Python 爬虫实战 4
目录
Requests 模块
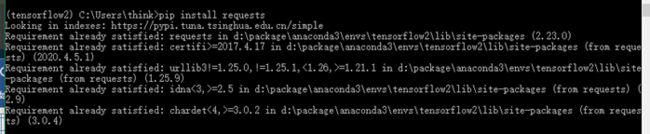
安装 Requests 模块
项目:用 requests 实现云栖社区博文爬虫实战
分析过程
编写代码
爬取结果
Scrapy 模块
安装 Scrapy
配置 pywin32
Scrapy 指令实战
(1)创建爬虫项目
(2) 进入新建爬虫项目,用爬虫模板创建一个爬虫项目:scrapy genspider -t basic fst shuqi.com
(3)运行爬虫文件:scrapy crawl fst
Scrapy 爬虫项目编写基础
项目:爬取阿里文学首页的书名
打开网址,查看分析,找出正则表达。
开始编写 fst.py 爬虫文件
项目:使用 Scrapy 编写当当网商品数据爬虫实战
创建项目 - 编写 items.py – 编写爬虫文件 – 编写pipelines – settings - 运行
运行测试:scrapy crawl dd成功
查看MySQL 的 python_dd 数据库,成功插入,两页一共111个结果
修改搜索页面为100页后运行
附:Pymysql 相关
附:当当网提取关键字的分析:书名、链接、价格、评论
Requests 模块


爬虫最重要的是网页分析+反爬虫措施,而不是技术本身。
安装 Requests 模块
pip install requests
Requests 介绍:
-- Requsts.请求方式:get、post、put……
在 urllib中,要模拟浏览器的话,需要创建opener对象来进行处理。而 requests 统统可以用参数处理。比如,模拟浏览器,等都需要参数完成。
参数:
Params: get请求的相应参数,字典方式存储。
Headers:伪装浏览器要用到,需要添加头信息,字典方式存储
Proxies:添加代理,字典方式存储,可以放置{协议名:代理IP}
Cookies:
Data:post请求中发过去的数据。
属性:
Text:decode之后的响应数据
Content:响应数据,(b)类型的流数据
Encoding:调用当前网页的编码
Cookies:当前网页请求的cookies
url:当前请求的url
status_code:当前请求的状态码
实验中,因为python进程占用了端口8888,所以改动fiddler端口名8888为8887.
项目:用 requests 实现云栖社区博文爬虫实战

网址:https://yq.aliyun.com/ , 页面内搜索关键字 “Python”,获得搜索结果的网址:https://www.aliyun.com/ss/?k=Python。
目标:实现自动翻页,并拿到每页的具体博文数据。

不同页面的 url :
第一页:https://www.aliyun.com/ss/?k=Python 或者 https://www.aliyun.com/ss/UHl0aG9u/a/1
第2页:https://www.aliyun.com/ss/UHl0aG9u/a/2/?spm=5176.10695662.1996646101.103.4ebf259fVLSU32
第3页:https://www.aliyun.com/ss/UHl0aG9u/a/3/?spm=5176.10695662.1996646101.104.292d259fyk1e3X
再访问变:https://www.aliyun.com/ss/UHl0aG9u/a/3/?spm=5176.10695662.1996646101.103.364f259f39yYKF
第4页:https://www.aliyun.com/ss/UHl0aG9u/a/4/?spm=5176.10695662.1996646101.105.630f259f7Bkyml
第五页:https://www.aliyun.com/ss/UHl0aG9u/a/5/?spm=5176.10695662.1996646101.103.2285259fCWKkmz
测试:spm后面的参数去掉,看能不能访问。发现可以,所以该参数无关紧要,重要的是 “a/” 后面的数字。
测试:https://www.aliyun.com/ss/?k=Python/a/2。 发现可以访问,可以猜到UHl0aG9u是关键词python的编码变换。
分析过程
搜索结果的页面数量:

