Suricata规则编写——HTTP关键字
1.简介
之前的常用关键字中介绍了content以及许多修饰它的关键字,除此之外,http协议中还有一些修饰content的关键字,也是由于http协议使用量较大,关键字较多,因此单独拿出来学习。参考:HTTP协议-维基百科。
2.Request和Response
http协议包括了http request和http response数据包。通常,由HTTP客户端发起一个request请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如”HTTP/1.1 200 OK”,以及返回的内容,如请求的文件、错误消息、或者其它信息。
2.1 http request
http request请求包括请求行、请求头、空行和内容。一个普通的request请求如下:

红框部分是请求行,GET表示http method,除了GET还有POST,PUT,HEAD等;后面的/webshell/c99_locus7s.php则是http uri;HTTP/1.1则是版本,可以是0.9、1.0和1.1。绿框部分是请求头,也就是http head,除了HOST字段必须要有,其余字段都是可选的。蓝框部分是空行,只允许有\r\n。由于这个包是GET方法,因此没有内容,如果是POST等方法后面会跟上内容。
2.2 http response
http response应答包括应答行,头部,空行和内容,整体结构和request差不多,下图是针对上节request的应答包:

红框部分,HTTP/1.1是http版本,后面的200是返回的状态码,OK是状态信息。绿框部分是http header,蓝框部分则是返回的html页面,也就是结果。
3.HTTP关键字
3.1 http_method
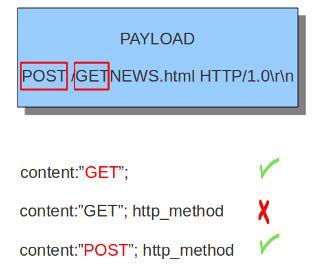
http_method是content的修饰符,表示其所修饰的content只匹配http method部分。http可以使用的方法包括:GET, POST, PUT, HEAD, DELETE, TRACE, OPTIONS, CONNECT和PATCH。下面这个例子匹配GET方法,无论是否加http_method都能匹配:

但是下面这种情况就必须加http_method关键字,因为在http的uri部分也有GET:
3.2 http_uri和http_raw_uri
http_uri和http_raw_uri这两个关键字都是说明所修饰的content是用来匹配http uri部分的内容。所不同的是http_uri指在匹配之前先对URI进行标准化,所谓的标准化就是对数据包中的uri按照RFC文档规定进行一定的转化,包括保留语义转化、一般保留语义转化、改变语义转化。保留语义转化有以下几种,详细的解释参考URL标准化-维基百科:
将url中的协议、域名等转化为小写,比如HTTP://www.Example.com/ → http://www.example.com/
将以%开头的转义字符中的字母转化为大写,比如http://www.example.com/a%c2%b1b → http://www.example.com/a%C2%B1b
将以%开头但在可见字符范围内的进行转化,比如http://www.example.com/%7Eusername/ → http://www.example.com/~username/
移出默认的端口号,比如http对应的80端口而http_raw_uri则是直接对uri进行匹配。下面这两个关键字用法的一个例子:

3.3 uricontent
uricontent的作用和http_uri相同,都是匹配uri部分的,不同的是uricontent可以独立使用,相当于content+http_uri的效果。但是官方文档里说明这个关键字已经被弃用,但目前还对其进行支持。

3.4 http_header和http_raw_header
和http_uri一样,http_header也是只匹配http的header部分的内容(不包括cookie),http_raw_header则是匹配没有标准化过的header(参考HTTP header),简单来说就是标准化的header在每个字段的结尾\r\n之前都会去掉其余的空白字符。两个简单的例子:

3.5 http_cookie
http_cookie从http_header中独立出来,但其使用方法和前几个关键字并无区别,这里就直接贴出例子了:

3.6 http_user_agent
http_user_agent用于匹配http的User-Agent字段的内容,它是http_header的一部分,但是把它单独拿出来说明其出现的频率比较高,用法与前几个没什么差别。关于http_user_agent和http_header的性能对比可以参考Suricata http_user_agent vs http_header,得出的结论是http_user_agent比http_header要快大约10%,除此之外规则中使用http_user_agent的可读性也比较好。例子如下:

3.7 http_client_body和http_server_body
使用了这两个修饰符的content表示只匹配http包中的内容部分,前者值匹配request包,而后者只匹配response。用法很简单:

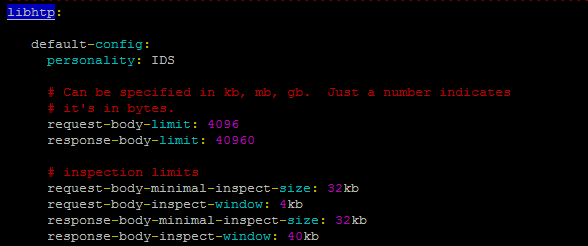
需要注意的是suricata会根据suricata.yaml配置文件中的libhtp小节对于这两部分长度限制来进行匹配,也就是说如果想要匹配的内容在数据包中的长度超过了配置文件中的数值,则这条规则不会被匹配到。目前自己的配置如下,由于需要检测webshell大马,所以这里的response部分的值为40KB,而request则维持原来的默认配置:
3.8 http_stat_code和http_stat_msg
这两个content修饰符分别匹配response应答包返回的状态码和状态信息,例子如下:


3.9 file_data
file_data的作用和http_server_body差不多,都是使content匹配response body中的内容,唯一不同的是使用了file_data关键字的规则,其在file_data之后的content都会受到它的影响。比如下面这条规则,值为”abc”和”xyz”的content都必须在response body里面匹配:
alert http any any -> any any (file_data; content:"abc"; content:"xyz";)3.10 urilen
urilen关键字用于匹配http uri部分的长度,可以使用<和>运算符,下面是几个例子:
urilen:1; uri长度为1字节
urilen:>1; 大于1字节
urilen:<10; 小于10字节
urilen:10<>20; 10字节和20字节之间
除此之外还可以在后面指定是否以raw uri计算长度,下面表示以raw格式来计算的uri长度不超过5字节:
urilen:<5,raw;4.小结
HTTP协议的检测规则在所有规则中占有非常大的比例,比如2014年的bash破壳漏洞、2015年初的glibc ghost针对wordpress的攻击都可以利用http数据包。同时因为他也比很多其他规则要复杂,因此关键字也更多,不过这些关键字用法大部分比较简单,掌握起来也会比较容易。
参考链接
https://redmine.openinfosecfoundation.org/projects/suricata/wiki/HTTP-keywords#HTTP-keywords
http://zh.wikipedia.org/wiki/%E8%B6%85%E6%96%87%E6%9C%AC%E4%BC%A0%E8%BE%93%E5%8D%8F%E8%AE%AE
http://tools.ietf.org/html/rfc2616
https://redmine.openinfosecfoundation.org/projects/suricata/wiki/HTTP-uri_normalization
http://en.wikipedia.org/wiki/URL_normalization
https://lists.openinfosecfoundation.org/pipermail/oisf-users/2011-October/000935.html
http://blog.inliniac.net/2012/07/09/suricata-http_user_agent-vs-http_header/