大数据之路——flume(1.9.0官网学习)
Flume简介
Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Apache Flume是一个分布式,可靠且可用的系统,用于有效地从许多不同的源收集,聚合和移动大量日志数据到集中式数据存储。
系统要求
Java运行时环境 - Java 1.8或更高版本
内存 - 源,通道或接收器使用的配置的足够内存
磁盘空间 - 通道或接收器使用的配置的足够磁盘空间
目录权限 - 代理使用的目录的读/写权限
架构
数据流模型
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,载有的数据对flume是不透明的,header是容纳了key-value字符串对的无序集合,key在集合中是唯一的;header可以在上下文路由中使用扩展,这些Event由Agent(Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。))外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
Agent配置
Flume Agent配置存储在本地配置文件中。这是一个遵循Java属性文件格式的文本文件。可以在同一配置文件中指定一个或多个Agent的配置。配置文件包括Agent中每个源,接收器和通道的属性以及它们如何连接在一起以形成数据流。
流中的每个组件(源,接收器或通道)都具有特定于类型和实例化的名称,类型和属性集。例如,Avro源需要主机名(或IP地址)和端口号来接收数据。内存通道可以具有最大队列大小(“容量”),HDFS接收器需要知道文件系统URI,创建文件的路径,文件轮换频率(“hdfs.rollInterval”)等。组件的所有此类属性需要在托管Flume Agent的属性文件中设置。
Agent需要知道要加载哪些组件以及它们如何连接以构成流程。这是通过列出代理中每个源,接收器和通道的名称,然后为每个接收器和源指定连接通道来完成的。例如,代理通过名为file-channel的文件通道将事件从名为avroWeb的Avro源流向HDFS sink hdfs-cluster1。配置文件将包含这些组件的名称和文件通道,作为avroWeb源和hdfs-cluster1接收器的共享通道。
启动Agent
使用名为flume-ng的shell脚本启动代理程序,该脚本位于Flume发行版的bin目录中。您需要在命令行上指定代理名称,config目录和配置文件:
$ bin / flume-ng agent -n $ agent_name -c conf -f conf / flume-conf.properties.template
-n 指定agent名称
-c 指定配置文件的目录
-f 指定配置文件
配置例子
在这里,我们给出一个示例配置文件,描述单节点Flume部署。此配置允许用户生成事件,然后将其记录到控制台。
#example.conf:单节点Flume配置
#命名此代理上的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置源
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#描述接收器
a1.sinks.k1.type = logger
#使用缓冲内存中事件的通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#将源和接收器绑定到通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
鉴于此配置文件,我们可以按如下方式启动Flume:
$ bin / flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger = INFO,console
请注意,在完整部署中,我们通常会包含一个选项: - conf = 。所述目录将包括一个外壳脚本flume-env.sh和潜在的一个log4j的属性文件。在这个例子中,我们传递一个Java选项来强制Flume登录到控制台,我们没有自定义环境脚本。、
通过将自己的jar包添加到flume-env.sh文件中的FLUME_CLASSPATH变量中,始终可以包含自定义Flume组件,但Flume现在支持一个名为plugins.d的特殊目录,该目录会自动获取以特定格式打包的插件。这样可以更轻松地管理插件打包问题,以及更简单的调试和几类问题的故障排除,尤其是库依赖性冲突。
plugins.d目录
该plugins.d目录位于$ FLUME_HOME / plugins.d。在启动时,flume-ng启动脚本在plugins.d目录中查找符合以下格式的插件,并在启动java时将它们包含在正确的路径中。
plugins.d中的每个插件(子目录)最多可以有三个子目录:
lib - the plugin’s jar(s)
libext - the plugin’s dependency jar(s)
native - any required native libraries, such as .so files
plugins.d目录中的两个插件示例:
plugins.d/
plugins.d/custom-source-1/
plugins.d/custom-source-1/lib/my-source.jar
plugins.d/custom-source-1/libext/spring-core-2.5.6.jar
plugins.d/custom-source-2/
plugins.d/custom-source-2/lib/custom.jar
plugins.d/custom-source-2/native/gettext.so
数据摄取
Flume支持许多从外部来源摄取数据的机制。
RPC
Flume发行版中包含的Avro客户端可以使用avro RPC机制将给定文件发送到Flume Avro源:
$ bin / flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10
上面的命令会将/usr/logs/log.10的内容发送到监听该端口的Flume源。
网络流
Flume支持以下机制从常用日志流类型中读取数据,例如:
Avro
Thrift
Syslog
Netcat
设置多代理流程

