hadoop2.3.7新加结点相关问题汇总
现有Hadoop集群新加结点流程及问题汇总
一、引言
说明:本文是在hadoop集群基本部署完成后,后续新加结点过程中的总结。
此时,集群所含机器已配置完成一定文件(即master1,master2,slave等多个结点中已部署好一定配置信息,如jdk,hadoop,ssh等信息),具体配置流程可参见hadoop集群配置方法。
tips:
- master1上配置好的hadoop所在文件夹/home/hadoop2.7,已经复制到master2和所有的slave机器的/home目录下;
- 已在/usr/java目录下安装java,且已配好环境变量;
- 所有机器已完成从master1结点发起的ssh无密码登录配置;
- 已配置好hadoop环境,包括但不限于core-site.xml,hdfs-site.xml,marped-site.xml,yarn-site.xml等配置文件;
本文总体分为两个部分:
- 新加流程
主要从新加结点的每个流程展开叙述,完成在成熟的hadoop2.3集群中新加一个salve结点22的整个步骤,包括每一步的内容以及相关截图。主要叙述重点部分,提出所需的相关命令,具体的细节使用需要提前掌握;
2. 问题分析
主要从新加结点中遇到的各种问题展开,列出来遇到的错误和实际解决时采用的方法以及部分参考资料。
二、新加结点流程(slave22)
- 修改hosts文件
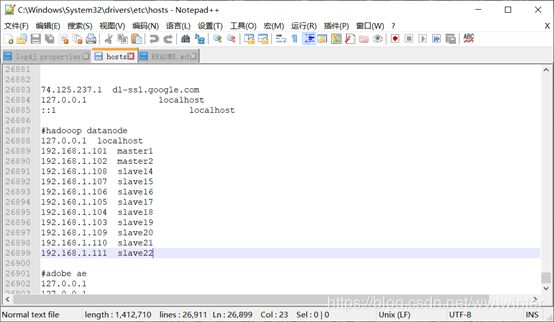
a.master1结点上,在/etc/hosts目录文件中,插入需要新加的结点的ip信息,如:192.168.1.111 slave22
| 更改前的hosts |
| 更改后的hosts |
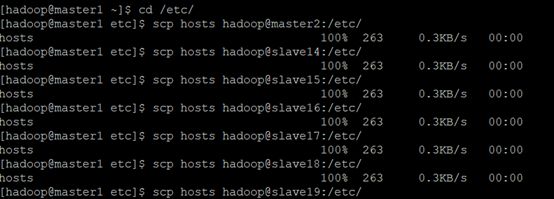
b.将其他所有结点的hosts文件(相同目录位置下)更改为相同的信息,此处使用scp命令可以从master1结点上将相关文件远程传递到对应的结点上,不需要每次都登录到相应结点手动修改。
c.打开需要新加的slave22结点的主机,设置网络参数,将ipv4地址修改为192.168.1.111,修改DNS和网关信息,具体可实际查询集群中结点的配置,保持相同即可。
2.修改/home/hadoop2.7/etc/hadoop中的slaves文件
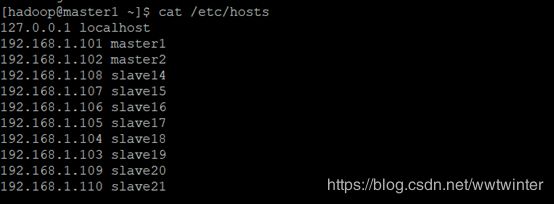
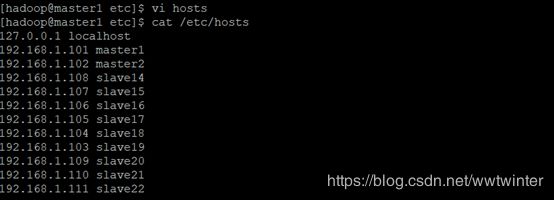
a.修改master1结点上的slaves文件信息
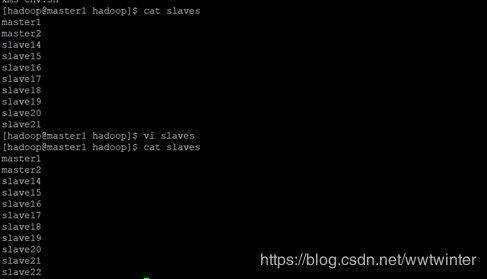
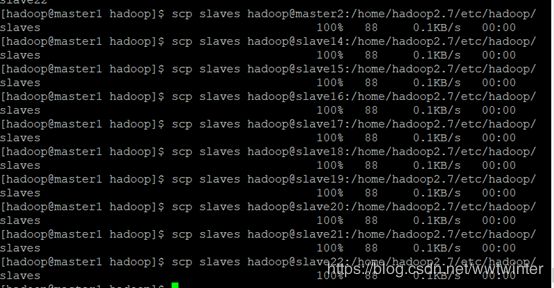
b.利用scp命令将其余所有结点的slaves更改
3.修改/home/hadoop2.7/dfs/data/current文件夹中的VERSION文件
a.利用scp命令将master1结点的VERSION文件传到slave22对应文件夹中
![]()
这一步是为了保证每个结点的clusterID 都相同。
b.改掉storageID和 datanodeUuid,和前面的不一样就可以,新增这两个id为*****9c
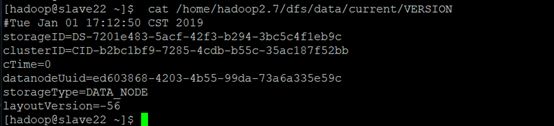
这一步是为了保证每个结点的storageID和 datanodeUuid 都与其他结点不同。
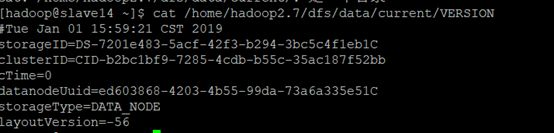
tips:从slave14-slave22,这个结点id可以随便取值,为了方便,统一把从master1结点scp过来的信息后两位取为如下:
| master2:0c |
slave14:1c |
slave15:2c |
slave16:3c |
| slave17:4c |
slave18:5c |
slave19:6c |
slave20:7c |
| slave21:8c |
slave22:9c |
master1:cc |
|
|
|
|
|
|
可对应下图slave14的VERSION文件信息理解:
| Slave14: VERSION信息 |
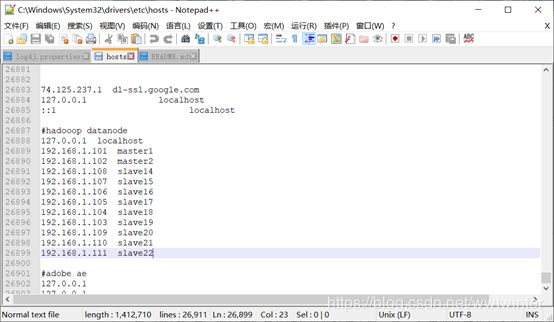
4.修改本地hosts文件
在C:\Windows\System32\drivers\etc目录下直接添加对应结点(slave22)的ip就可以,这一步是为了能在web页面实现正常下载
5.重新启动hdfs系统
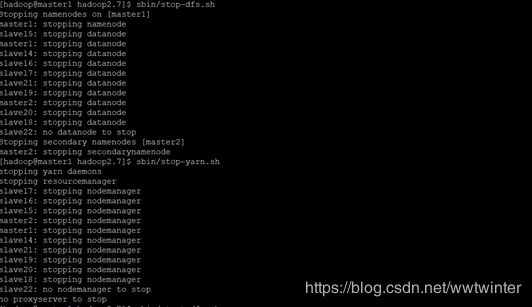
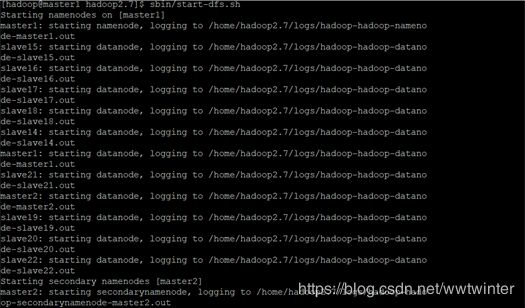
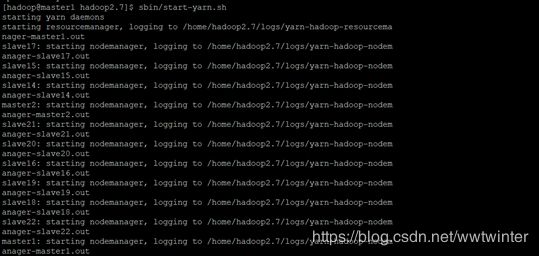
在master1结点上,进入/home/hadoop2.7路径下,先后执行下述命令
![]()
sbin/stop-dfs.sh
sbin/stop-yarn.sh
sbin/start-dfs.sh
sbin/start-df.sh
6.检查
运行jps命令,检查以下各项是否都已启动

