oracle的sql转换为mysql的sql语法问题记录.续
背景
oracle的sql转换为mysql的sql语法问题记录
问题
oracle写法:
SELECT ? AS id,
REGEXP_SUBSTR (?, '[^,]+', 1,rownum) n0,
REGEXP_SUBSTR (?, '[^,]+', 1,rownum) n1,
... 中间省略一堆
REGEXP_SUBSTR (?, '[^,]+', 1,rownum) nn
from dual connect by rownum<=LENGTH (?) - LENGTH (regexp_replace(?, ',', ''))+1
说明:
先对用到的函数一一释义,
1. REGEXP_SUBSTR: 官方文档的截图
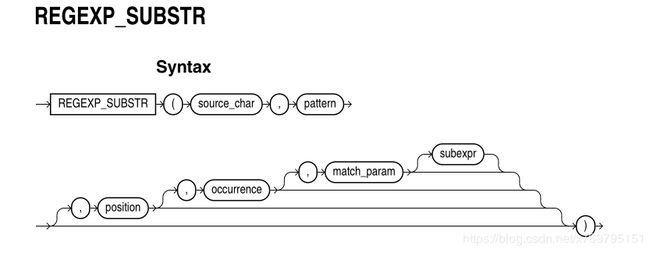
REGEXP_SUBSTR通过允许在字符串中搜索正则表达式模式来扩展SUBSTR函数的功能,不过它返回的不是子字符串的位置,而是子字符串本身。
source_char是用作搜索值的字符表达式
pattern是正则表达式
position是一个正整数,指示Oracle应该在其中开始搜索的source_char字符。默认值为1,表示Oracle从source_char的第一个字符开始搜索
occurrence是一个正整数,指示Oracle应该在source_char中搜索哪个模式出现。缺省值为1,表示Oracle搜索第一次出现的模式
match_parameter是文本字面值,可让您更改函数的默认匹配行为
对于具有子表达式的模式,subexpr是从0到9的非负整数,指示该函数将返回模式中的哪个子表达式
先忽略connect by的部分,假定rownum是1:Select REGEXP_SUBSTR (?, '[^,]+', 1,rownum) from dual,也假定?变量的值是字符串aa,bb,cc.
可以看做, Select REGEXP_SUBSTR (‘aa,bb,cc’, '[^,]+', 1,1) from dual的意思是将’aa,bb,cc’,以逗号分隔取第一个,即aa.
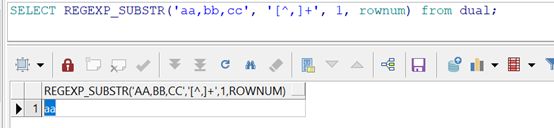
实际我的业务场景遇到一个问题:
这里用的?变量,这个?在这里出现一次,意味’aa,bb,cc’,做为参数只能出现一次,我转换为mysql时也只能出现一次。
所以,需要避免’aa,bb,cc’会作为2次参数使用的实现方式。
不要问为什么,当前这个?号不能用两次。所以如果是连续逗号去重也很麻烦,做为参数只能出现一次,那就不好处理。oracle好歹有这个正则拆分,一次处理好。
根据我推测当前上下文场景,排除掉了出现连续逗号的情况,所以转mysql实际看做一个逗号处理。
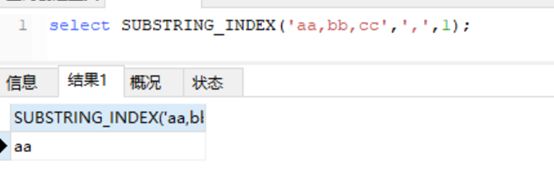
mysql替代方案:
使用SUBSTRING_INDEX(str,delim,count)
在出现定界符delim之前,从字符串str返回子字符串。count是我要的那个1。
2. oralce : length(str),返回字符串长度
此处理论上不能使用mysql的length,oracle的length使用字符来定义长度,而mysql的length是以字节为单位的,
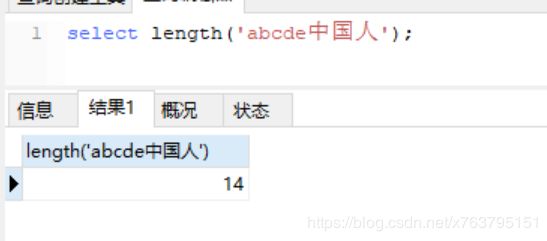
比如字符串’abcde‘,两个都返回5,但如果是字符串’abcde中国人’,有3个汉字,看效果:
Oracle还是8:
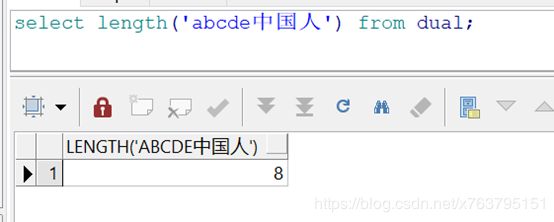
Mysql是14:
mysql替代方案:CHAR_LENGTH(str)/ CHARACTER_LENGTH(str):返回字符串str的长度,以字符为单位

