数据挖掘RapidMiner工具使用----决策树案例分析
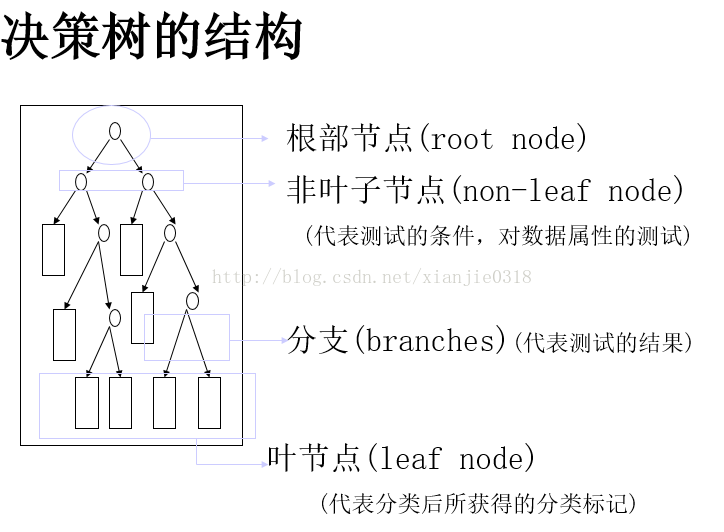
一、理解决策树
1、决策树简介
决策树方法在分类、预测、规则提取等领域有着广泛应用,它是一种归纳分类算法,它通过对训练集的学习,挖掘出有用的规则,用于对新集进行预测,是一种非参数学习算法。对每个输入使用由该区域的训练数据计算得到的对应的局部模型。 决策树是一树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。对于非纯的叶节点,多数类的标号给出到达这个节点的样本所属的类。构造决策树的核心问题是在每一步如何选择适当的属性对样本做拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下,分而治之的过程
2、决策树的基本原理
1)基本算法(贪心算法)
- 自上而下分而治之的方法
- 开始时,所有的数据都在根节点
- 属性都是离散值字段(如果是连续的,将其离散化)
- 所有记录用所选属性递归的进行分割
- 属性的选择是基于一个启发式规则或者一个统计的度量(如,information gain)
停止分割的条件
- 一个节点上的数据都是属于同一个类别
- 没有属性可以再用于对数据进行分割
2)了解决策树的具体算法
首先了解一下:信息熵的概念
信息熵是一个数学上颇为抽象的概念,在这里不妨把信息熵理解成某种特定信息的出现概率(离散随机事件的出现概率)。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。信息熵也可以说是系统有序化程度的一个度量。
计算公式
| 决策树算法 |
算法描述 |
| ID3算法 |
其核心是在决策树的各级节点上,使用信息增益方法作为属性的选择标准,来帮助确定生成每个节点时所应采用的合适属性。 |
| C4.5算法 |
C4.5决策树生成算法相对于ID3算法的重要改进是使用信息增益率来选择节点属性。C4.5算法可以克服ID3算法存在的不足:ID3算法只适用于离散的描述属性,而C4.5算法既能够处理离散的描述属性,也可以处理连续的描述属性。 |
| CART算法 |
CART决策树是一种十分有效的非参数分类和回归方法,通过构建树、修剪树、评估树来构建一个二叉树。当终结点是连续变量时,该树为回归树;当终结点是分类变量,该树为分类树。 |
(1) D3算法简介及基本原理
ID3算法基于信息熵来选择最佳测试属性。它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少不同取值就将样本集划分为多少子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的拆分,从而得到较小的决策树。
设S是s个数据样本的集合。假定类别属性具有m个不同的值:Ci(i=1,2,...,m)。设Si是类Ci中的样本数。对一个给定的样本,它总的信息熵为
其中,Pi是任意样本属于Ci的概率,一般可以用si/s估计。
设一个属性A具有k个不同的值{a1,a2,...,ak},利用属性A将集合S划分为k个子集{S1,S2,...,Sk},其中Sj包含了集合S中属性A取aj值的样本。若选择属性A为测试属性,则这些子集就是从集合S的节点生长出来的新的叶节点。设sij是子集Sj中类别为Ci的样本数,则根据属性A划分样本的信息熵值为
其中,
最后,用属性A划分样本集S后所得的信息增益(Gain)为