页面数量正则表达式提取:
pat1 = '共有(.*?)页' # 一共多少页每一页的 url 链接:
# 每页的链接 = url+page number
url = "https://www.aliyun.com/ss/UHl0aG9u/a/" + str(i+1)每一页中单个博文的 url 链接提取:
pat_url = '.*?'
单个博文页面内的信息获取:
(1)文章标题:
pat_title = '(.*?)
' (2)文章内容:
pat_content = '(.*?)'
编写代码
代码流程:同分析流程写代码即可。

爬取结果
文件保存在 "aliPython_Pa"
Scrapy 模块
课程网址:https://edu.aliyun.com/lesson_1994_17794#_17794

安装 Scrapy
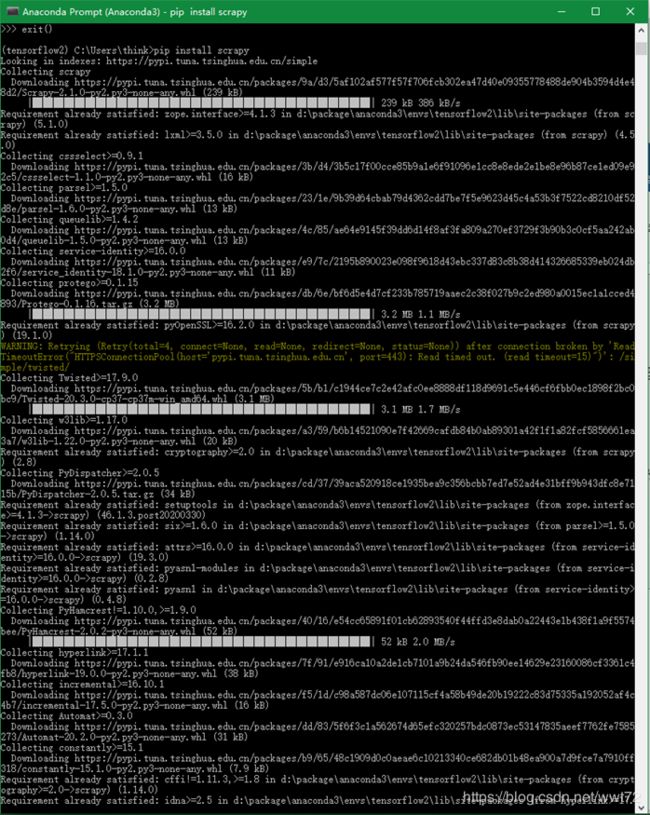
视频中老师的安装流程如下:

我的Python 爬虫项目统一在 tensorflow2 环境下执行。
- 因为我已经安装了 lxml,所以直接安装 “pip install scrapy”
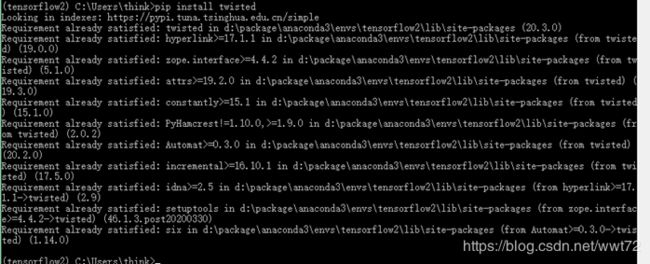
- 中间有显示黄色警告,先不管,后面有问题再解决,再安装下 “pip install twisted“
- 最后 “pip install pywin32” 提示已经安装。
【网络不好请访问下面网址,下载相应 wheel 后 pip 离线安装相关包即可】

安装过程的相关图片如下:

配置 pywin32
因为我是在tensorflow2 环境下安装的,所以进入 tensorflow2 环境进行配置。
1. 目录下搜素 pywin32,打开 pywin32_system32 文件夹,可以看到两个 .dll 动态文件。
比如,我的目录为:“D:\PACKAGE\Anaconda3\envs\tensorflow2\Lib\site-packages\pywin32_system32”


