HBase的架构原理(7大组件)图文详解及其与Hive的区别
目录
一、如何理解HBase
二、HBase与Hive、Hadoop的区别
1. 从概念上区分
2. 从应用场景上区分
3. 从数据库角度来看
4. 小结
三、HBase的详细架构
1. HBase与HDFS和Zookeeper的关系
2. 两个核心节点HMaster和HRegionServer
3. HLog
4. HRegion
5. Store
6. 存储工具Mem Store和StoreFile
四、HBase读写过程总结
一、如何理解HBase
关于HBase比较官方的解释就是:
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,它的目标是存储并处理大型的数据,HBase技术可在廉价的PC Server上搭建大规模结构化存储集群。
高可靠性:因为HBase的存储基于HDFS,有数据备份
高性能:依托于Hadoop分布式平台,实现分布式计算,速度快
面向列:HBase是一个Nosql型数据库,通过列式存储的方式存储数据;对比mysql是行式存储
可伸缩:分布式集群,可扩展,增删工作节点方便
ps:行式存储和列式存储的区别:一分钟搞懂行式存储和列式存储
(1)行式存储,若某一个数据不存在,默认会是null或0,依然占用内容;
列式存储,若某个数据不存在,直接为空;
(2)例如表的数据一共5行x10列,现在需要读取指定某3列的数据:
行式存储,需要读取5行,10列数据全被读取到;
列式存储,读取数据时按列读取,只需要读取指定的3列数据即可;
列式存储的主要优点之一就是可以大幅降低系统的I/O,尤其是在海量数据查询时,而I/O向来是系统的主要瓶颈之一。
二、HBase与Hive、Hadoop的区别
附:Hive的概念、原理及其与Hadoop和数据库关系
1. 从概念上区分
(1)HBase是一种Key/Value分布式存储系统,它依托于Zookeeper和HDFS;
HBase在自身数据库上实时运行,并不运行MapReduce;
HBase分区成表,表被分割成列族,列族将某一类型的列集合在一起查询,
每一个Key/Value在HBase中被定义成一个cell,cell是一个字节数组,{key , value}key包括rowkey、列族、列和时间戳,value是行的具体数据;
在HBase中,行是key-value映射的集合,这个映射通过rowkey唯一标识。
HBase启动前,需要群起Zookeeper和HDFS。
(2)Hive是一个构建在Hadoop基础设施之上的数据仓库,它基于MapReduce、HDFS和YARN;
Hive将HQL语言封装成对应的MapReduce程序,通过HQL语言查询存放在HDFS上的数据;
实际上是将HQL翻译成对应的封装好的MapReduce程序,运行,从而查询HDFS中的数据;
Hive在调度资源时,需要用到Yarn框架;
Hive启动前,需要群起HDFS和YARN。
2. 从应用场景上区分
(1)mysql适合处理实时动态数据的增删改查;
(2)Hive用来做对数据库的数据分析,适合处理离线静态数据的分析查询,不适合实时查询;
(3)HBase适合进行大数据的实时查询。
3. 从数据库角度来看
关系型数据库(SQL型数据库):Mysql,Oracle
非关系型数据库(NOSQL型数据库):Redis,MongoDB,HBase
类SQL数据库:hive
关系型数据库和非关系型数据库,以及hive数据仓库的区别
4. 小结
(1)Hadoop是基础框架,Hive和HBase是两种基于Hadoop的不同技术,
Hive是一种类SQL的数仓工具,本质是对MapReduce的HQL封装,运行MapReduce任务,适合对数据库中静态数据作数据分析,
HBase是一种依托于Hadoop的Nosql型数据库,以key-value存储,适合对大数据进行实时查询。
(2)Hive和HBase并不矛盾,可以同时配合使用,前者进行统计查询、后者进行实时查询;
(3)Hive中的数据可以写入HBase,HBase中的数据也可以写入Hive。
三、HBase的详细架构
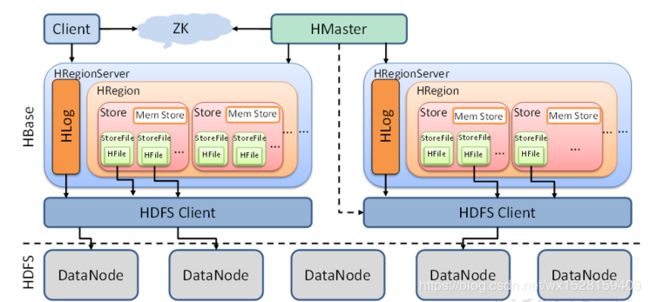
最底层是HDFS集群,之上是HBase集群,ZK是Zookeeper集群,Client是访问HBase的客户端
1. HBase与HDFS和Zookeeper的关系
(1)HBase的元数据和表数据,最终存储在HDFS中;
同时HDFS数据多副本的特性,为HBase保证了高可靠性和高可用性;数据丢失后可以通过保存在HDFS上的HLog恢复数据。
(2)HBase依托于Zookeeper,Zookeeper进行Master的高可用、RegionServer的监控、Client访问入口和集群配置的维护等工作:
通过Zookeeper保证集群中只有一个HMaster运行,如果HMaster异常,通过选举机制重新选出新的Master;
通过Zookeeper监控RegionServer的状态,当其有异常时,通过回调形式通知Master,让Master处理异常;
