Hadoop-zookeeper环境配置
安装包下载
链接:https://pan.baidu.com/s/10L21P0HvQBlTGVUdk86Nlw
提取码:xkkx
复制这段内容后打开百度网盘手机App,操作更方便哦
主机IP映射
[root@bigdata101 module]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 bigdata101
192.168.1.102 bigdata102
192.168.1.103 bigdata103
环境变量~/.bash_profile
[root@bigdata101 module]# vi ~/.bash_profile
JAVA_HOME=/opt/module/jdk1.8.0_221
ZK_HOME=/opt/module/zookeeper-3.4.7
HADOOP_HOME=/opt/module/hadoop-2.9.2
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$HOME/bin:$ZK_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH ZK_HOME CLASSPATH HADOOP_HOME
export HBASE_HOME=/opt/module/hbase-0.98.17-hadoop2
export PATH=$PATH:$HBASE_HOME/bin
一,zookeeper配置
1.bigdata101中解压zookeeper压缩包
[root@bigdata101 software]# tar -zxvf zookeeper-3.4.7.tar.gz -C /opt/module/
2.进入conf,然后cp zoo_sample.cfg zoo.cfg
[root@bigdata101 bin]# cd /opt/module/zookeeper-3.4.7/conf
[root@bigdata101 conf]# cp zoo_sample.cfg zoo.cfg
3.修改zoo.cfg配置
[root@bigdata101 conf]# vi zoo.cfg
dataDir= /opt/module/zookeeper-3.4.7/DataZk
server.1=bigdata101:2888:3888
server.2=bigdata102:2888:3888
server.3=bigdata103:2888:3888
4.创建 /opt/module/zookeeper-3.4.7/DataZk
[root@bigdata101 zookeeper-3.4.7]# mkdir DataZk
5.创建文件myid echo 1 > myid
[root@bigdata101 zookeeper-3.4.7]# cd DataZk/
[root@bigdata101 DataZk]# echo 1 > myid
[root@bigdata101 DataZk]# cat myid
1
[root@bigdata101 DataZk]#
6.复制到另外两个节点:scp -r 路径 root@bigdata101,102:路径
[root@bigdata101 module]# scp -r /opt/module/zookeeper-3.4.7/ bigdata102:/opt/module
[root@bigdata101 module]# scp -r /opt/module/zookeeper-3.4.7/ bigdata103:/opt/module
7.修改bigdata102 bigdata103 服务器myid :2 3 (对应zoo.cfg的server)
[root@bigdata102 module]# cd /opt/module/zookeeper-3.4.7/DataZk/
[root@bigdata102 DataZk]# vi myid
[root@bigdata102 DataZk]# cat myid
2
[root@bigdata103 module]# cd /opt/module/zookeeper-3.4.7/DataZk/
[root@bigdata103 DataZk]# vi myid
[root@bigdata103 DataZk]# cat myid
3
8. 三台启动 zkServer.sh start
[root@bigdata101 module]# cd /opt/module/zookeeper-3.4.7/bin
[root@bigdata101 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@bigdata101 bin]#
9.三台都启动后查看状态:./zkServer.sh status
[root@bigdata101 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
[root@bigdata101 bin]#
[root@bigdata102 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: leader
[root@bigdata102 bin]#
[root@bigdata103 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
[root@bigdata103 bin]#
二,hadoop配置
1.将hadoop压缩包解压
[root@bigdata101 software]# tar -zxvf hadoop-2.9.2.tar.gz -C /opt/module/
2.修改 hadoop-env.sh 文件
[root@bigdata101 software]# cd /opt/module/hadoop-2.9.2/etc/hadoop/
[root@bigdata101 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_221
export HADOOP_HOME=/opt/module/hadoop-2.9.2
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
3.配置core-site.xml
fs.defaultFS
hdfs://ns
ha.zookeeper.quorum
bigdata101:2181,bigdata102:2181,bigdata103:2181
hadoop.tmp.dir
/opt/module/hadoop-2.9.2/tmp
4.hdfs-site.xml
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
bigdata101:9000
dfs.namenode.http-address.ns.nn1
bigdata101:50070
dfs.namenode.rpc-address.ns.nn2
bigdata102:9000
dfs.namenode.http-address.ns.nn2
bigdata102:50070
dfs.namenode.shared.edits.dir
qjournal://bigdata101:8485;bigdata102:8485;bigdata103:8485/ns
dfs.journalnode.edits.dir
/opt/module/hadoop-2.9.2/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.namenode.name.dir
file:///opt/module/hadoop-2.9.2/tmp/namenode
dfs.datanode.data.dir
file:///opt/module/hadoop-2.9.2/tmp/datanode
dfs.replication
3
dfs.permissions
false
5.配置mapred-site.xml
需要cp mapred模板
[root@bigdata101 hadoop]# cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
bigdata101:10020
MapReduce JobHistory Server IPC host:port
mapreduce.jobhistory.webapp.address
bigdata101:19888
MapReduce JobHistory Server Web UI host:port
mapreduce.jobhistory.done-dir
/history/done
mapreduce.jobhistory.intermediate-done-dir
/history/done_intermediate
6.配置yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
bigdata101
yarn.resourcemanager.hostname.rm2
bigdata102
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk-address
bigdata101:2181,bigdata102:2181,bigdata103:2181
For multiple zk services, separate them with comma
yarn.resourcemanager.cluster-id
yarn-ha
yarn.resourcemanager.hostname
bigdata101
yarn.nodemanager.aux-services
mapreduce_shuffle
7.创建tmp和journa
[root@bigdata101 hadoop-2.9.2]# mkdir journal
[root@bigdata101 hadoop-2.9.2]# mkdir tmp
[root@bigdata101 hadoop-2.9.2]# cd tmp/
[root@bigdata101 tmp]# mkdir namenode datanode
[root@bigdata101 tmp]# ls
datanode namenode
8.在slaves中指定 datanode节点
bigdata101
bigdata102
bigdata103
9.将hadoop复制到其他节点
scp -r /opt/module/hadoop-2.9.2/ bigdata102:/opt/module
scp -r /opt/module/hadoop-2.9.2/ bigdata103:/opt/module
10.执行 source hadoop-env.sh,让配置生效----3台
[root@bigdata101 module]# cd /opt/module/hadoop-2.9.2/etc/hadoop/
[root@bigdata101 hadoop]# source hadoop-env.sh
三,启动Hadoop HA 高可用 zookeeper
注意:下面1,2两个步骤在安装 zookeeper 时,已经执行,验证,不需要再执行一次
1、启动zookeeper
[root@bigdata101 hadoop]# cd /opt/module/zookeeper-3.4.7/bin
[root@bigdata101 bin]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@bigdata102 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@bigdata103 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2、三台都启动后查看状态:./zkServer.sh status
[root@bigdata101 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
[root@bigdata102 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: leader
[root@bigdata103 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
3.启动格式化zookeeper:bigdata101
[root@bigdata101 bin]# hdfs zkfc -formatZK

