = savepath + u'测试.docx'
print savepath
self.document.save(savepath)
# file1 = askopenfilename()
if __name__ == '__main__':
root = Tk()
app = App(root)
root.mainloop()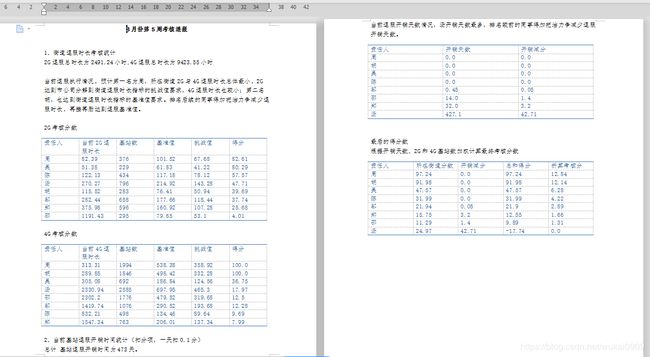
之前得花2个小时的考核分析,现在只需要40秒就可以完成。
本程序后续的改进内容为自动加载写入EMAIL,并自动发送给相关人员。