通过Zookeeper存储元数据的统一入口地址。
2. 两个核心节点HMaster和HRegionServer
(1)HMaster:管理整个集群,保存集群的元数据信息,掌管每张表、数据在哪一台服务器存储,同时元数据信息会在Zookeeper上备份;类似HDFS中的NameNode。
Master节点的作用:
① 为任务量小的RegionServer分配Region,实现集群的负载均衡;
② 维护集群中,表的元数据信息
③ 发现失效的Region,指挥RegionServer将失效的Region分配到正常的RegionServer上;
④ 当RegionServer挂掉后,协调RegionServer将HLog进行拆分,分给剩余正常的RegionServer,故障转移。
(2)HRegionServer:一个RegionServer就是一台实际的服务器,也是进行实际操作的节点,它维护了很多表;类似HDFS中的DataNode。
RegionServer节点的作用:
① 管理Master分配的Region;
② 处理来自Client的读写请求;
③ 和底层的HDFS交互,存储数据Flush到HDFS中;
④ 负责Region变大之后的拆分;
⑤ 负责StoreFile的合并工作,防止小文件过多。
在启动HBase进程时,需要启动Master节点和RegionServer节点。
3. HLog
HLog即Write-Ahead logs(WAL),是HBase的修改记录,即编辑日志,保存在HDFS中;
类似HDFS中的Edits文件,由于HDFS的多副本机制,数据丢失后,数据可以依靠HLog来恢复;
当对HBase读写数据时,数据会先写入MemStore的内存中,速度快,但是内存容易发生数据丢失;为了解决这一问题,数据会先写入WAL(HLog)中,再写入MemStore内存中,系统故障后,数据可以通过HLog来恢复。
4. HRegion
一台服务器RegionServer上有一个大表,HBase会根据RowKey(字节码文件类型)值进行水平切分,分成多个Region;
当数据量小的时候,表还没有分片,此时一个Region就是一个table;
当数据增大,需要对表进行水平切分和垂直切分,切分后一个分片就是一个Region;
从结构图上也可以看出,一个RegionServer(服务器)可以包含多个Region(表的分片)。
Region是水平切分出来的,Store列族是垂直划分的;
一个Region中包含多行,每一行对应一个rowkey
5. Store
Store是列族,它是多个特定列的集合,一个完整的表可以有多个列族;
当数据量较小,表没有切分的时候,一个表就是一个Region,一个列族就是一个Store;
当数据量增多,表进行水平切分,一个列族对应的Store也会进行水平切分,这样一个列族就会包含多个垂直上的Store。
水平来看,一个纵向的Store就是一个列族;
垂直来看,一个列族包含纵向上多个Store。
一个列族Store,对应硬盘上的一个文件夹,所以说hbase是面向列存储的,key-value形式的数据库。
在查询数据时,hbase首先根据row-key找到对应的region,然后再根据需要的列族Store,到硬盘上找到对应的文件夹(Store)读取数据。
6. 存储工具Mem Store和StoreFile
(1)Mem Store
Mem Store是一个内存级别的存储,一个列族Store对应一个Mem Store,
MemStore存储的是Key/Value键值对形式;
新数据放入HLog后,首先会放到Mem Store进行处理(内存读写速度快),HBase会对其定时进行轮询监控,当达到一定的条件(时间、数据容量)后,通过调用HDFS的API自动将其刷写到StoreFile上,刷写一次形成一个StoreFile;
HBase会将多个StoreFile进行合并,防止小文件过多,当StroreFile大到一定程序,HBase会对其作切分。
(2)StoreFile
StoreFile是磁盘级别存储的文件组件,它是HBase的组件,但物理保存于HDFS中。
(3)HFile
HFile是StoreFile的存储格式,例如txt、orc、parquet等。
四、HBase读写过程总结
通过HBase的结构图,总结数据读写的整体过程:
(1)读数据过程:Client访问Zookeeper,然后访问对应的RegionServer服务器,HBase首先依据row-key,找到对应的region(分片),然后再依据需要的列族Store,去磁盘上找到Store对应的文件夹,读取数据。
(2)写数据过程:Client访问Zookeeper,然后访问对应的RegionServer服务器,按照Store写入数据,先保存在HLog中,再保存在内存级别存储MemStore中;然后达到一定条件后,以HFile的格式Flush到StoreFile存储文件中,再持久化缓存到HDFS上。
整个过程中产生的HLog都会保存到HDFS中,服务器挂掉后恢复数据。