为了跨多个代理或跳数据流,先前代理的接收器和当前跳的源需要是avro类型,接收器指向源的主机名(或IP地址)和端口。
合并

日志收集中非常常见的情况是大量日志生成客户端将数据发送到连接到存储子系统的少数消费者代理。例如,从数百个Web服务器收集的日志发送给写入HDFS集群的十几个代理。
这可以通过使用avro接收器配置多个第一层代理在Flume中实现,所有这些代理都指向单个代理的avro源(同样,您可以在这种情况下使用thrift源/接收器/客户端)。第二层代理上的此源将接收的事件合并到单个信道中,该信道由信宿器消耗到其最终目的地。
多路复用流程
Flume支持将事件流多路复用到一个或多个目的地。这是通过定义可以复制或选择性地将事件路由到一个或多个信道的流复用器来实现的。
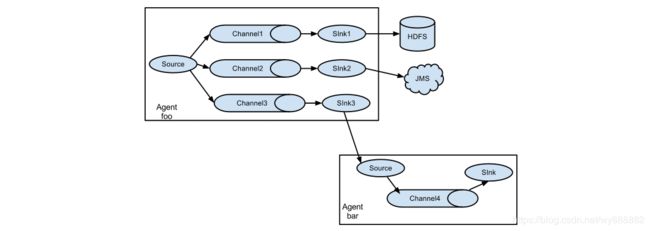
上面的例子显示了来自代理“foo”的源代码将流程扩展到三个不同的通道。扇出可以复制或多路复用。在复制流的情况下,每个事件被发送到所有三个通道。对于多路复用情况,当事件的属性与预配置的值匹配时,事件将被传递到可用通道的子集。例如,如果一个名为“txnType”的事件属性设置为“customer”,那么它应该转到channel1和channel3,如果它是“vendor”,那么它应该转到channel2,否则转到channel3。可以在代理的配置文件中设置映射。
配置
如前面部分所述,Flume代理程序配置是从类似于具有分层属性设置的Java属性文件格式的文件中读取的。
定义流
要在单个代理中定义流,您需要通过通道链接源和接收器。您需要列出给定代理的源,接收器和通道,然后将源和接收器指向通道。源实例可以指定多个通道,但接收器实例只能指定一个通道。格式如下:
# list the sources, sinks and channels for the agent
.sources =
.sinks =
.channels =
# set channel for source
.sources..channels = ...
# set channel for sink
.sinks..channel =
例如,名为agent_foo的代理正在从外部avro客户端读取数据并通过内存通道将其发送到HDFS。配置文件weblog.config可能如下所示:
#list the sources, sinks and channels for the agent
agent_foo.sources = avro-appserver-src-1
agent_foo.sinks = hdfs-sink-1
agent_foo.channels = mem-channel-1
#set channel for source
agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1
#set channel for sink
agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
这将使事件从avro-AppSrv-source流向hdfs-Cluster1-sink,通过内存通道mem-channel-1。当使用weblog.config作为其配置文件启动代理程序时,它将实例化该流程。
配置单个组件
定义流后,可以设置每个源,接收器和通道的属性。这是以相同的分层命名空间方式完成的,可以在其中设置组件类型以及特定于每个组件的属性值
# properties for sources
.sources.. =
# properties for channels
.channel.. =
# properties for sinks
.sources.. =
需要为Flume的每个组件设置属性“type”,以了解它需要什么类型的对象。每个源,接收器和通道类型都有自己的一组属性,使其能够按预期运行。所有这些都需要根据需要进行设置。在前面的示例中,我们有一个从avro-AppSrv-source到hdfs-Cluster1-sink的流程通过内存通道mem-channel-1。这是一个显示每个组件配置的示例:
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = hdfs-Cluster1-sink
agent_foo.channels = mem-channel-1
# set channel for sources, sinks
# properties of avro-AppSrv-source
agent_foo.sources.avro-AppSrv-source.type = avro
agent_foo.sources.avro-AppSrv-source.bind = localhost
agent_foo.sources.avro-AppSrv-source.port = 10000
# properties of mem-channel-1
agent_foo.channels.mem-channel-1.type = memory
agent_foo.channels.mem-channel-1.capacity = 1000
agent_foo.channels.mem-channel-1.transactionCapacity = 100
# properties of hdfs-Cluster1-sink
agent_foo.sinks.hdfs-Cluster1-sink.type = hdfs
agent_foo.sinks.hdfs-Cluster1-sink.hdfs.path = hdfs://namenode/flume/webdata
在代理中添加多个流
单个Flume代理可以包含多个独立流。可以在配置中列出多个源,接收器和通道。可以链接这些组件以形成多个流:
# list the sources, sinks and channels for the agent
.sources =
.sinks =
.channels =
然后,您可以将源和接收器链接到通道(用于接收器)的相应通道(用于源),以设置两个不同的流。例如,如果您需要在代理中设置两个流,一个从外部avro客户端到外部HDFS,另一个从尾部输出到avro接收器,那么这是一个配置来执行此操作:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1 exec-tail-source2
