机器学习算法的Python实现 (2):ID3决策树
本文数据参照 机器学习-周志华 一书中的决策树一章。可作为此章课后习题3的答案
代码参考了《机器学习实战》一书的内容,并做了不少修改。使其能用于同时包含离散与连续特征的数据集。
本文使用的Python库包括
- numpy
- pandas
- math
- operator
- matplotlib
本文所用的数据如下:
| Idx | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | label |
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 1 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 1 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 1 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 1 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 1 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 1 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 1 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 1 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 0 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 0 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 0 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 0 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 0 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 0 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.36 | 0.37 | 0 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 0 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 0 |
由于我没搞定matplotlib的中文输出,因此将中文字符全换成了英文,如下:
| Idx | color | root | knocks | texture | navel | touch | density | sugar_ratio | label |
| 1 | dark_green | curl_up | little_heavily | distinct | sinking | hard_smooth | 0.697 | 0.46 | 1 |
| 2 | black | curl_up | heavily | distinct | sinking | hard_smooth | 0.774 | 0.376 | 1 |
| 3 | black | curl_up | little_heavily | distinct | sinking | hard_smooth | 0.634 | 0.264 | 1 |
| 4 | dark_green | curl_up | heavily | distinct | sinking | hard_smooth | 0.608 | 0.318 | 1 |
| 5 | light_white | curl_up | little_heavily | distinct | sinking | hard_smooth | 0.556 | 0.215 | 1 |
| 6 | dark_green | little_curl_up | little_heavily | distinct | little_sinking | soft_stick | 0.403 | 0.237 | 1 |
| 7 | black | little_curl_up | little_heavily | little_blur | little_sinking | soft_stick | 0.481 | 0.149 | 1 |
| 8 | black | little_curl_up | little_heavily | distinct | little_sinking | hard_smooth | 0.437 | 0.211 | 1 |
| 9 | black | little_curl_up | heavily | little_blur | little_sinking | hard_smooth | 0.666 | 0.091 | 0 |
| 10 | dark_green | stiff | clear | distinct | even | soft_stick | 0.243 | 0.267 | 0 |
| 11 | light_white | stiff | clear | blur | even | hard_smooth | 0.245 | 0.057 | 0 |
| 12 | light_white | curl_up | little_heavily | blur | even | soft_stick | 0.343 | 0.099 | 0 |
| 13 | dark_green | little_curl_up | little_heavily | little_blur | sinking | hard_smooth | 0.639 | 0.161 | 0 |
| 14 | light_white | little_curl_up | heavily | little_blur | sinking | hard_smooth | 0.657 | 0.198 | 0 |
| 15 | black | little_curl_up | little_heavily | distinct | little_sinking | soft_stick | 0.36 | 0.37 | 0 |
| 16 | light_white | curl_up | little_heavily | blur | even | hard_smooth | 0.593 | 0.042 | 0 |
| 17 | dark_green | curl_up | heavily | little_blur | little_sinking | hard_smooth | 0.719 | 0.103 | 0 |
字符的含义可自行对照上下两表
