《Python机器学习及实践:从零开始通往Kaggle竞赛之路》第2章 基础篇 学习笔记(三)2.1.1.3朴素贝叶斯总结
目录
2.1.1.3朴素贝叶斯
1、模型介绍
(1)朴素贝叶斯的定义
(2)朴素贝叶斯模型
2、数据描述
(1)20类新闻文本数据背景
(2)20类新闻文本数据细节
(3)20类新闻文本数据分割
3、编程实践
4、性能测评
5、特点分析
2.1.1.3朴素贝叶斯
1、模型介绍
(1)朴素贝叶斯的定义
朴素贝叶斯是一个非常简单,但是实用性很强的分类模型。不过,和两个基于线性假设的模型(线性分类器和支持向量机分类器)不同,朴素贝叶斯分类器的构造基础是贝叶斯理论。
朴素贝叶斯分类器会单独考量每一维度特征被分类的条件概率,进而综合这些概率并对其所在的特征向量做出分类预测。因此,这个模型的基本数学假设是:各个维度上的特征被分类的条件概率之间是相互独立的。
(2)朴素贝叶斯模型
如果采用概率模型来表述,则定义![]() 为某一n维特征向量,
为某一n维特征向量,![]() 为该特征向量x所有k种可能的类别,记
为该特征向量x所有k种可能的类别,记![]() 为特征向量x属于类别
为特征向量x属于类别 的概率。根据式(9)的贝叶斯原理:
的概率。根据式(9)的贝叶斯原理:
![]()
目标是寻找所有![]() 中
中 最大的,即
最大的,即![]() ;并且考虑到
;并且考虑到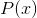 对于同一样本都是相同的,因此可以忽略不计。所以,
对于同一样本都是相同的,因此可以忽略不计。所以,
![]()
若每一种特征可能的取值均为0或者1,在没有任何特殊假设的条件下,计算![]() 需要对
需要对![]() 个可能的参数进行估计:
个可能的参数进行估计:
![]()
但是由于朴素贝叶斯模型的特征类别条件独立假设,![]() ;若依然每一种特征可能的取值只有2种,那么只需要2kn个参数,即
;若依然每一种特征可能的取值只有2种,那么只需要2kn个参数,即![]() 。
。
为了估计每个参数的概率,采用如下的公式,并且改用频率比近似计算概率:

2、数据描述
(1)20类新闻文本数据背景
朴素贝叶斯模型有着广泛的实际应用环境,特别是在文本分类的任务中间,包括互联网新闻的分类、垃圾邮件的筛选等。本节中,将使用经典的20类新闻文本作为试验数据。
(2)20类新闻文本数据细节
# 代码21:读取20类新闻文本的数据细节
# 从sklearn.datasets里导入新闻数据抓取器fetch_20newsgroups。
from sklearn.datasets import fetch_20newsgroups
# 与之前预存的数据不同,fetch_20newsgroups需要即时从互联网下载数据。
news = fetch_20newsgroups(subset='all')
# 查验数据规模和细节。
print(len(news.data))
print(news.data[0])本地输出:
18846
From: Mamatha Devineni Ratnam
Subject: Pens fans reactions
Organization: Post Office, Carnegie Mellon, Pittsburgh, PA
Lines: 12
NNTP-Posting-Host: po4.andrew.cmu.edu
I am sure some bashers of Pens fans are pretty confused about the lack
of any kind of posts about the recent Pens massacre of the Devils. Actually,
I am bit puzzled too and a bit relieved. However, I am going to put an end
to non-PIttsburghers' relief with a bit of praise for the Pens. Man, they
are killing those Devils worse than I thought. Jagr just showed you why
he is much better than his regular season stats. He is also a lot
fo fun to watch in the playoffs. Bowman should let JAgr have a lot of
fun in the next couple of games since the Pens are going to beat the pulp out of Jersey anyway. I was very disappointed not to see the Islanders lose the final
regular season game. PENS RULE!!! 结论:由输出可获知该数据共有18846条新闻;不同于前面的样例数据,这些文本数据既没有被设定特征,也没有数字化的量度。因此,在交给朴素贝叶斯分类器学习之前,要对数据做进一步处理。不过在此之前,仍然需要对数据进行分割并且随机采样出一部分用于测试。
(3)20类新闻文本数据分割
# 代码22;20类新闻文本数据分割
# 从sklearn.model_selection中导入train_test_split。
from sklearn.model_selection import train_test_split