3. oracle: regexp_replace(src, pat, dst), 将字符串src中的pat,替换为dst
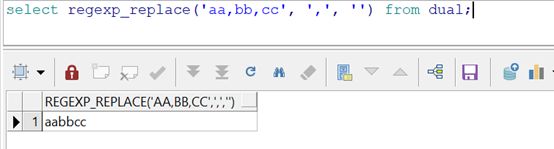
把逗号去掉
mysql替代方案:
当前场景使用:REPLACE(str,from_str,to_str)即可。返回字符串str,其中所有出现的字符串from_str都替换为字符串to_str。

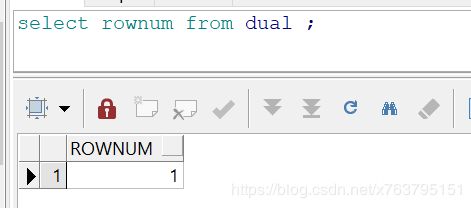
4. 最后一部分:connect by rownum<=
不多说,看结果 吧,只查dual,rownum是1:
但是这里要查一个数字序列,想递归查询:
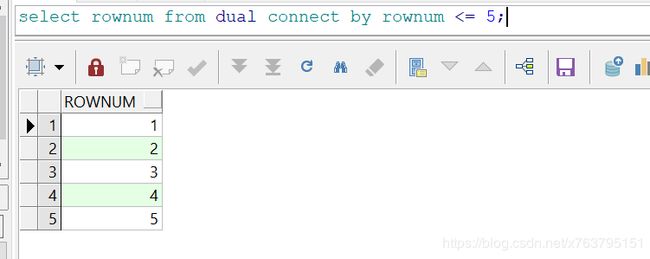
所以上面整个sql的目的就是:将字符串以逗号进行拆分,转换为行。如下:

mysql最终解决方案:
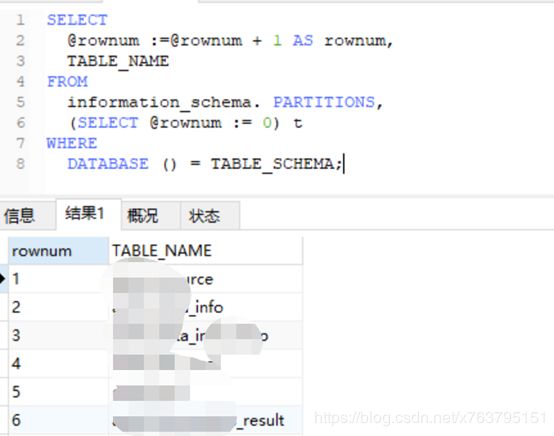
SELECT
SUBSTRING_INDEX(
SUBSTRING_INDEX('aa,bb,cc', ',', rownum),
',',
- 1
)
FROM
(
SELECT
@rownum :=@rownum + 1 AS rownum,
TABLE_NAME
FROM
information_schema. PARTITIONS,
(SELECT @rownum := 0) t
WHERE
DATABASE () = TABLE_SCHEMA
) t
WHERE
rownum <= CHAR_LENGTH('aa,bb,cc') - CHAR_LENGTH(REPLACE('aa,bb,cc', ',', '')) + 1;
说明下:
对于其中用到的几个函数,前面都已经说明了。这个@rownum是我定义的变量。对于:
SUBSTRING_INDEX(
SUBSTRING_INDEX('aa,bb,cc', ',', rownum),
',',
- 1
)
这部分,是通过rownum递增,分别取出aa,bb,cc。内层的: SUBSTRING_INDEX('aa,bb,cc', ',', rownum),随着rownum递增,分别返回aa\aa,bb\,aa,bb,cc,外层的参数-1,就是分别返回aa,bb,cc了。
rownum <= CHAR_LENGTH('aa,bb,cc') - CHAR_LENGTH(REPLACE('aa,bb,cc', ',', '')) + 1;这部分返回rownum的限制大小,就是aa,bb,cc能分成几部分。
from-where中间的嵌套子查询和变量定义,其实返回的是当前数据库中所有表的表名和它的行号,它的行号就是rownum的值。这种实现只对我当前场景百分百准确有用。因为aa,bb,cc实际在当前场景是数据库的表名组成的,所以它拆分的个数一定不会超过当前数据库表的总量。如果不是我这种场景,无法确定拆分字符串的时候能拆出来多少,这个rownum可能就要足够大,至少要比其中的分隔符要多吧,就需要考虑其它实现方案,比较借助辅助表及辅助字段等手段。
oracle写法:哎,这场景。 一条一二百行的sql,要改动的点不少,还有一堆变量,不说了,只补充点前面没提示到的吧。
1)Case when不用改,oracle基本和mysql差不多。
2)substr(str, instr(str,?), length(?)) = ?,,,用来判断str里是否包子字符串
substr: SUBSTR函数返回char的一部分,从char位置开始,substring_length个字符长。 SUBSTR使用输入字符集定义的字符来计算长度。 SUBSTRB使用字节而不是字符。 SUBSTRC使用Unicode完整字符。 SUBSTR2使用UCS2代码点。 SUBSTR4使用UCS4代码点.
