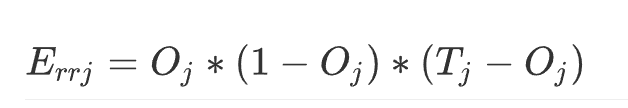数据分析
数据分析
1、numpy:多维数组的创建
多维数组(矩阵ndarray)
ndarray的基本属性
shape 维度的大小
ndim维度的个数
dtype数据类型
1.1 随机抽样创建
1.1.1 rand
生成指定维度的随机多维度浮点型数组,区间范围是[0,1)
Create an array of the given shape and populate it with
random samples from a uniform distribution
over ``[0, 1)``.
nd1 = np.random.rand(1,1)
print(nd1)
print('维度的个数',nd1.ndim)
print('维度的大小',nd1.shape)
print('数据类型',nd1.dtype) #float 64
展示
[[[0.6692067 0.2720613 0.51154113 0.82428366 0.46295541]
[0.90008085 0.32678138 0.22799996 0.01463876 0.91932592]
[0.94994095 0.1005888 0.97856803 0.95835044 0.4232734 ]
[0.55823696 0.67435857 0.80571127 0.31125564 0.51347285]]
[[0.79288383 0.87991494 0.36959603 0.83993517 0.44854427]
[0.29233904 0.21511221 0.23838737 0.31218621 0.01570319]
[0.63118773 0.6943842 0.42748468 0.55841017 0.58764804]
[0.65398815 0.58153545 0.57424707 0.49788028 0.54942051]]
[[0.9069376 0.4375912 0.12404622 0.73877842 0.91480335]
[0.37166892 0.13312303 0.12471981 0.8086709 0.72126696]
[0.93126097 0.11578659 0.82806954 0.91416224 0.93896591]
[0.78597169 0.46466087 0.0921524 0.11408107 0.15356255]]]
维度的个数 3
维度的大小 (3, 4, 5)
数据类型 float64
###################
1.1.2 uniform
def uniform(low=0.0, high=1.0, size=None): # real signature unknown; restored from __doc__
"""
uniform(low=0.0, high=1.0, size=None)
Draw samples from a uniform distribution.
Samples are uniformly distributed over the half-open interval
``[low, high)`` (includes low, but excludes high). In other words,
any value within the given interval is equally likely to be drawn
by `uniform`.
Parameters
----------
low : float or array_like of floats, optional
Lower boundary of the output interval. All values generated will be
greater than or equal to low. The default value is 0.
high : float or array_like of floats
Upper boundary of the output interval. All values generated will be
less than high. The default value is 1.0.
size : int or tuple of ints, optional
Output shape. If the given shape is, e.g., ``(m, n, k)``, then
``m * n * k`` samples are drawn. If size is ``None`` (default),
a single value is returned if ``low`` and ``high`` are both scalars.
Otherwise, ``np.broadcast(low, high).size`` samples are drawn.
Returns
-------
out : ndarray or scalar
Drawn samples from the parameterized uniform distribution.
See Also
--------
randint : Discrete uniform distribution, yielding integers.
random_integers : Discrete uniform distribution over the closed
interval ``[low, high]``.
random_sample : Floats uniformly distributed over ``[0, 1)``.
random : Alias for `random_sample`.
rand : Convenience function that accepts dimensions as input, e.g.,
``rand(2,2)`` would generate a 2-by-2 array of floats,
uniformly distributed over ``[0, 1)``.
Notes
-----
The probability density function of the uniform distribution is
.. math:: p(x) = \frac{1}{b - a}
anywhere within the interval ``[a, b)``, and zero elsewhere.
When ``high`` == ``low``, values of ``low`` will be returned.
If ``high`` < ``low``, the results are officially undefined
and may eventually raise an error, i.e. do not rely on this
function to behave when passed arguments satisfying that
inequality condition.