显然E(A)越小,Gain(A) 的值越大,说明选择测试属性A对于分类提供的信息越大,选择A之后对分类的不确定程度越小。属性A的 个不同的值对应的样本集 的 个子集或分支,通过递归调用上述过程(不包括己经选择的属性),生成其他属性作为节点的子节点和分支来生成整个决策树。ID3决策树算法作为一个典型的决策树学习算法,其核心是在决策树的各级节点上都用信息增益作为判断标准来进行属性的选择,使得在每个非叶节点上进行测试时,都能获得最大的类别分类增益,使分类后的数据集的熵最小。这样的处理方法使得树的平均深度较小,从而有效地提高了分类效率。
(2) ID3算法具体流程
ID3算法的具体详细实现步骤如下:
1) 对当前样本集合,计算所有属性的信息增益;
2) 选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集;
3) 若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。
二、实例——用决策树预测购买者类型
1、背景和概要说明
Richard 在一家大型网上零售公司工作。 他所在的公司即将推开下一代电子阅读器,并希望最大限度地提高营销活动的有效性。 他们有许多客户,其中有些客户购买过公司前几代数字阅读器中的其中一款产品。 Richard 注意到,在公司推出前一代产品时,有些人非常急于获得该产品,而其他人则似乎愿意等着过一段时间再购买。 他想知道是什么促使一些人在产品推出时立即抢购,而其他人的购买动力则要差一些。
Richard 所在的公司通过庞大的网站为新款电子阅读器提供特定产品和服务,借此推动这款电子阅读器的销售 - 例如,电子阅读器拥有者可以使用公司网站购买数字杂志、报纸、书籍、音乐等。 公司还销售数以千计其他类型的媒体,例如传统的印刷书籍以及各种电子产品。 Richard 相信通过挖掘与公司网站上的一般消费者行为有关的客户数据,他将能够确定哪些客户将最早购买新款电子阅读器,哪些客户次之,以及哪些客户将等着过一段时间再购买。 他希望通过预测客户何时准备好购买下一代电子阅读器,能够确定针对最有可能响应广告和促销活动的人员进行营销的时间。
2、业务理解
Richard 不仅希望能够预测购买行为发生的时间,还希望能够了解客户在公司网站上的行为如何表明购买新电子阅读器的时间。
Richard 相信他可以将公司的客户按以下四个最终将购买新款电子阅读器的群体进行分类: 创新者、早期采用者、早期主体采用者或晚期主体采用者。 这些群体符合Richard 对于公司前一代产品采用速度的非正式观察。 他希望通过观察客户在公司网站上的活动,可以大概预测每个人最有可能购买电子阅读器的时间。 他认为数据挖掘可以帮助他确定哪些活动是用于预测客户将归于哪个类别的最佳预测因子。 知道这一点后,他可以确定根据购买可能性针对每个客户进行营销的时间。
3、数据理解
Richard 请我们帮助他开展该项目。 我们决定使用决策树模型来找出用于预测购买行为的有效预测因子。 因为 Richard 所在的公司通过网站开展所有业务,所以拥有一个丰富的数据集,其中包含每个客户的信息,例如他们最近浏览的是什么产品,以及他们已实际购买什么产品。 他为我们准备了两个数据集。 训练数据集包含已购买公司前一代阅读器的客户在公司网站上的活动,以及他们购买阅读器的时间。 第二个数据集包含Richard 希望其购买新款电子阅读器的当前客户的属性。 他希望根据训练数据集中所包含人员的特征和购买时间,确定检验数据集中的每个人将归于哪个采用者类别。
在分析数据集时,Richard 发现客户在数字媒体和书籍方面的活动,以及在公司网站上所销售电子产品方面的一般活动,都同人们在购买电子阅读器时的活动有许多共同之处。 在牢记这一点的情况下,我们和 Richard 合作编制了包含以下属性的数据集:
User_ID: 为在公司网站上拥有帐户的每个人指定的具有唯一性的数字识别码。