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# flow #1 configuration
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
# flow #2 configuration
agent_foo.sources.exec-tail-source2.channels = file-channel-2
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
配置多代理流
设置多层流,您需要有第一跳的avro / thrift接收器指向下一跳的avro / thrift源。这将导致第一个Flume代理将事件转发到下一个Flume代理。例如,如果您使用avro客户端定期向本地Flume代理发送文件(每个事件1个文件),则此本地代理可以将其转发到另一个已安装存储的代理。
Weblog agent config:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = avro-forward-sink
agent_foo.channels = file-channel
# define the flow
agent_foo.sources.avro-AppSrv-source.channels = file-channel
agent_foo.sinks.avro-forward-sink.channel = file-channel
# avro sink properties
agent_foo.sinks.avro-forward-sink.type = avro
agent_foo.sinks.avro-forward-sink.hostname = 10.1.1.100
agent_foo.sinks.avro-forward-sink.port = 10000
# configure other pieces
HDFS agent config:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-collection-source
agent_foo.sinks = hdfs-sink
agent_foo.channels = mem-channel
# define the flow
agent_foo.sources.avro-collection-source.channels = mem-channel
agent_foo.sinks.hdfs-sink.channel = mem-channel
# avro source properties
agent_foo.sources.avro-collection-source.type = avro
agent_foo.sources.avro-collection-source.bind = 10.1.1.100
agent_foo.sources.avro-collection-source.port = 10000
# configure other pieces
这里,我们将weblog代理的avro-forward-sink链接到hdfs代理的avro-collection-source。这将导致来自外部应用程序服务器源的事件最终存储在HDFS中。
以下示例具有多路复用到两个路径的单个流。名为agent_foo的代理具有单个avro源和两个链接到两个接收器的通道:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# set channels for source
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2
# set channel for sinks
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
选择器检查名为“State”的标头。如果该值为“CA”,则将其发送到mem-channel-1,如果其为“AZ”,则将其发送到文件通道-2,或者如果其为“NY”则为两者。如果“状态”标题未设置或与三者中的任何一个都不匹配,则它将转到mem-channel-1,其被指定为“default”。
Flume Sources
Avro Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
Thrift Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = thrift
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
Exec Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
JMS Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = jms
a1.sources.r1.channels = c1
a1.sources.r1.initialContextFactory = org.apache.activemq.jndi.ActiveMQInitialContextFactory
a1.sources.r1 .connectionFactory = GenericConnectionFactory
a1.sources.r1.providerURL = TCP:// MQSERVER:61616
a1.sources.r1.destinationName = BUSINESS_DATA
a1.sources.r1.destinationType = QUEUE
Spooling Directory Source
Example for an agent named agent-1:
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /var/log/apache/flumeSpool
a1.sources.src-1.fileHeader = true
Taildir Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
Kafka Source
Example for topic subscription by comma-separated topic list.