2. 手动复制上面的两个文件到 “C:\Windows\System32” 目录下。


3. OK,完成了 scrapy 安装。
Scrapy 指令实战

startproject 爬虫项目名称
genspider -l # 查看爬虫模板
genspider -t 模板 爬虫文件名 域名 # 创建爬虫
crawl # 运行爬虫
list # 查看有哪些爬虫
(1)创建爬虫项目
新建一个空文件夹 “scrapy_proj_practice”,anaconda Prompt 下激活tensorflow2 环境(自己在哪里安装的在哪里的命令行下运行即可),cd 命令切换到刚刚新建的“scrapy_proj_practice”文件夹。


命令:scrapy startproject ali_first
运行命令后多了一个项目文件夹。

.cfg 是配置文件,不用管。

核心文件夹如下,是一个半成品爬虫文件。
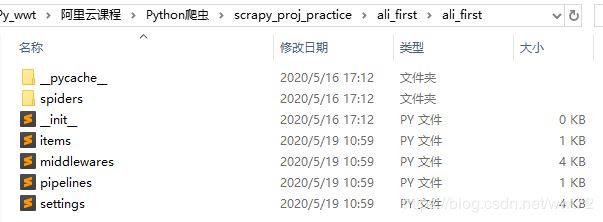

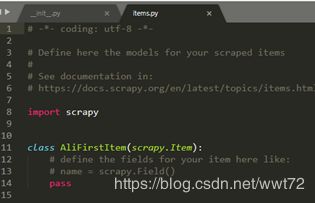
> items.py 定义目标。比如你要爬什么信息,比如要爬文章的标题、内容等,标题和内容就是两个容器,可以放到item中。
> spiders 文件夹 可以放多个自己写的爬虫文件。
> middlewares.py 一个中间件。中间要处理相应东西时,可以编写。
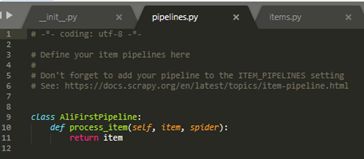
> pipelines.py 主要用于爬后处理。比如,爬取后的东西要写进数据库,会需要相应操作。
> settings.py 设置信息,是整个项目的整体配置文件信息。

(2) 进入新建爬虫项目,用爬虫模板创建一个爬虫项目:scrapy genspider -t basic fst shuqi.com
--进入项目,查看当前项目下有哪些爬虫母版(scrapy genspider -l),看到当前有4个爬虫母版:基础、通用、爬csv文件数据、爬xml数据。
【基于该母版可以很快创建一个爬虫文件】

--基于基础母版创建一个爬虫文件:
scrapy genspider -t basic fst shuqi.com
命令:scrapy genspider -t basic 爬虫文件名 域名
【注意,域名不包括前面的www】
本案例使用阿里文学的域名。

(3)运行爬虫文件:scrapy crawl fst
当前没有任何数据,所以只是走了个流程,没什么实际作用。

查看当前有哪些可用的爬虫文件:scrapy list

更多scrapy 指令查看,比如 bench,check 等,需要的话网上搜索使用。本次指令实战里面展示的都是常用的,基本够用。

Scrapy 爬虫项目编写基础

指令顺序:
- 命令: scrapy startproject ali_first
- 编写 items.py
- 命令: scrapy genspider -t 爬虫母版 爬虫文件名 域名
- 编写爬虫文件
- 编写pipelines,可有可无,建议加上。
- 配置 settings
项目:爬取阿里文学首页的书名
流程:打开网址—>右击查看网页源代码—>Ctrl+F打开搜索框—>搜索其中一个署名—>观察所处位置—>编写正则表达式—>编写代码。
打开网址,查看分析,找出正则表达。
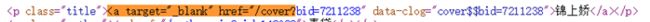



视频中老师用的是, ,只能查找的到 141个(如下图)。推荐目录里面的小说没有算在内。即,上面的2没有包含在内。
需要注意,用XPath时,需要设置两个提取3个提取方式,1、3、4,视频中的老师值写了3的。
本文使用1,2,3,4的模式查找全部的文章,推荐小说和页面小说内容有重复的,之后去重即可。



开始编写 fst.py 爬虫文件
item.py 定义目标 -- 使用/存入定义的容器title – 试运行查看title输出结果。
(1) item.py定义目标:创建 title 容器

