alertmanager集群搭建
1 Gossip协议
Gossip是分布式系统中被广泛使用的协议,用于实现分布式节点之间的信息交换和状态同步。Gossip协议同步状态类似于流言或者病毒的传播,如下所示:

Gossip分布式协议
一般来说Gossip有两种实现方式分别为Push-based和Pull-based。在Push-based当集群中某一节点A完成一个工作后,随机的从其它节点B并向其发送相应的消息,节点B接收到消息后在重复完成相同的工作,直到传播到集群中的所有节点。而Pull-based的实现中节点A会随机的向节点B发起询问是否有新的状态需要同步,如果有则返回。
在简单了解了Gossip协议之后,我们来看Alertmanager是如何基于Gossip协议实现集群高可用的。如下所示,当Alertmanager接收到来自Prometheus的告警消息后,会按照以下流程对告警进行处理:
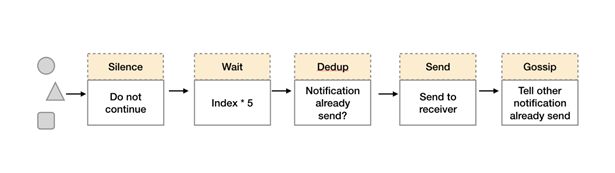
通知流水线
在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知。
在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间。
当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知。
告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。
因此如下所示,Gossip机制的关键在于两点:

Gossip机制
Silence设置同步:Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态,当有新的Silence产生时使用Push-based方式在集群中传播Gossip信息。
通知发送状态同步:告警通知发送完成后,基于Push-based同步告警发送状态。Wait阶段可以确保集群状态一致。
Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP系统,即可用性和分区容错性。同时对于Prometheus Server而言保持了配置了简单性,Promthues
Server之间不需要任何的状态同步。
2 搭建alertmanager集群
1 alertmanager版本在0.15.2以上才能实现alertmanager集群的部署(单节点的alertmanager搭建方法参考之前的文件)
--cluster.listen-address string: 当前实例集群服务监听地址
--cluster.peer value: 初始化时关联的其它实例的集群服务地址
节点1 192.168.248.128
Alertmanager服务文件:
Description=Alertmanager
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager- -web.external-url=http://192.168.248.128:9093 --cluster.listen-address=192.168.248.128:9094 - -cluster.peer=192.168.248.128:9094- -cluster.peer=192.168.248.129:9094 - -cluster.peer=192.168.248.130:9094 - -config.file=/usr/local/alertmanager/alertmanager.yml- -storage.path=/usr/local/alertmanager/data
Restart=on-failure
[Install]
WantedBy=multi-user.target
节点192.168.248.129
Alertmanager服务
Description=Alertmanager
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager- -web.external-url=http://192.168.248.129:9093 - -cluster.listen-address=192.168.248.129:9094- -cluster.peer=192.168.248.128:9094 - -cluster.peer=192.168.248.129:9094 --cluster.peer=192.168.248.130:9094 --config.file=/usr/local/alertmanager/alertmanager.yml- -storage.path=/usr/local/alertmanager/data
Restart=on-failure
[Install]
WantedBy=multi-user.target
节点192.168.248.130
Alertmanager服务
Description=Alertmanager
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager- -web.external-url=http://192.168.248.130:9093 - -cluster.listen-address=192.168.248.130:9094- -cluster.peer=192.168.248.128:9094 - -cluster.peer=192.168.248.129:9094 - -cluster.peer=192.168.248.130:9094 --config.file=/usr/local/alertmanager/alertmanager.yml--storage.path=/usr/local/alertmanager/data
Restart=on-failure
[Install]
WantedBy=multi-user.target
3 集群搭建成功以后进行测试
测试前prometheus及node_exporter环境已经部署完成,修改prometheus.yml文件
# my global config
global:
scrape_interval: 15s # Set thescrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The defaultis every 1 minute.
#scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
-static_configs:
-targets:
- '192.168.248.128:9093'
- '192.168.248.129:9093'
- '192.168.248.130:9093'
# Load rules once and periodically evaluatethem according to the global 'evaluation_interval'.
rule_files:
-"/usr/local/rule/state.yml"
# -"second_rules.yml"
# A scrape configuration containing exactlyone endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
#The job name is added as a label `job=` to any timeseriesscraped from this config.
-job_name: 'prometheus'
#metrics_path defaults to '/metrics'
#scheme defaults to 'http'.
static_configs:
-targets: ['192.168.248.128:9090']
-job_name: "node"
static_configs:
-targets: ['192.168.248.128:9100']
labels:
instance: test
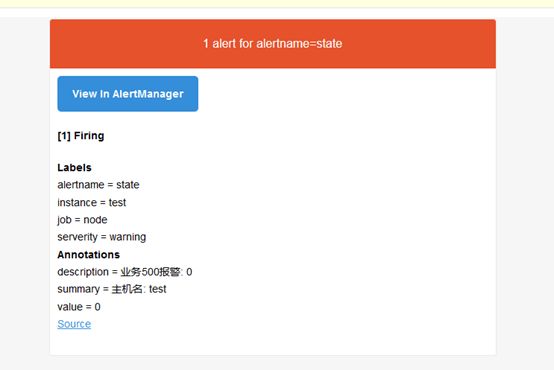
编写测试报警文件
groups:
- name: state
rules:
-alert: "state"
expr: up != 1
for: 1m
labels:
serverity: warning
annotations:
summary: "主机名: {{ $labels.instance }}"
description: "业务500报警: {{ $value }}"
value: "{{ $value }}"
编写alertmanger.yml文件
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '****@163.com'
smtp_auth_username: '*****@163.com'
smtp_auth_password: '*****'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
-to: '*****@163.com'
关闭node_exporter服务,稍等一会,就会在prometheus及alertmanager环境中看到相关报警信息