Kaggle初体验-机器学习之泰坦尼克号乘客生存预测(上)
学习数据分析也有段时间了,都只是使用一些简单图表来分析数据,本周将开启全新的学习旅程:机器学习(^_^偷笑)。
本次通过Kaggle所举办的泰坦尼克挑战赛 来机器学习分析并预测某一乘客的生存或死亡。Kaggle提供两部分数据,训练数据(train.csv)和测试数据(test.csv),我们通过对训练数据分析,构建一个模型,并用这个模型来加载预测数据,分析test.csv表中乘客生存或死亡。最后将分析结果导出提交到Kaggle上,Kaggle能根据你提交的数据评判得分并进行排名。
这是我提交的结果:

PS:如何使用Kaggle请看这里
泰坦尼克号首航中与一座冰山相撞,事故造成2224名乘客和机组人员中的1502人死亡。大面积伤亡的原因之一是船上没有足够的救生艇供乘客和船员使用。尽管在沉船事故中幸存下来的人有一些运气成分,但有些人会比其他人更容易存活。
那么什么样的人在泰坦尼克号事件中更容易存活?
所以接下来,就是分析的过程了。
工欲善其事,必先利其器。所以按照惯例,我们先盘点下将使用到的工具
- Pandas Numpy
数据处理- Matplotlib、seaborn
数据可视化- sklearn
机器学习和预测建模- Jupyter Notebook
分析利器(也是本文写作的工具)
本次分析过程分为两部分进行,一是常规分析,二是机器学习分析。
直接去下篇:https://blog.csdn.net/wuzlun/article/details/80190331
# 导入本次用到的工具
# 使用该魔法,不用写plt.show()
%matplotlib inline
import warnings
# 忽略警告提示
warnings.filterwarnings('ignore')
warnings.filterwarnings('ignore', category=DeprecationWarning)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# seaborn作为matplotlib的补充及扩展
import seaborn as sns 一、常规分析
通过对训练数据(train.csv)简单的分析,得出结论。
# 导入训练数据
data = pd.read_csv('./data/train.csv')
# 查看数据大小
# data.shape
print('训练数据有',data.shape[0],'行,',data.shape[1],'列')
# 观察数据结构,返回前6行
data.head(6)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
表格说明
- PassengerId: 乘客编号
- Survived:是否生存,也是我们分析目标。1表示生存,0表示死亡
- Pclass:船舱等级 分1、2、3等级,1等级最高
- Name:乘客姓名
- Sex:性别
- Age:年龄
- SibSp:该乘客一起旅行的兄弟姐妹和配偶的数量(同代直系亲属人数)
- Parch:该和乘客一起旅行的父母和孩子的数量(不同代直系亲属人数)
- Ticket:船票号
- Fare:船票价格
- Cabin:船舱号
- Embarked:登船港口
S=英国南安普顿Southampton(起航点)
C=法国 瑟堡市Cherbourg(途经点)
Q=爱尔兰 昆士敦Queenstown(途经点)
知道了数据的一些特征,我们再看下数据的完整性。
# 数据描述
data.describe()| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
上表中看到年龄(Age)列只有714行,缺失了105行。所以我们要对缺失值进行处理。
考虑到年龄最小值是0.42,最大值80,这里用中位数填充缺失值,因为中位数不受极端变量值的影响。
# 年龄缺失值处理
data['Age']=data['Age'].fillna( data['Age'].median()) # 用中位数填充