(2)fst.py 中使用 title 容器,用xpath 存title。
使用视频种使用的关键词
的XPath表达式,运行测试:scrapy crawl fst
测试结果(部分):

运行发现,并没有我们代码中输出的 “-“*20的横线。
这是因为此时 pipeline的文件还不能运行,因为没有开启,需要在settings.py中全局设置开启。
(3)settings.py全局设置开启 pipeline后运行查看。Pycarm 中 ctrl+F 打开搜索框,在 settings.py 中搜索 Pipeline,去掉注释,开启 pipeline。
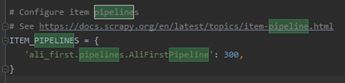
注意:ali_first.pipelines.AliFirstPipeline
名字必须对应正确。
同样地,如果要伪装浏览器,也可以在 settings.py中设置。比如,搜索User-agent 可以设置伪装自己的浏览器。
(4)开启后crawl 命令运行查看,正确运行。

项目:使用 Scrapy 编写当当网商品数据爬虫实战

进入当当网搜索Python,复制链接: http://search.dangdang.com/?key=Python&act=input
转到第二页是:http://search.dangdang.com/?key=Python&act=input&page_index=2
流程如下:
创建项目 - 编写 items.py – 编写爬虫文件 – 编写pipelines – settings - 运行
- scrapy startproject Dangdang
- cd dangdang
- 编写items.py,包括所需爬虫目标。

- scrapy genspider -t basic dd dangdang.com

-
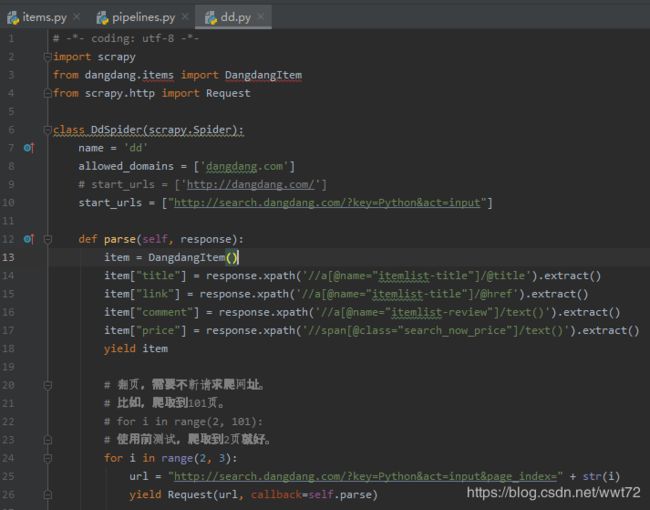
打开 dd.py 编辑,起始网址改为:http://search.dangdang.com/?key=Python&act=input
打开该网站进行分析。分析过程图太多,见后面小节(当当网提取关键字的分析:书名、链接、价格、评论)。
怎么翻页。翻页需要不断请求来爬取网址。
P2: http://search.dangdang.com/?key=Python&act=input&page_index=2
P3: http://search.dangdang.com/?key=Python&act=input&page_index=3
最后一个变化。
-
-
编写 pipelines.py 进行后处理。见后面小节关于pymysql(Pymysql 相关),包括建数据库和建表格。
-
使用mysql 之前,测试下代码输出是否正确。
需要去 settings.py 设置 pipelines 打开。
-

-
运行测试:scrapy crawl dd成功
-
运行结果如下。
-

-
修改dd.py上面,将结果写入数据库表格。运行成像:scrapy crawl dd ,查看结果如下图。

查看MySQL 的 python_dd 数据库,成功插入,两页一共111个结果

修改搜索页面为100页后运行
修改为爬取100页的数据,对之前的插入数据执行,若已经插入,就忽略。
Pipelines.py 添加的代码部分。

成功运行。
再查看SQL里面更新的表格记录,5570个记录,按道理讲应该是每页60*100=6000,可见中间有失败回滚的。

附:Pymysql 相关
pipelines.py 进行后处理时,需要安装 pymysql 包, pip install 即可,安装好了后需要改数据库的源代码,在对应安装环境的目录下,我在 tensorflow2 环境下。

