leetcode链表面试题目集锦
本文系转载,出处信息
作者:Mr希灵
链接:https://www.jianshu.com/p/f0c3235369ac
來源:简书
1.链表
链表是最基本的数据结构,面试官也常常用链表来考察面试者的基本能力,而且链表相关的操作相对而言比较简单,也适合考察写代码的能力。链表的操作也离不开指针,指针又很容易导致出错。综合多方面的原因,链表题目在面试中占据着很重要的地位。
1.1定义
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
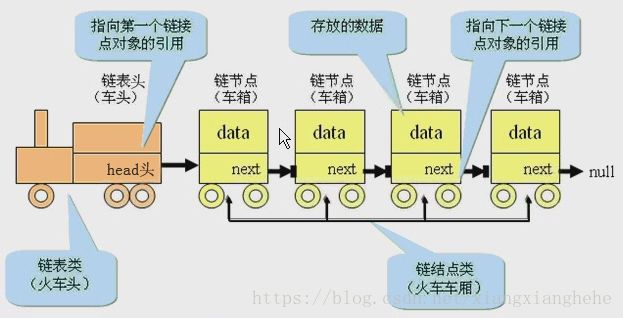
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。
1.2声明
链表结点声明如下:
struct ListNode
{
int value;
ListNode * next;
ListNode(int x) : value(x), next(NULL) {}
};1.3求单链表中结点的个数
这是最基本的了,应该能够迅速写出正确的代码,遍历所有节点直到指针域为NULL, 注意检查链表是否为空。时间复杂度为O(n).
int GetListLenght(ListNode* head)
{
if(head == NULL) return 0;
ListNode* current = head;
int len = 0;
while(current != NULL)
{
len++;
current = current->next;
}
return len;
}
1.4单链表反转 (leetcode 206)
新建一个头结点,遍历原链表,把每个节点用头结点插入到新建链表中。最后,新建的链表就是反转后的链表。时间复杂度为O(n).
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL非递归解法
起始状态:
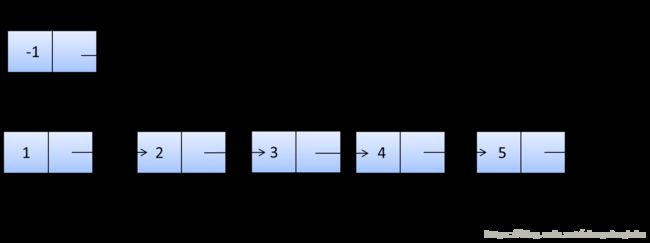
pCur是要插入到新链表的节点。
pNex是临时保存的pCur的next。
pNex保存下一次要插入的节点
把pCur插入到dummy中
纠正头结点dummy的指向
pCur指向下一次要插入的节点

ListNode* ReverseList(ListNode* head)
{
if(head == NULL || head->next == NULL) return head;
ListNode* reverseHead = NULL;
ListNode* current = head;
while(current != NULL) {
ListNode* temp = current;
current = current->next;
temp->next = reverseHead;
reverseHead = temp;
}
return reverseHead;
}
递归解法
这里直接贴代码:
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(head == nullptr || head->next == nullptr) return head;
ListNode *reverse = reverseList(head->next);//先反转后面的链表
head->next->next = head;//再将当前节点设置为后面节点的后续节点
head->next = nullptr;
return reverse;
}
};1.5 截取出单链表中的后K个结点(k>0)
使用两个指针,先让前面的指针走到正向第k个结点,这样前后两个指针的距离差是k-1,之后前后两个指针一起向前走,前面的指针走到最后一个结点时,后面指针所指就是后K个结点
ListNode* NthFromEnd(ListNode* head, int k){
if(head == NULL) return NULL;
ListNode* aHead = head,*behind = head;
while(k>1) {
aHead = aHead->next;
k--;
}
while(aHead->next != NULL){
behind = behind->next;
aHead = aHead->next;
}
return behind;
}1.6判断一个单链表中是否有环
如果一个链表中有环,也就是说用一个指针去遍历,是永远走不到头的。因此,我们可以用两个指针去遍历,一个指针一次走两步,一个指针一次走一步,如果有环,两个指针肯定会在环中相遇。时间复杂度为O(n)。
bool HasCycle(ListNode* head)
{
ListNode* fast = head,* slow = head;
while(fast != NULL && fast->next != NULL)
{
fast = fast->next->next;
slow = slow->next;
if(fast == slow)
return true;
}
return false;
}
1.7 去除有序链表中的重复元素(leetcode 83)
Given a sorted linked list,
delete all duplicates such that each element appear only once.