# 随机采样25%的数据样本作为测试集。
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)备注:原来的导入模型from sklearn.cross_validation import train_test_split的时候,提示错误:
from sklearn.cross_validation import train_test_split
ModuleNotFoundError: No module named 'sklearn.cross_validation'需要替换cross_validation:
from sklearn.model_selection import train_test_split3、编程实践
这部分的工作首先将文本转化为特征向量,然后利用朴素贝叶斯模型从训练数据中估计参数,最后利用这些概率参数对同样转化为特征向量的测试新闻样本进行类别预测。
# 代码23:使用朴素贝叶斯分类器对新闻文本数据进行类别预测
# 从sklearn.feature_extraction.text里导入用于文本特征向量转化模块。详细介绍请读者参考“3.1.1.1 特征抽取”节。
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.transform(X_test)
# 从sklearn.naive_bayes里导入朴素贝叶斯模型。
from sklearn.naive_bayes import MultinomialNB
# 从使用默认配置初始化朴素贝叶斯模型。
mnb = MultinomialNB()
# 利用训练数据对模型参数进行估计。
mnb.fit(X_train, y_train)
# 对测试样本进行类别预测,结果存储在变量y_predict中。
y_predict = mnb.predict(X_test)4、性能测评
使用准确性、召回率、精确率和F1指标,这4个测度对朴素贝叶斯模型在20类新闻文本分类任务上的性能进行评估。
代码24:对朴素贝叶斯分类器在新闻文本数据上的表现性能进行评估
# 从sklearn.metrics里导入classification_report用于详细的分类性能报告。
from sklearn.metrics import classification_report
print('The accuracy of Naive Bayes Classifier is', mnb.score(X_test, y_test))
print(classification_report(y_test, y_predict, target_names=news.target_names))本地输出:
The accuracy of Naive Bayes Classifier is 0.8397707979626485
precision recall f1-score support
alt.atheism 0.86 0.86 0.86 201
comp.graphics 0.59 0.86 0.70 250
comp.os.ms-windows.misc 0.89 0.10 0.17 248
comp.sys.ibm.pc.hardware 0.60 0.88 0.72 240
comp.sys.mac.hardware 0.93 0.78 0.85 242
comp.windows.x 0.82 0.84 0.83 263
misc.forsale 0.91 0.70 0.79 257
rec.autos 0.89 0.89 0.89 238
rec.motorcycles 0.98 0.92 0.95 276
rec.sport.baseball 0.98 0.91 0.95 251
rec.sport.hockey 0.93 0.99 0.96 233
sci.crypt 0.86 0.98 0.91 238
sci.electronics 0.85 0.88 0.86 249
sci.med 0.92 0.94 0.93 245
sci.space 0.89 0.96 0.92 221
soc.religion.christian 0.78 0.96 0.86 232
talk.politics.guns 0.88 0.96 0.92 251
talk.politics.mideast 0.90 0.98 0.94 231
talk.politics.misc 0.79 0.89 0.84 188
talk.religion.misc 0.93 0.44 0.60 158
accuracy 0.84 4712
macro avg 0.86 0.84 0.82 4712
weighted avg 0.86 0.84 0.82 4712结论:通过输出,获知朴素贝叶斯分类器对4712条新闻文本测试样本分类的准确性约为83.977%,平均精确率、召回率以及F1指标分别为0.86、0.84和0.82。
5、特点分析
朴素贝叶斯模型被广泛应用于海量互联网文本分类任务。由于其较强的特征条件独立假设,使得模型预测所需要估计的参数规模从幂指数量级向线性量级减少,极大地节约了内存消耗和计算时间。但是,也正是受这种强假设的限制,模型训练时无法将各个特征之间的联系考量在内,使得该模型在其他数据特征关联性较强的分类任务上的性能表现不佳。