Gender: 客户的性别,参考客户帐户而定。 在此数据集中,使用“M”表示男性,使用“F”表示女性。Decision Tree 操作符可以处理非数字数据类型。
Age: 从公司网站的数据库中提取数据时相应人员的年龄。 按系统日期与帐户中记录的相应人员的生日之间的时间差计算,并按四舍五入的方式精确到整数。
Marital_Status: 帐户中记录的相应人员的婚姻状况。 在帐户中表示自己已婚的人员在数据集中被输入为“M”。由于公司网站没有区分人员的单身类型,因此离异与丧偶的人士同一直单身的人士被归为了一类(在数据集中使用“S”表示)。
Website_Activity: 该属性用于表示每个客户在公司网站上的活跃程度。 通过与 Richard 合作,我们使用公司网站数据库中记录每个客户访问公司网站时持续时间的信息,来计算客户使用公司网站的频度和每次的持续时间。 然后这会转换为以下其中一个类别: 很少访问、定期访问或频繁访问。
Browsed_Electronics_12Mo: 一个内容为 Yes/No 的列,用于表示相应人员在过去的一年中是否曾在公司网站上浏览电子产品。
Bought_Electronics_12Mo: 另一个内容为 Yes/No 的列,用于表示他们在过去的一年中是否曾通过 Richard 公司的网站购买电子产品。
Bought_Digital_Media_18Mo: 一个内容为 Yes/No 的字段,用于表示相应人员在过去的一年半中是否曾购买过某种形式的数字媒体(例如 MP3 音乐)。 该属性不包括购买数字书籍。
Bought_Digital_Books: Richard 认为,作为与公司新款电子阅读器相关的购买行为指标,该属性有可能是最佳指标。 因此,我们将该属性与购买其他类型的数字媒体区分开来。 此外,该属性用于表示客户是否曾购买过数字书籍,而不仅仅只限于过去一年左右的时间。
Payment_Method: 表示相应人员的付款方式。 如果相应人员曾采用多种方式付款,则使用众值,或最常使用的付款方式。 该属性有四个选项:
– 银行转账 - 通过电子支票或其他电汇形式由银行直接向公司付款。
– 网站帐户 - 客户在其帐户中设置了一个信用卡或永久性电子资金转帐,以便在购物时直接通过帐户划拨。
– 信用卡 - 相应人员每次通过公司网站购物时,都输入信用卡卡号和授权码。
– 月结账单 - 相应人员会定期购物,并会收到稍后通过邮寄支票或通过公司网站付款系统支付的纸质或电子账单。
eReader_Adoption: 该属性仅在训练数据集中存在。 其中包含与购买前一代电子阅读器的客户有关的数据。 在产品发布后一周内购买的人员在此属性中被记录为“Innovator”。 在第一周之后但在第二到第三周之内购买的人员被输入为“Early Adopter”。 在第三周之后但在前两个月之内购买的人员为“Early Majority”。 在前两个月之后购买的人员为“Late Majority”。 将训练数据应用于检验数据时,此属性将用作标签。
4、操作步骤
决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树算法构造决策树来发现数据中蕴涵的分类规则.如何构造精度高、规模小的决策树是决策树算法的核心内容。决策树构造可以分两部分进行。第一部分,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。第二部分,决策树的剪技:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修正的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预测准确性的分枝剪除。