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.batchSize = 5000
tier1.sources.source1.batchDurationMillis = 2000
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics = test1, test2
tier1.sources.source1.kafka.consumer.group.id = custom.g.id
Example for topic subscription by regex
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = 通道1
tier1.sources.source1.kafka.bootstrap.servers = 本地主机:9092
tier1.sources.source1.kafka .topics.regex = ^ topic [0-9] $
#默认使用kafka.consumer.group.id = flume
TLS and Kafka Source
Example configuration with server side authentication and data encryption.
a1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.source1.kafka.bootstrap.servers = kafka-1:9093,kafka-2:9093,kafka-3:9093
a1.sources.source1.kafka.topics = mytopic
a1.sources.source1.kafka.consumer.group.id = flume-consumer
a1.sources.source1.kafka.consumer.security.protocol = SSL
# optional, the global truststore can be used alternatively
a1.sources.source1.kafka.consumer.ssl.truststore.location=/path/to/truststore.jks
a1.sources.source1.kafka.consumer.ssl.truststore.password=
NetCat TCP Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.sources.r1.channels = c1
NetCat UDP Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = netcatudp
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.sources.r1.channels = c1
Sequence Generator Source
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = seq
a1.sources.r1.channels = c1
Syslog TCP Source
For example, a syslog TCP source for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.host = localhost
a1.sources.r1.channels = c1
Multiport Syslog TCP Source
For example, a multiport syslog TCP source for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = multiport_syslogtcp
a1.sources.r1.channels = c1
a1.sources.r1.host = 0.0.0.0
a1.sources.r1.ports = 10001 10002 10003
a1.sources.r1.portHeader = port
HTTP Source
An example http source for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = http
a1.sources.r1.port = 5140
a1.sources.r1.channels = c1
a1.sources.r1.handler = org.example.rest.RestHandler
a1.sources.r1.handler.nickname = random props
a1.sources.r1.HttpConfiguration.sendServerVersion = false
a1.sources.r1.ServerConnector.idleTimeout = 300
Custom Source
自定义源是您自己的Source接口实现。启动Flume代理时,自定义源的类及其依赖项必须包含在代理程序的类路径中。自定义源的类型是其FQCN。
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = org.example.MySource
a1.sources.r1.channels = c1
Flume Sinks
HDFS Sink
此接收器将事件写入Hadoop分布式文件系统(HDFS)。它目前支持创建文本和序列文件。它支持两种文件类型的压缩。可以根据经过的时间或数据大小或事件数量定期滚动文件(关闭当前文件并创建新文件)。它还根据事件源自的时间戳或机器等属性对数据进行分区/分区。HDFS目录路径可能包含格式转义序列,将由HDFS接收器替换,以生成用于存储事件的目录/文件名。使用此接收器需要安装hadoop,以便Flume可以使用Hadoop jar与HDFS集群进行通信。请注意,需要支持sync()调用的Hadoop版本。
代理名为a1的示例:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
以上配置将时间戳向下舍入到最后10分钟。例如,时间戳为2012年6月12日上午11:54:34的事件将导致hdfs路径变为/ flume / events / 2012-06-12 / 1150/00。
Hive Sink
Example Hive table :
create table weblogs ( id int , msg string )
partitioned by (continent string, country string, time string)
clustered by (id) into 5 buckets
stored as orc;
Example for agent named a1:
a1.channels = c1
a1.channels.c1.type = memory
a1.sinks = k1