7.总览
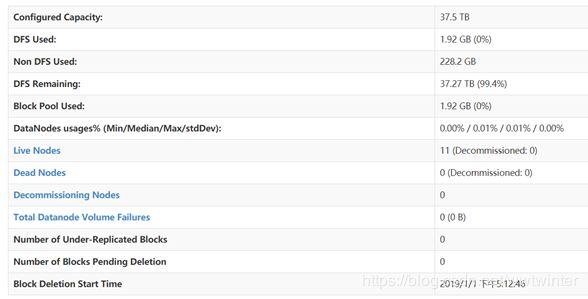
如图所示信息可以在web页面的Overview页面查看,hdfs系统的默认访问地址为:http://namenode的ip:50070,按顺序主要包含以下几个信息:
- Configures Capacity配置容量:配置的共有37.5TB;
- DFS Used分布式文件已用容量:已用1.92GB,主要是上传到hdfs系统中的文件,由于hdfs采用3副本机制,所以容量会相应多一些;
- Non DFS Used非分布式文件占用容量:已用228.2GB,目前主要是linux系统文件的占用;
- DFS Remaining分布式文件可用容量:还有37.29TB可用;
- Block Pool Used块池已用容量:已用1.92GB
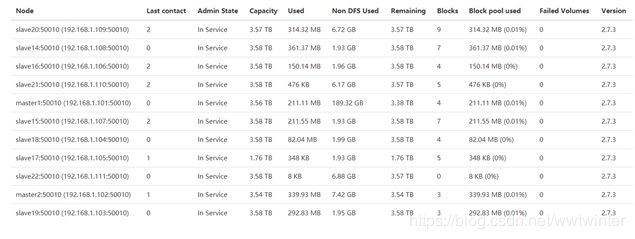
如图所示信息可从web页面的datanode信息查看,目前共有从192.168.1.101--192.168.111共11个结点,图包含了结点名称,ip信息,服务状态,容量,已用,不属于分布式文件的占用,剩余容量,版本信息等。
二、遇到的问题
1.Q:连接了网线,不能ping通
A: 需要在对应的主机上做配置
1)打开slave22主机,手动将ipv4修改为192.168.1.111
2)关闭防火墙 systemctl stop firewalld.service,可使用systemctl status firewalld.service查询防火墙状态,若为下图所示,则防火墙已关闭