# data['Age']=data['Age'].fillna( data['Age'].meann()) # 用平均数填充
# 再次查看数据完整性
data.describe()| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 891.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.361582 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 13.019697 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 22.000000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 35.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
现在数据就比较完整了,接下来开始一些简单分析。
首先查看下哪个特征相关性最大
# pearson相关系数
data.corr()| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.034212 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.064910 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.339898 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.034212 | -0.064910 | -0.339898 | 1.000000 | -0.233296 | -0.172482 | 0.096688 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.233296 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.172482 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096688 | 0.159651 | 0.216225 | 1.000000 |
看以看到船舱等级(Pclass)绝对值最高,船票(Fare)次之,Parch第三,Age第四
pearson相关系数只能查看数据类型的描述统计信息,对于其他类型的数据不显示,所以还要加上特征,性别(sex)、名字(Name)
# 添加死亡标签
data['Died'] = 1 - data['Survived']船舱等级(Pclass)与存活关系
# 按船舱等级(Pclass)分组,再汇总
data.groupby('Pclass').agg('sum')[['Survived', 'Died']].plot(kind='bar', figsize=(10, 6),stacked=True, colors=['g', 'r'])
plt.title('船舱等级与存活关系')
plt.xlabel('船舱等级')
plt.ylabel('人数')
plt.legend(['生存', '死亡'], loc='upper left')
船票价格(Fare)与存活关系
# 按船票价格(Fare)分组,再汇总
figure = plt.figure(figsize=(8, 6))
plt.hist([data[data['Survived'] == 1]['Fare'], data[data['Survived'] == 0]['Fare']],
stacked=True, color = ['g','r'],
bins = 50, label = ['生存','死亡'])
plt.title('船票价格与存活关系')
plt.xlabel('船票价格')
plt.ylabel('人数')
plt.legend();
家庭成员数与存活关系
# 家庭人数 = Parch+SibSp+自己
figure = plt.figure(figsize=(8, 6))
plt.hist([data[data['Survived'] == 1]['Parch']+ data[data['Survived'] == 1]['SibSp']+1,
data[data['Survived'] == 0]['Parch']+data[data['Survived'] == 0]['SibSp']+1],
stacked=True, color = ['g','r'],
bins = 50, label = ['生存','死亡'])
plt.title('家庭成员数与存活关系')
plt.xlabel('家庭成员数')
plt.ylabel('人数')
plt.legend();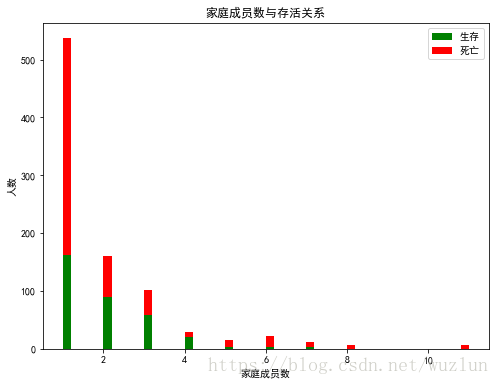