a1.sinks.k1.type = hive
a1.sinks.k1.channel = c1
a1.sinks.k1.hive.metastore = thrift://127.0.0.1:9083
a1.sinks.k1.hive.database = logsdb
a1.sinks.k1.hive.table = weblogs
a1.sinks.k1.hive.partition = asia,%{country},%y-%m-%d-%H-%M
a1.sinks.k1.useLocalTimeStamp = false
a1.sinks.k1.round = true
a1.sinks.k1.roundValue = 10
a1.sinks.k1.roundUnit = minute
a1.sinks.k1.serializer = DELIMITED
a1.sinks.k1.serializer.delimiter = "\t"
a1.sinks.k1.serializer.serdeSeparator = '\t'
a1.sinks.k1.serializer.fieldnames =id,,msg
以上配置将时间戳向下舍入到最后10分钟。例如,将时间戳标头设置为2012年6月12日上午11:54:34且“country”标头设置为“india”的事件将评估为分区(continent =‘asia’,country =‘india’,time =‘2012-06-12-11-50’。序列化程序配置为接受包含三个字段的制表符分隔输入并跳过第二个字段。
Logger Sink
Example for agent named a1:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
Avro Sink
Example for agent named a1:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 10.10.10.10
a1.sinks.k1.port = 4545
HBaseSink
此接收器将数据写入HBase。Hbase配置是从类路径中遇到的第一个hbase-site.xml中获取的。实现由配置指定的HbaseEventSerializer的类用于将事件转换为HBase put和/或增量。然后将这些放置和增量写入HBase。该接收器提供与HBase相同的一致性保证,HBase是当前行的原子性。如果Hbase无法写入某些事件,则接收器将重播该事务中的所有事件。
HBaseSink支持将数据写入安全HBase。要写入安全HBase,代理程序正在运行的用户必须具有对接收器配置为写入的表的写入权限。可以在配置中指定用于对KDC进行身份验证的主体和密钥表。Flume代理程序类路径中的hbase-site.xml必须将身份验证设置为kerberos(有关如何执行此操作的详细信息,请参阅HBase文档)。
为方便起见,Flume提供了两个序列化器。SimpleHbaseEventSerializer(org.apache.flume.sink.hbase.SimpleHbaseEventSerializer)按原样将事件主体写入HBase,并可选择增加Hbase中的列。这主要是一个示例实现。RegexHbaseEventSerializer(org.apache.flume.sink.hbase.RegexHbaseEventSerializer)根据给定的正则表达式打破事件体,并将每个部分写入不同的列。
类型是FQCN:org.apache.flume.sink.hbase.HBaseSink。
代理名为a1的示例:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hbase
a1.sinks.k1.table = foo_table
a1.sinks.k1.columnFamily = bar_cf
a1.sinks.k1.serializer = org.apache.flume .sink.hbase.RegexHbaseEventSerializer
a1.sinks.k1.channel = c1
HBase2Sink
HBase2Sink相当于HBase版本2的HBaseSink。提供的功能和配置参数与HBaseSink的情况相同(除了接收器类型中的hbase2标签和包/类名称)。
类型是FQCN:org.apache.flume.sink.hbase2.HBase2Sink。
Example for agent named a1:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hbase2
a1.sinks.k1.table = foo_table
a1.sinks.k1.columnFamily = bar_cf
a1.sinks.k1.serializer = org.apache.flume.sink.hbase2.RegexHBase2EventSerializer
a1.sinks.k1.channel = c1
ElasticSearchSink
代理名为a1的示例:
a1.channels = C1
a1.sinks = K1
a1.sinks.k1.type = elasticsearch
a1.sinks.k1.hostNames = 127.0.0.1:9200,127.0.0.2:9300
a1.sinks.k1.indexName = foo_index
a1.sinks .k1.indexType = bar_type
a1.sinks.k1.clusterName = foobar_cluster
a1.sinks.k1.batchSize = 500
a1.sinks.k1.ttl = 5d
a1.sinks.k1.serializer = org.apache.flume.sink.elasticsearch .ElasticSearchDynamicSerializer
a1.sinks.k1.channel = C1
Kafka Sink
下面给出Kafka接收器的示例配置。以kafka生产者前缀kafka.producer开头的属性。创建Kafka生成器时传递的属性不限于此示例中给出的属性。此外,可以在此处包含您的自定义属性,并通过作为方法参数传入的Flume Context对象在预处理器中访问它们。
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
HTTP Sink
Example for agent named a1:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = http
a1.sinks.k1.channel = c1
a1.sinks.k1.endpoint = http://localhost:8080/someuri
a1.sinks.k1.connectTimeout = 2000
a1.sinks.k1.requestTimeout = 2000
a1.sinks.k1.acceptHeader = application/json