2.Q:web页面上namenode information页面,Datanode中没有新加结点的信息,putty中使用jps命令也查询不到datanode的正常启动
A:VERSION文件没配好,此文件中的clusterID需要和namenode的对应信息相同,同时,storageID和 datanodeUuid不能相同,可使用scp命令把master1的相应信息传递到其他结点,然后分别编辑storageID和 datanodeUuid使不同即可。
3.Q:结点出问题解决思路
A:关于namenode、datanode的问题尽量看日志解决,在logs目录下(/home/hadoop2.7/logs),一般是**.log文件,下拉到最后看报错信息即可
也可在webnamenode information页面中的logs查看,datanode的问题就找datanode.log,如下图:

4.Q:namenode无法正常启动,hdfs dfsadmin -report指令和网页namedode information均看不到信息
A:1)查阅logs目录下的hadoop-hadoop-namenode-master1.log日志信息,发现是文件权限不够

2)将current文件夹权限更改为777(tips:此处如果只更改文件夹中VERSION 的权限会导致后面出现地址占用、namenode元数据被破坏却无法修复等一系列问题)
5.Q:Datanode无法正常启动,不知道原因
A:查阅logs目录下的hadoop-hadoop-datanode-master1.log日志信息,发现和clusterID相关
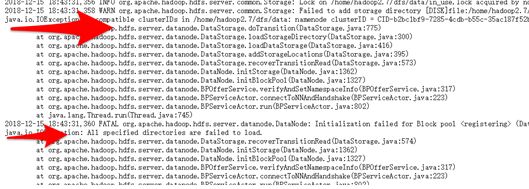
问题出在namenode clusterID与datanode clusterID不同,修改两个值使相同。
参考:https://blog.csdn.net/cc1949/article/details/78467673
tips:此处不能粗暴的只用scp将所有的namenode(master1)的VERSION信息传递到datanode(master2、slave等),如:

这样会使所有的结点VERSION都相同,从而每次寻找结点时只会返回一个结点就认为搜索完毕,表现在每次查询web的结点列表时,只会随机出现一个datanode或者namenode,即每次刷新web页面的node information或者使用命令hdfs dfsadmin -report只会出现一个活跃的结点,其他结点均是关闭状态,因为每个结点的storageID和 datanodeUuid都需要是不一样的,所以手动将其改为不一样的就能解决。
参考:https://blog.csdn.net/yijichangkong/article/details/45438931
6.Q:eclispe中运行弹错:java.nio.channels.UnresolvedAddressException
eclispe中:[Thread-4]WARN org.apache.hadoop.mapred.LocalJobRunner -job_local829894505_0001
java.lang.Exception: java.nio.channels.UnresolvedAddressException
A:1)之前在eclispe中配置hadoop环境出现过此问题,当时的问题在于hadoop连接参数写的是192.168.1.101,需要改为10.15.20.31.
2)现在的问题不一样,出现的症状有:
a.exlispe环境中,上传hdfs文件成功,可在eclispe中打开,也可下载
b.web页面无法下载浏览上传的文件,有时候可以下载,有时候拒绝访问
c.systemctl status firewalld.service重新检查了所有节点的防火墙,全是died,并无异常

d.web页面多次实验发现,有时候正常下载,有时候下载失败,成功与否和文件所在的节点有关,当节点正常时可正常下载
3)解决:本地windows上需要修改hosts文件信息,之前运行eclispe可能自动修改过一部分hosts,把部分结点的ip信息写入到了hosts文件中,所以当信息存储在这些结点上时,在web界面就能正常下载,由于hadoop使用3备份的模式,当文件的执行下载命令时,会随机地跳转到存储的一个结点,当这个顺序跳转到一个不能正常下载的结点时,下载就会出现错误。
修改路径,C:\Windows\System32\drivers\etc
修改方法,直接添加需要通过windows访问的结点的ip地址即可