决策树生成的代码参照 机器学习实战 第三章的代码,但是书上第三章是针对离散特征的,下面程序中对其进行了修改,使其能用于同时包含离散与连续特征的数据集。
决策树生成代码如下:
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
import pandas as pd
from math import log
import operator
#计算数据集的香农熵
def calcShannonEnt(dataSet):
numEntries=len(dataSet)
labelCounts={}
#给所有可能分类创建字典
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0
#以2为底数计算香农熵
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
#对离散变量划分数据集,取出该特征取值为value的所有样本
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#对连续变量划分数据集,direction规定划分的方向,
#决定是划分出小于value的数据样本还是大于value的数据样本集
def splitContinuousDataSet(dataSet,axis,value,direction):
retDataSet=[]
for featVec in dataSet:
if direction==0:
if featVec[axis]>value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
else:
if featVec[axis]<=value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet,labels):
numFeatures=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0
bestFeature=-1
bestSplitDict={}
for i in range(numFeatures):
featList=[example[i] for example in dataSet]
#对连续型特征进行处理
if type(featList[0]).__name__=='float' or type(featList[0]).__name__=='int':
#产生n-1个候选划分点
sortfeatList=sorted(featList)
splitList=[]
for j in range(len(sortfeatList)-1):
splitList.append((sortfeatList[j]+sortfeatList[j+1])/2.0)
bestSplitEntropy=10000
slen=len(splitList)
#求用第j个候选划分点划分时,得到的信息熵,并记录最佳划分点
for j in range(slen):
value=splitList[j]
newEntropy=0.0
subDataSet0=splitContinuousDataSet(dataSet,i,value,0)
subDataSet1=splitContinuousDataSet(dataSet,i,value,1)
prob0=len(subDataSet0)/float(len(dataSet))
newEntropy+=prob0*calcShannonEnt(subDataSet0)
prob1=len(subDataSet1)/float(len(dataSet))
newEntropy+=prob1*calcShannonEnt(subDataSet1)
if newEntropybestInfoGain:
bestInfoGain=infoGain
bestFeature=i
#若当前节点的最佳划分特征为连续特征,则将其以之前记录的划分点为界进行二值化处理
#即是否小于等于bestSplitValue
if type(dataSet[0][bestFeature]).__name__=='float' or type(dataSet[0][bestFeature]).__name__=='int':
bestSplitValue=bestSplitDict[labels[bestFeature]]
labels[bestFeature]=labels[bestFeature]+'<='+str(bestSplitValue)
for i in range(shape(dataSet)[0]):
if dataSet[i][bestFeature]<=bestSplitValue:
dataSet[i][bestFeature]=1
else:
dataSet[i][bestFeature]=0
return bestFeature
#特征若已经划分完,节点下的样本还没有统一取值,则需要进行投票
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
return max(classCount)
#主程序,递归产生决策树
def createTree(dataSet,labels,data_full,labels_full):
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet,labels)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
if type(dataSet[0][bestFeat]).__name__=='str':
currentlabel=labels_full.index(labels[bestFeat])
featValuesFull=[example[currentlabel] for example in data_full]
uniqueValsFull=set(featValuesFull)
del(labels[bestFeat])
#针对bestFeat的每个取值,划分出一个子树。
for value in uniqueVals:
subLabels=labels[:]
if type(dataSet[0][bestFeat]).__name__=='str':
uniqueValsFull.remove(value)
myTree[bestFeatLabel][value]=createTree(splitDataSet\
(dataSet,bestFeat,value),subLabels,data_full,labels_full)
if type(dataSet[0][bestFeat]).__name__=='str':
for value in uniqueValsFull:
myTree[bestFeatLabel][value]=majorityCnt(classList)
return myTree 通过以下语句进行调用:
df=pd.read_csv('watermelon_4_3.csv')
data=df.values[:,1:].tolist()
data_full=data[:]
labels=df.columns.values[1:-1].tolist()
labels_full=labels[:]
myTree=createTree(data,labels,data_full,labels_full)可以得到以下结果
>>> myTree
{'texture': {'distinct': {'density<=0.3815': {0: 1L, 1: 0L}}, 'little_blur': {'touch': {'hard_smooth': 0L, 'soft_stick': 1L}}, 'blur': 0L}}
{'texture': {'distinct': {'density<=0.3815': {0: 1L, 1: 0L}}, 'little_blur': {'touch': {'hard_smooth': 0L, 'soft_stick': 1L}}, 'blur': 0L}}
以下为画图代码:
import matplotlib.pyplot as plt
decisionNode=dict(boxstyle="sawtooth",fc="0.8")
leafNode=dict(boxstyle="round4",fc="0.8")
arrow_args=dict(arrowstyle="<-")
#计算树的叶子节点数量
def getNumLeafs(myTree):
numLeafs=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs+=getNumLeafs(secondDict[key])
else: numLeafs+=1
return numLeafs
#计算树的最大深度
def getTreeDepth(myTree):
maxDepth=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth=1+getTreeDepth(secondDict[key])
else: thisDepth=1
if thisDepth>maxDepth:
maxDepth=thisDepth
return maxDepth
#画节点
def plotNode(nodeTxt,centerPt,parentPt,nodeType):
createPlot.ax1.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',\
xytext=centerPt,textcoords='axes fraction',va="center", ha="center",\
bbox=nodeType,arrowprops=arrow_args)
#画箭头上的文字
def plotMidText(cntrPt,parentPt,txtString):
lens=len(txtString)
xMid=(parentPt[0]+cntrPt[0])/2.0-lens*0.002
yMid=(parentPt[1]+cntrPt[1])/2.0
createPlot.ax1.text(xMid,yMid,txtString)
def plotTree(myTree,parentPt,nodeTxt):
numLeafs=getNumLeafs(myTree)
depth=getTreeDepth(myTree)
firstStr=myTree.keys()[0]
cntrPt=(plotTree.x0ff+(1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.y0ff)
plotMidText(cntrPt,parentPt,nodeTxt)
plotNode(firstStr,cntrPt,parentPt,decisionNode)
secondDict=myTree[firstStr]
plotTree.y0ff=plotTree.y0ff-1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key))
else:
plotTree.x0ff=plotTree.x0ff+1.0/plotTree.totalW
plotNode(secondDict[key],(plotTree.x0ff,plotTree.y0ff),cntrPt,leafNode)
plotMidText((plotTree.x0ff,plotTree.y0ff),cntrPt,str(key))
plotTree.y0ff=plotTree.y0ff+1.0/plotTree.totalD
def createPlot(inTree):
fig=plt.figure(1,facecolor='white')
fig.clf()
axprops=dict(xticks=[],yticks=[])
createPlot.ax1=plt.subplot(111,frameon=False,**axprops)
plotTree.totalW=float(getNumLeafs(inTree))
plotTree.totalD=float(getTreeDepth(inTree))
plotTree.x0ff=-0.5/plotTree.totalW
plotTree.y0ff=1.0
plotTree(inTree,(0.5,1.0),'')
plt.show()调用方式为
createPlot(myTree)以上的决策树计算代码以及画图代码可以放在不同的文件中进行调用,也可以直接放在一个py文件中。
得到的决策树如下图所示:
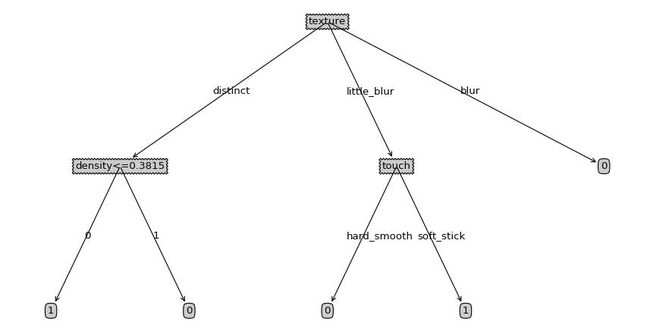
与 机器学习 教材P85页的图一致。
若文中或代码中有错误之处,烦请指正,不甚感激。
更新:
2016.4.3对决策树生成的createTree函数进行了更新(上文代码已经是更新后的代码)。
原来的代码为:
#主程序,递归产生决策树
def createTree(dataSet,labels):
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet,labels)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
#针对bestFeat的每个取值,划分出一个子树。
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet\
(dataSet,bestFeat,value),subLabels)
return myTree
如使用书上的表4.2(就是前面表格去掉密度和含糖量这两行)。使用之前代码得到的图为
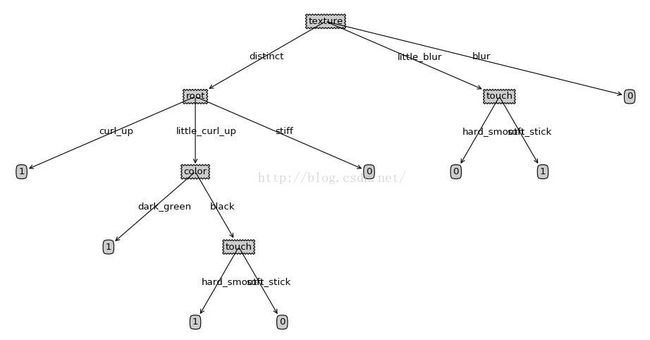
以下为修改后的结果图,与书上P78的图4.4一致

可以看出,修改后左侧colo特征的划分是完整的