Examples
--------
Draw samples from the distribution:
>>> s = np.random.uniform(-1,0,1000)
All values are within the given interval:
>>> np.all(s >= -1)
True
>>> np.all(s < 0)
True
Display the histogram of the samples, along with the
probability density function:
>>> import matplotlib.pyplot as plt
>>> count, bins, ignored = plt.hist(s, 15, normed=True)
>>> plt.plot(bins, np.ones_like(bins), linewidth=2, color='r')
>>> plt.show()
"""
pass
nd = np.random.uniform(2)
nd2 = np.random.uniform(-1,5,size=(2,3))
print(nd2)
print(type(nd2))
print(nd2.ndim)
print(nd2.dtype)
print(nd2.shape)
展示:
[[3.59873373 2.60052091 0.45326737]
[2.87653583 2.15374128 3.38291766]]
2
float64
(2, 3)
1.1.3 randint
def randint(low, high=None, size=None, dtype='l'): # real signature unknown; restored from __doc__
"""
randint(low, high=None, size=None, dtype='l')
Return random integers from `low` (inclusive) to `high` (exclusive).
Return random integers from the "discrete uniform" distribution of
the specified dtype in the "half-open" interval [`low`, `high`). If
`high` is None (the default), then results are from [0, `low`).
Parameters
----------
low : int
Lowest (signed) integer to be drawn from the distribution (unless
``high=None``, in which case this parameter is one above the
*highest* such integer).
high : int, optional
If provided, one above the largest (signed) integer to be drawn
from the distribution (see above for behavior if ``high=None``).
size : int or tuple of ints, optional
Output shape. If the given shape is, e.g., ``(m, n, k)``, then
``m * n * k`` samples are drawn. Default is None, in which case a
single value is returned.
dtype : dtype, optional
Desired dtype of the result. All dtypes are determined by their
name, i.e., 'int64', 'int', etc, so byteorder is not available
and a specific precision may have different C types depending
on the platform. The default value is 'np.int'.
.. versionadded:: 1.11.0
Returns
-------
out : int or ndarray of ints
`size`-shaped array of random integers from the appropriate
distribution, or a single such random int if `size` not provided.
See Also
--------
random.random_integers : similar to `randint`, only for the closed
interval [`low`, `high`], and 1 is the lowest value if `high` is
omitted. In particular, this other one is the one to use to generate
uniformly distributed discrete non-integers.
Examples
--------
>>> np.random.randint(2, size=10)
array([1, 0, 0, 0, 1, 1, 0, 0, 1, 0])
>>> np.random.randint(1, size=10)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
Generate a 2 x 4 array of ints between 0 and 4, inclusive:
>>> np.random.randint(5, size=(2, 4))
array([[4, 0, 2, 1],
[3, 2, 2, 0]])
"""
pass
print('############################')
nd3 = np.random.randint(1,20,size=(3,4))
print(nd3)
展示:
############################
[[ 4 15 10 5]
[11 11 2 4]
[ 6 1 16 19]]
注意点:
1、如果没有指定最大值,只是指定了最小值,范围是[0,最小值)
2、如果有最小值,也有最大值[最小值,最大值)
1.2 序列创建
1.2.1 array
通过列表进行创建
nd4 = np.array([1,2,3])