a1.sinks.k1.contentTypeHeader = application/json
a1.sinks.k1.defaultBackoff = true
a1.sinks.k1.defaultRollback = true
a1.sinks.k1.defaultIncrementMetrics = false
a1.sinks.k1.backoff.4XX = false
a1.sinks.k1.rollback.4XX = false
a1.sinks.k1.incrementMetrics.4XX = true
a1.sinks.k1.backoff.200 = false
a1.sinks.k1.rollback.200 = false
a1.sinks.k1.incrementMetrics.200 = true
自定义接收器:Custom Sink
自定义接收器是您自己的Sink接口实现。启动Flume代理程序时,必须在代理程序的类路径中包含自定义接收器的类及其依赖项。自定义接收器的类型是其FQCN
Example for agent named a1:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = org.example.MySink
a1.sinks.k1.channel = c1
Flume Channels
Memory Channel
事件存储在具有可配置最大大小的内存中队列中。它非常适合需要更高吞吐量的流量,并且在代理发生故障时准备丢失分阶段数据
代理名为a1的示例:
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
JDBC Channel
Example for agent named a1:
a1.channels = c1
a1.channels.c1.type = jdbc
Kafka Channel
事件存储在Kafka群集中(必须单独安装)。Kafka提供高可用性和复制,因此如果代理或kafka代理崩溃,事件可立即用于其他接收器
Kafka频道可用于多种场景:
使用Flume源和接收器 - 它为事件提供了可靠且高度可用的通道
使用Flume源和拦截器但没有接收器 - 它允许将Flume事件写入Kafka主题,供其他应用程序使用
使用Flume接收器,但没有源 - 它是一种低延迟,容错的方式将事件从Kafka发送到Flume接收器,如HDFS,HBase或Solr
这目前支持Kafka服务器版本0.10.1.0或更高版本。测试完成了2.0.1,这是发布时最高的可用版本。
配置参数组织如下:
通常与通道相关的配置值应用于通道配置级别,例如:a1.channel.k1.type =
与Kafka相关的配置值或Channel运行的前缀以“kafka。”为前缀(这对CommonClient Configs是有效的),例如:a1.channels.k1.kafka.topic和a1.channels.k1.kafka.bootstrap.servers。这与hdfs接收器的运行方式没有什么不同
特定于生产者/消费者的属性以kafka.producer或kafka.consumer为前缀
在可能的情况下,使用Kafka参数名称,例如:bootstrap.servers和acks
Example for agent named a1:
a1.channels.channel1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.channel1.kafka.bootstrap.servers = kafka-1:9092,kafka-2:9092,kafka-3:9092
a1.channels.channel1.kafka.topic = channel1
a1.channels.channel1.kafka.consumer.group.id = flume-consumer
File Channel
Example for agent named a1:
a1.channels = c1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /mnt/flume/checkpoint
a1.channels.c1.dataDirs = /mnt/flume/data\
Flume Channel Selectors
Replicating Channel Selector (default)
Example for agent named a1 and it’s source called r1:
a1.sources = r1
a1.channels = c1 c2 c3
a1.sources.r1.selector.type = replicating
a1.sources.r1.channels = c1 c2 c3
a1.sources.r1.selector.optional = c3
Multiplexing Channel Selector
Example for agent named a1 and it’s source called r1:
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4
Custom Channel Selector
自定义通道选择器是您自己的ChannelSelector接口实现。启动Flume代理程序时,自定义通道选择器的类及其依赖项必须包含在代理程序的类路径中。自定义通道选择器的类型是其FQCN
Example for agent named a1 and its source called r1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.selector.type = org.example.MyChannelSelector
Flume Interceptors
Flume具有在飞行中修改/删除事件的能力。这是在拦截器的帮助下完成的。拦截器是实现org.apache.flume.interceptor.Interceptor的类接口。拦截器可以根据拦截器开发者选择的任何标准修改甚至删除事件。Flume支持拦截器的链接。通过在配置中指定拦截器构建器类名列表,可以实现此目的。拦截器在源配置中指定为以空格分隔的列表。指定拦截器的顺序是它们被调用的顺序。一个拦截器返回的事件列表将传递给链中的下一个拦截器。拦截器可以修改或删除事件。如果拦截器需要删除事件,它就不会在它返回的列表中返回该事件。如果要删除所有事件,则只返回一个空列表。拦截器是命名组件,下面是它们如何通过配置创建的示例:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.HostInterceptor$Builder
a1.sources.r1.interceptors.i1.preserveExisting = false
a1.sources.r1.interceptors.i1.hostHeader = hostname
a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