For example,
Given 1->1->2, return 1->2.
Given 1->1->2->3->3, return 1->2->3. 答案:
ListNode* deleteDuplicates(ListNode* head) {
if(head != nullptr)
{
ListNode* nodeA = head;
ListNode* nodeB = head->next;
while(nodeB != nullptr)
{
if(nodeA->val == nodeB->val){
nodeA->next = nodeB->next;
nodeB = nodeB->next;
}else{
nodeA = nodeB;
nodeB = nodeB->next;
}
}
}
return head;
}1.8 合并两个排好序的链表(leetcode 21)
将两个有序链表合并为一个新的有序链表并返回, 新链表是通过拼接给定的两个链表的所有节点组成的。

大体思路:可以使用递归来快速解决
1.判断L1,L2是否为空
2.创建一个头指针
3.判断当前L1,L2指向的节点值的大小.根据结果,让头指针指向小节点,并让这个节点往下走一步,作为递归函数调用的参数放入,返回的就是新的两个值的比较结果,则新的比较结果放入头结点的下一个节点.
4.返回头结点
代码如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode *head = NULL;
if(l1 == NULL) return l2;
if(l2 == NULL) return l1;
if(l1->val <= l2->val)
{
head = l1;
head->next = mergeTwoLists(l1->next,l2);
}
else
{
head = l2;
head->next = mergeTwoLists(l1,l2->next);
}
return head;
}
};1.9 链表的中间节点(leetcode 876)
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5,
以及 ans.next.next.next = NULL.思路:当用慢指针 slow 遍历列表时,让另一个指针 fast 的速度是它的两倍。当 fast 到达列表的末尾时,slow 必然位于中间.
class Solution {
public:
ListNode* middleNode(ListNode* head) {
ListNode* slow = head;
ListNode* fast = head;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
};1.10删除链表中的节点 (leetcode 237)
请编写一个函数,使其可以删除某个链表中给定的(非末尾)节点,你将只被给定要求被删除的节点。
输入: head = [4,5,1,9], node = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
链表至少包含两个节点。
链表中所有节点的值都是唯一的。
给定的节点为非末尾节点并且一定是链表中的一个有效节点。
不要从你的函数中返回任何结果。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
void deleteNode(ListNode *node) {
node->val = node->next->val;
node->next = node->next->next;
}
};1.11 删除链表的倒数第N个节点(leetcode 19)
这道题可以直接用双指针法求解: 一个指针先走N步,然后两个指针同步移动到链表末尾,移除前一个指针所指着的节点即可。
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n){
ListNode* right = head;
ListNode* left = head;
for (int i = 0; i < n; i++) {
right = right->next;
}
if (right == nullptr) {
head = head->next;
return head;
}
while (right->next != nullptr) {
left = left->next;
right = right->next;
}
left->next = left->next->next;
return head;
}
};1.12 删除链表中的节点(leetcode 203)
题目
删除链表中等于给定值 val 的所有节点。
示例
输入: 1->2->6->3->4->5->6, val = 6
输出: 1->2->3->4->5链表里面的元素删除,其实就是指针指向下一个元素就ok了,直接上code:
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
if(!head) return head;
while(head&&head->val == val){
head = head->next;
}
ListNode *tmp = head;
while (tmp&&tmp->next) {//判断后一节点是否存在
if (tmp->next->val == val) {
tmp->next = tmp->next->next; //删除操作 tmp.next 指向 下下个节点, 完成删除
} else {
// 关键: 如果进行了删除操作,则后一个节点更新了,所以前驱节点不需要移动,否则前驱节点向后移动
tmp = tmp->next;
}
}
return head;
}
};