# 家庭成员数与生存的关系
data.groupby('Parch').agg('mean')[['Survived', 'Died']].plot(kind='bar',
stacked=True, colors=['g', 'r'])
data.groupby('SibSp').agg('mean')[['Survived', 'Died']].plot(kind='bar',
stacked=True, colors=['g', 'r'])
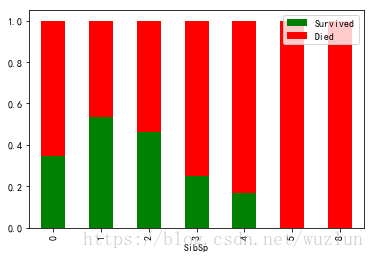
乘客年龄与存活关系
fig = plt.figure(figsize=(10, 6))
sns.violinplot(x='Sex', y='Age', hue='Survived', data=data,
split=True,palette={0: "r", 1: "g"} )
plt.title('乘客年龄与存活关系')
plt.xlabel('性别')
plt.ylabel('年龄')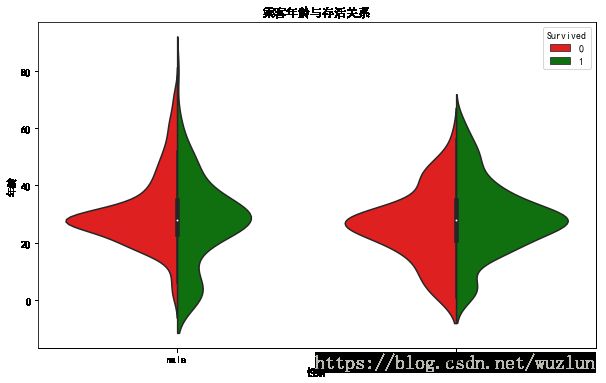
性别与存活关系
# 按性别(Sex)分组
data.groupby('Sex').agg('mean')[['Survived', 'Died']].plot(kind='bar', figsize=(10, 6),
stacked=True, colors=['g', 'r'])
plt.title('性别与存活关系')
plt.xlabel('性别')
plt.ylabel('比例')
分析了各个特征与生存的关系,我们再综合几个特征看下。
年龄、船票价格与存活关系
# 圆的大小表示票价的高低
plt.figure(figsize=(14,7))
ax = plt.subplot()
ax.scatter(data[data['Survived']==1]['Age'], data[data['Survived']==1]['Fare'], c='g', s=data[data['Survived']==1]['Fare'])
ax.scatter(data[data['Died']==1]['Age'], data[data['Died']==1]['Fare'], c='r', s=data[data['Died']==1]['Fare'])
ax.set_xlabel('年龄')
ax.set_ylabel('船票价格')
ax.set_title('年龄、船票价格与存活关系')
# 按船舱等级分组
data.groupby('Pclass').agg('mean')['Fare'].plot(kind='bar', figsize=(10,6))
plt.title('船舱等级与船票价格关系')
plt.xlabel('船舱等级')
plt.ylabel('平均船票价格')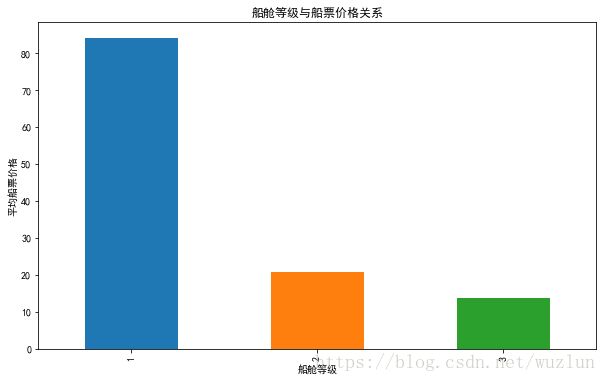
通过对各个特征分析,我们可以得出以下几个结论:
- 船票价格高的,也就是舰艇等级高的存活率高。
- 女性比男性存活率高。
- 小孩(10岁以下)和老人(50岁以下)存活率比青壮年比例高。
- 购买高票价的人主要集中在15-50岁这个区间。
- 家庭成员数2-4个人的存活率高于其它家庭情况。
由此,我们可以得出,幸存下来的人不仅仅是运气好。还和他们的经济能力、社会地位、年龄、家庭情况等密切相关。那么现在我给你一个乘客的资料,能判断他或她的生存或死亡吗,很遗憾的告诉你,不能。
为什么?之前我们做的都是无用功了吗?骚年,别急。来,喝口茶,我们继续分析。
# 看下表的结构
cols = data.columns
print(cols)
print('该数据特征总个有:',len(cols))Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked', 'Died'],
dtype='object')
该数据特征总个有: 13
简单看下该数据有13个特征,去掉PassengerId、Survived也还有11个,而船票价格不同,船舱又分3个等级,性别分男女,家庭成员数及组成,乘客的起始点又不相同等等。可以看出,特征很多,而特征中又包含特征,纬度太高,所以不知道哪个权重比较大,所以就更不能判断生存情况了。
那么有什么办法操作呢,那就是利用特征分析,来进行特征选择,降低纬度。这就是机器学习分析的范畴了。
接下来我们开始第二部分的分析。
下篇链接:https://blog.csdn.net/wuzlun/article/details/80190331