首先:导入数据
分为两个部分,一部分为:训练数据集-训练数据.xlsx,另外一部分:测试数据集,分别导入RapidMiner 数据存储库中,保存路径//Local Repository/data/,
导入数据

导入数据后,对数据进行简单的视觉评估:缺失、失真数据、异常值等
然后,数据预处理
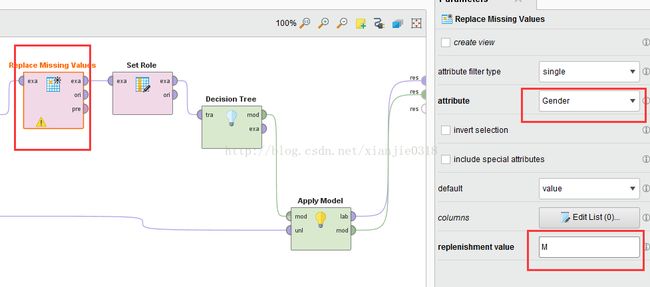
若存在缺失值,通过左侧的‘Cleansing’数据清洗操作符:“Peplace Missing Value”操作符进行处理,这里替换单一属性,Gender为空时,默认回填M值
若需要数据过滤,通过左侧的‘Blending’操作符:“Filter Example”操作符添加过滤条件,增加过滤条件
Gender等于M

...........等等
其次,角色设置
用户ID是用来唯一标示用户的,对于模型预测分析没有关系,因此它不应该作为变量包含在模型里面,我们把用户ID的角色设置为id。
调用“Set Role”操作符,和训练数据输出端链接,在参数设置界面里,属性名称选为“User_ID”,“target role”设置为id角色,对于测试数据集也重复同样操作
另外,在训练数据集中“购买时间”的字段,是一个“label”类型的字段,我们需要对它指定为标签类型,以便后面在用到决策树模型学习的时候,知道它是一个标记属性,在参数设置里的“Edit List”中,可以增加更多的角色设置,我们在其中对“eReader_Adoption”设置为“label”属性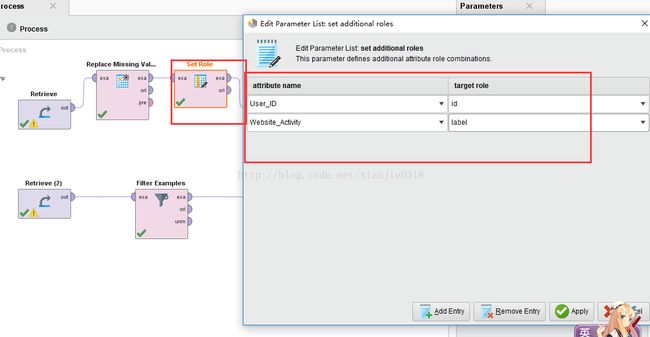
依次,加载决策树
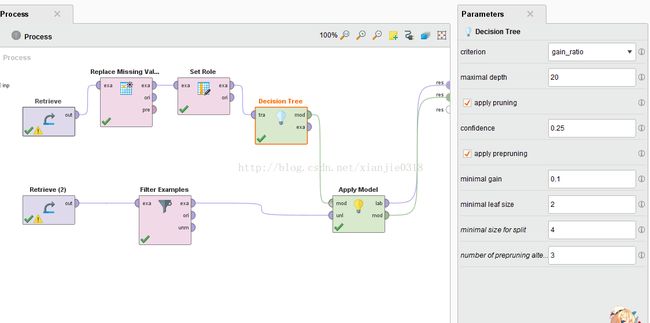
找到“Decision Tree”决策树操作符,并将其拖拽到训练数据集的连接线上,这个模型在运行的时候就能够自动输出到结果输出端
各参数说明
criterion: 为选择的属性和数值分裂指定使用的标准
minimal size for split: 允许分裂的节点的最小尺寸
minimal leaf size: 树叶的最小尺寸
minimal gain: 为了产生一个分裂必须达到的最小增益
maximal depth: 树的最大深度(-1:无边界)
confidence: 用于修剪的封闭式错误计算的置信度等级
number of prepruning alternatives: 当预先修剪将阻止一个分裂时,可选择的节点数
no pre pruning: 禁止提前修剪,并提供一个没有任何预修剪的树
no pruning: 禁止修剪,并提供一个未修剪的树
决策树的默认criterion是gain_radio(增益率)
运行流程
点击运行按钮,我们可以看到生成决策树图形
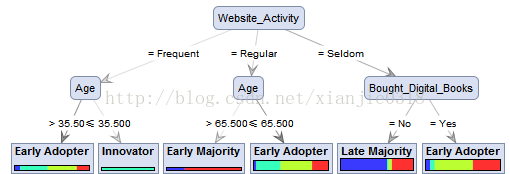
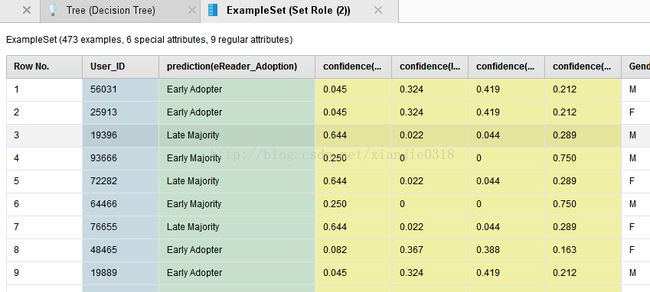
在左面的图形面板中,可以对树状图形进行缩放,调整树枝的位置等等。在图中,圆角的矩形中表示的是节点,末端的指教矩形表示的是树叶;节点(网站活跃度,是否购买过电子书籍、年龄)用来预测标签属性,从上到下,敏感度逐级降低;在末端的叶子节点,表示的预测的类别结果(选取概率最大的类别作为预测类别)。
我们需要用到“Apply Model”应用模型操作符,将其与决策树操作符进行连接,将测试数据集输出端与应用模型操作符的输入端连接,然后把应用模型的预测结果与输出端连接,这样我们的预测模型就搭建好了,点击运行按钮,我们发现决策树为我们创建了新的属性字段,显示了预测结果,以及各个类别的概率,他会用概率最高的来作为最终的结论如图