四、启动hadoop,使用参考第二次启动
1、启动journalNode集群,在三个节点都上输入
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
[root@bigdata101 bin]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-journalnode-bigdata101.out
[root@bigdata102 bin]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-journalnode-bigdata102.out
[root@bigdata103 bin]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-journalnode-bigdata103.out
2、在 namenode 且 选为leader 的机器上,进行格式化,bigdata102选为 leader,杀死进程QuorumPeerMain(3台),重新执行 zkServer.sh start
注意:第二次执行不用格式化
hdfs namenode -format

3、启动master节点的namenode(active),在bigdata101上输入
[root@bigdata101 bin]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-namenode-bigdata101.out
4、设置bigdata102为备用节点,在bigdata102上输入
hdfs namenode -bootstrapStandby

5、启动bigdata102的namenode(备用),在bigdata102上输入
[root@bigdata102 bin]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-namenode-bigdata102.out
6、启动所有的datanode,在bigdata101上输入
[root@bigdata101 bin]# hadoop-daemons.sh start datanode
bigdata103: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-bigdata103.out
bigdata102: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-bigdata102.out
bigdata101: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-bigdata101.out
7、在bigdata101和bigdata102启动zkfc,在这两个节点上输入
[root@bigdata101 bin]# hadoop-daemon.sh start zkfc
zkfc running as process 7392. Stop it first.
[root@bigdata102 bin]# hadoop-daemon.sh start zkfc
starting zkfc, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-zkfc-bigdata102.out
启动成功后
[root@bigdata101 bin]# jps
7106 QuorumPeerMain
7746 ResourceManager
7844 NodeManager
7478 DataNode
8299 DFSZKFailoverController
7213 JournalNode
8334 Jps
[root@bigdata102 bin]# jps
7507 DFSZKFailoverController
7190 JournalNode
7577 Jps
7114 QuorumPeerMain
7295 NameNode
7391 DataNode
8、启动yarn,在bigdata101和bigdata102上输入
[root@bigdata101 bin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-resourcemanager-bigdata101.out
bigdata103: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-bigdata103.out
bigdata102: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-bigdata102.out
bigdata101: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-bigdata101.out
9、在本地电脑上做映射C:\Windows\System32\drivers\etc
192.168.1.101 bigdata101
192.168.1.102 bigdata102
192.168.1.103 bigdata103
10、主备namenode 切换 需要下载包
[root@bigdata101 bin]# yum -y install psmisc
11、在浏览地址上输入
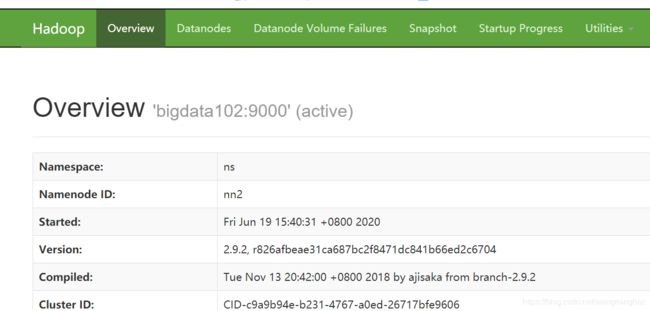
http://192.168.1.101:50070/
http://192.168.1.102:50070/

命令集合
启动zookeeperzkServer.sh start
关闭zookeeperzkServer.sh stop
查询zookeeper 状态zkServer.sh status
启动datanodehadoop-daemon.sh start datanode
永久关闭防火墙systemctl disable firewalld.service
本次关闭防火墙systemctl stop firewalld.service关闭防火墙,重启后失效
格式化namnodehdfs namenode -format
格式化zookeeperhdfs zkfc -formatZK
关闭hadoop安全模式hdfs dfsadmin -safemode leave
删除hadoop下的hbase目录hadoop fs -rm -r /hbase
删除文件 rm -rf 文件名
复制zookeeper包到其它节点scp -r /opt/module/zookeeper-3.4.7/ bigdata102:/opt/module
第二次开启顺序
./zkServer.sh start :101 102 103
hadoop-daemon.sh start namenode :101
hdfs namenode -bootstrapStandby :102
hadoop-daemon.sh start namenode :102
hadoop-daemons.sh start datanode :101
hadoop-daemon.sh start zkfc :101 102
start-yarn.sh :103
start-yarn.sh :101 102
start-hbase.sh :101