a1.sinks.k1.filePrefix = FlumeData.%{CollectorHost}.%Y-%m-%d
a1.sinks.k1.channel = c1
请注意,拦截器构建器将传递给类型config参数。拦截器本身是可配置的,可以传递配置值,就像传递给任何其他可配置组件一样。在上面的示例中,事件首先传递给HostInterceptor,然后HostInterceptor返回的事件传递给TimestampInterceptor。您可以指定完全限定的类名(FQCN)或别名时间戳。如果您有多个收集器写入相同的HDFS路径,那么您也可以使用HostInterceptor。
Timestamp Interceptor
此拦截器将事件标头插入到事件标头中,以毫秒为单位处理事件。此拦截器插入带有键时间戳(或由header属性指定)的标头,其值为相关时间戳。如果已在配置中存在,则此拦截器可以保留现有时间戳。
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.channels = c1
a1.sources.r1.type = seq
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
Host Interceptor
此拦截器插入运行此代理程序的主机的主机名或IP地址。它根据配置插入带有密钥主机或已配置密钥的标头,其值为主机的主机名或IP地址
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = host
Static Interceptor
静态拦截器允许用户将具有静态值的静态头附加到所有事件
Example for agent named a1:
a1.sources = r1
a1.channels = c1
a1.sources.r1.channels = c1
a1.sources.r1.type = seq
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = datacenter
a1.sources.r1.interceptors.i1.value = NEW_YORK
Search and Replace Interceptor
此拦截器基于Java正则表达式提供简单的基于字符串的搜索和替换功能。还可以进行回溯/群组捕捉。此拦截器使用与Java Matcher.replaceAll()方法中相同的规则。
Example configuration:
a1.sources.avroSrc.interceptors = search-replace
a1.sources.avroSrc.interceptors.search-replace.type = search_replace
# Remove leading alphanumeric characters in an event body.
a1.sources.avroSrc.interceptors.search-replace.searchPattern = ^[A-Za-z0-9_]+
a1.sources.avroSrc.interceptors.search-replace.replaceString =
Another example:
a1.sources.avroSrc.interceptors = search-replace
a1.sources.avroSrc.interceptors.search-replace.type = search_replace
# Use grouping operators to reorder and munge words on a line.
a1.sources.avroSrc.interceptors.search-replace.searchPattern = The quick brown ([a-z]+) jumped over the lazy ([a-z]+)
a1.sources.avroSrc.interceptors.search-replace.replaceString = The hungry $2 ate the careless $1
Environment Variable Config Filter
要在配置中隐藏密码,请设置其值,如以下示例所示
a1.sources = r1
a1.channels = c1
a1.configfilters = f1
a1.configfilters.f1.type = env
a1.sources.r1.channels = c1
a1.sources.r1.type = http
a1.sources.r1.keystorePassword = ${f1['my_keystore_password']} #will get the value Secret123
这里a1.sources.r1.keystorePassword配置属性将获取my_keystore_password 环境变量的值。设置环境变量的一种方法是运行如下所示的flume代理:
$ my_keystore_password = Secret123 bin / flume -ng agent --conf conf --conf-file example.conf …
开发flume自定义组件
Client
客户在事件的起源点进行操作并将其交付给Flume代理。客户端通常在他们正在使用数据的应用程序的进程空间中运行。Flume目前支持Avro,log4j,syslog和Http POST(带有JSON主体)作为从外部源传输数据的方法。此外,还有一个ExecSource可以使用本地进程的输出作为Flume的输入。
很可能有一个用例,这些现有的选项是不够的。在这种情况下,您可以构建自定义机制以将数据发送到Flume。有两种方法可以实现这一目标。第一个选项是创建一个自定义客户端,与Flume现有的Source之一(如 AvroSource或SyslogTcpSource)进行通信。客户端应将其数据转换为这些Flume Source所理解的消息。另一种选择是编写一个自定义Flume Source,它使用某种IPC或RPC协议直接与您现有的客户端应用程序进行通信,然后将客户端数据转换为Flume Event,以便向下游发送。
Client SDK
虽然Flume包含许多内置机制(即Source)来摄取数据,但通常需要能够直接从自定义应用程序与Flume进行通信。Flume Client SDK是一个库,使应用程序能够连接到Flume并通过RPC将数据发送到Flume的数据流。
RPC client interface
Flume的RpcClient接口的实现封装了Flume支持的RPC机制。用户的应用程序可以简单地调用Flume Client SDK的append(Event)或appendBatch(List )来发送数据,而不用担心底层的消息交换细节。用户可以通过直接实现Event接口,使用简单实现(如SimpleEvent类)或使用 EventBuilder重载的withBody()静态帮助器方法来提供所需的Event arg 。