mysql替代方案:
substr可以使用Mysql的:SUBSTR()/SUBSTRING().
所以不用改了
3)to_char(to_date(to_char(begintime,'yyyy-mm-dd'),'yyyy-mm-dd')+7,'yyyy-mm-dd') >= to_char(to_date(to_char(process_time,'yyyy-mm-dd'),'yyyy-mm-dd'),'yyyy-mm-dd')
不就判断两个日期是否相差7天,最后还用字符串字典排序比较,真tm费劲.
Mysql替代方案:
DATE_ADD/ ADDDATE
DATE_FORMAT(DATE_ADD(begintime,INTERVAL 7 DAY),'%Y-%m-%d') >= DATE_FORMAT(process_time,'%Y-%m-%d ')
oracle写法:add_months
ADD_MONTHS返回一个加上加上整数月的日期
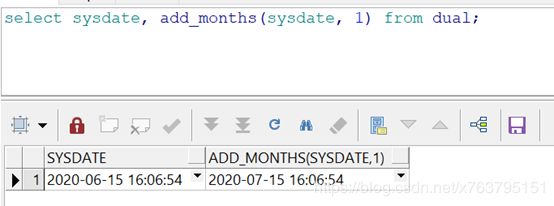
mysql替代方案:DATE_ADD/ ADDDATE
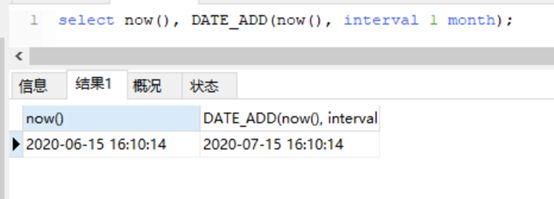
这里的sysdate就用now()代替了,毕竟当前场景需要使用now()了。
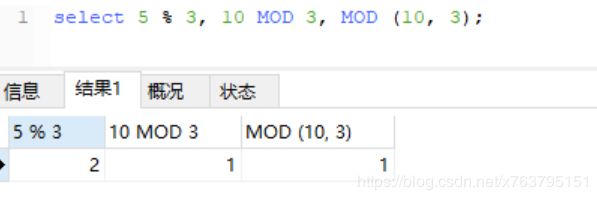
oracle写法:MOD
求余
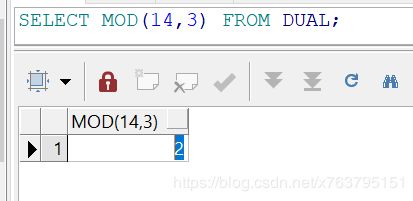
Mysql: MOD(N,M), N % M, N MOD M都可以,这里就不用改了
oracle写法:最后一个
oracle创建表的时候:其中有个字段
create table t_demo(
day NUMBER(2) default to_char(SYSDATE, 'dd')
)默认值 是当月的第几天,需要调用函数 。Mysql默认值 是不能调用函数的。
mysql替代方案:创建触发器
-- 创建 表t_demo 的触发器
CREATE TRIGGER t_demo BEFORE INSERT ON t_demo FOR EACH ROW
BEGIN
IF NEW.day IS NULL THEN
SET NEW.day = DATE_FORMAT(now(), '%d');
END
IF;
END;