打开 connections.py, ctrl+F 搜索 chaset= , 值填为 ‘utf8’, 防止乱码。
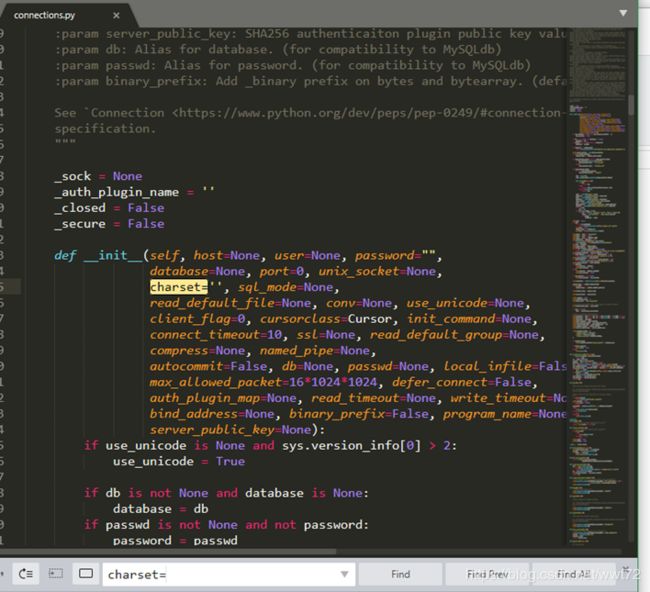

此时需要开启MySQL,我之前已经安装了,直接开启就好。如下图。

进入mysql 命令: mysql -uroot -p
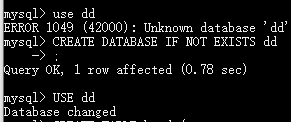
创建当当数据库 dd
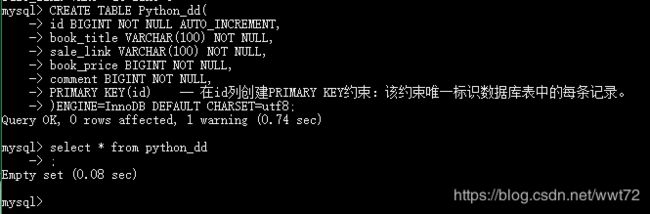
创建Python书籍售卖表格 Python_dd
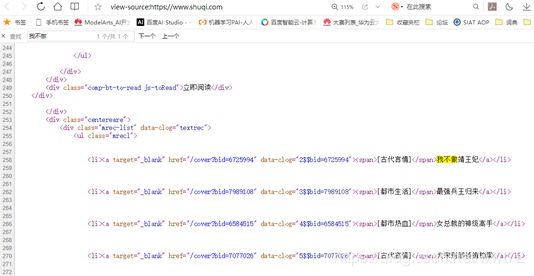
附:当当网提取关键字的分析:书名、链接、价格、评论
P1:源代码页搜索,“Python编程 从入门到实践“

P1:源代码页搜索,“Python编程 从入门到实践“,3个结果,定义为 title

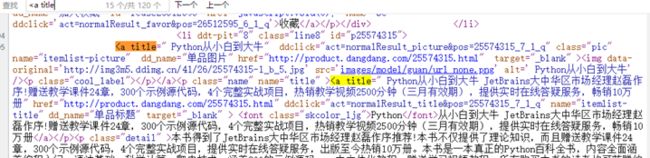
怎么区分第一个和第二个? -- 用属性区分,本文用第二个。
顺便也发现链接同样在此处,不用找了,就是 href属性。
接下来找评论,就找第一个商品的搜索29506。
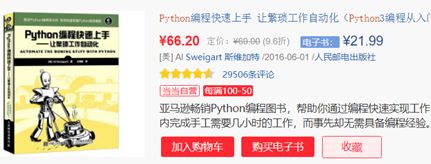

所在代码区域为复制文本为:

同样地,查找第一个的商品价格。

定位为,如下图,60 个全部正确查找。
¥66.20

定位为,如下图,60 个全部正确查找。
¥66.20