RPC clients - Avro and Thrift
从Flume 1.4.0开始,Avro是默认的RPC协议。该 NettyAvroRpcClient和ThriftRpcClient实现RpcClient 接口。客户端需要使用目标Flume代理的主机和端口创建此对象,然后可以使用RpcClient将数据发送到代理。以下示例显示如何在用户的数据生成应用程序中使用Flume Client SDK API:
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
public class MyApp {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("host.example.org", 41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
String sampleData = "Hello Flume!";
for (int i = 0; i < 10; i++) {
client.sendDataToFlume(sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}
Sink
一的目的水槽中提取事件从S 信道,并将其转发到下一个水槽代理在流或存储它们在外部存储库中。根据Flume属性文件中的配置,接收器只与一个Channel相关联。每个已配置的Sink都有一个SinkRunner实例,当Flume框架调用 SinkRunner.start()时,会创建一个新线程来驱动Sink(使用 SinkRunner.PollingRunner作为线程的Runnable)。这个线程管理着Sink的生命周期。该水槽需要实现作为LifecycleAware接口一部分的start()和 stop()方法。该 Sink.start()方法应该初始化水槽,并把它在那里可以转发的状态事件 s到它的下一个目的地。所述 Sink.process()方法应当做提取的核心处理 事件从频道和转发它。该Sink.stop()方法应该做必要的清理(如释放资源)。该接收器 的实现还需要实现可配置用于处理自己的配置设置的界面。例如:
public class MySink extends AbstractSink implements Configurable {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external repository (e.g. HDFS) that
// this Sink will forward Events to ..
}
@Override
public void stop () {
// Disconnect from the external respository and do any
// additional cleanup (e.g. releasing resources or nulling-out
// field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
Event event = ch.take();
// Send the Event to the external repository.
// storeSomeData(e);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// Log exception, handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
}
return status;
}
}
Source、
Source的目的是从外部客户端接收数据并将其存储到已配置的Channel中。一个来源可以得到它自己的一个实例 的ChannelProcessor处理一个事件,一个内COMMITED 通道 本地事务,串行。在异常的情况下,所需的 Channel将传播异常,所有Channel将回滚其事务,但先前在其他Channel上处理的事件将保持提交。
与SinkRunner.PollingRunner Runnable类似,有一个PollingRunner Runnable,它在Flume框架调用PollableSourceRunner.start()时创建的线程上执行。每个配置的 PollableSource都与自己运行PollingRunner的线程相关联 。该线程管理PollableSource的生命周期,例如启动和停止。一个PollableSource实现必须实现的start()和停止()是在该声明的方法 LifecycleAware接口。一个转轮PollableSource调用了 Source的 process()方法。该过程()方法应该检查新数据,并将其存储到频道的水槽事件秒。
请注意,实际上有两种类型的Source。该PollableSource 已经提到。另一个是EventDrivenSource。该 EventDrivenSource,不像PollableSource,必须捕获新的数据并将其存储到自己的回调机制通道。该 EventDrivenSource s为各不被自己的线程,如驱动 PollableSource s为。下面是一个自定义PollableSource的示例:
public class MySource extends AbstractSource implements Configurable, PollableSource {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation, convert to another type, ...)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external client
}
@Override
public void stop () {
// Disconnect from external client and do any additional cleanup
// (e.g. releasing resources or nulling-out field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
try {
// This try clause includes whatever Channel/Event operations you want to do
// Receive new data
Event e = getSomeData();
// Store the Event into this Source's associated Channel(s)
getChannelProcessor().processEvent(e);
status = Status.READY;
} catch (Throwable t) {
// Log exception, handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}