[1 2 3]
通过列表嵌套列表创建
nd5 = np.array([[1,2,3],[4,5]])
[list([1, 2, 3]) list([4, 5])]
综合
nd4 = np.array([1,2,3])
nd5 = np.array([[1,2,3],[4,5,6]])
print(nd4)
print(nd4.ndim)
print(nd4.shape)
print(nd5)
print(nd5.ndim)
print(nd5.shape)
[1 2 3]
1
(3,)
[[1 2 3]
[4 5 6]]
2
(2, 3)
1.2.2 zeros
print(np.zeros((4,4)))
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
注意点:
1、创建的数组里面的数据为0
2、默认的数据类型是float
3、可以指定其他的数据类型
1.2.3 ones
1.2.4 arange
nd6 = np.arange(10)
print(nd6)
nd7 = np.arange(0,10)
print(nd7)
nd8 = np.arange(0,10,2)
print(nd8)
展示
##################
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 2 4 6 8]
注意点:
1、只填写一位数[0,这位)
2、填写两位[最低位,最高位)
3、填写3位数[最低位,高位,步长)
4、创建的是一维数组
5、等同于np.array(range())
1.3 数组重新排列
print('##########################')
nd9 = np.arange(10)
print(nd9)
nd10 = nd9.reshape(2,5)
print(nd10)
print(nd9)
展示:
##########################
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
[0 1 2 3 4 5 6 7 8 9]
注意点:
1、有返回值,返回新的数组,原始数组不受影响
2、进行维度大小的设置的过程中,要注意数据的个数,注意元素的个数
print('###################')
nd11 = np.arange(10)
print(nd11)
nd12 = np.random.shuffle(nd11)
print(nd12)
print(nd11)
展示
###################
[0 1 2 3 4 5 6 7 8 9]
None
[5 6 1 8 7 9 2 4 0 3]
注意点:
1、在原始数据集上做的操作
2、将原始数组的元素进行重新排列,打乱顺序
3、shuffle这个没有返回值
两个可以配合使用,先打乱,再重新排列
1.4 数据类型的转换
####1.4.1 数组的数据类型
数组的object类型:
class Dog(object):
pass
dog1=Dog()
dog2=Dog()
np.array([dog1,dog2])
print(arr20)
print(arr20,dtype)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3dQbmJn7-1576206861905)(C:\Users\Administrator\Desktop\PAI0408\1572944520802.png)]
数组的int类型:
arr21=np.array([1,2,3])
print(arr21)
print(arr21.dtype)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VxXCKuD4-1576206861907)(C:\Users\Administrator\Desktop\PAI0408\1572944700390.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hnuqgktU-1576206861907)(C:\Users\Administrator\Desktop\PAI0408\1572944927945.png)]
数组的Unicode类型:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60WwH4j7-1576206861907)(C:\Users\Administrator\Desktop\PAI0408\1572944902207.png)]
1.4.2 转换
print('########################')
nd13 = np.arange(10,dtype=np.int64)
print(nd13)
nd14 = nd13.astype(np.float64)
print(nd14)
print(nd13)
注意点:
1、astype()不在原始数组做操作,有返回值,返回的是更改数据类型的新数组
2、在创建新数组的过程中,有dtype参数进行指定
1.5 数组转列表
print(list(arr1))
print(arr1.tolist())
2、numpy的矩阵计算
2.1 一维数组与一维数组
arr1 = np.arange(1,6)
arr2 = np.array([10,20,30,40,50])
print(arr1)
print(arr2)
print(arr1+arr2)
展示:
[1 2 3 4 5]
[10 20 30 40 50]
[11 22 33 44 55]
注意点:
1、一维数组的元素个数是相同的,不然无法完成广播
2、按照数组对应的下标来进行算术运算,返回一个新的数组,同时保证数组的元素是一致的、
2.2 一维数组与多维数组
arr4 = arr2.reshape((2,5))
print(arr4)
print('相乘')
print(arr4*arr3)
print('与单独的一个数据')
print(arr4*100.0)
arr5 = np.array([0,1,2,3,4,5])
print(arr4+arr5)
注意点:
1、元素的个数必须相同(一维数组的元素个数必须与多维数组的列的元素个数一致的)
2.3 多维与多维
#转多维数组
arr3 = arr1.reshape((2,5))
print(arr3)
arr4 = arr2.reshape((2,5))
print(arr4)
print('相乘')
print(arr4*arr3)
print('与单独的一个数据')
注意点:
数组的维度大小必须是一致的
2.4 数组与单独的一个数据
print('与单独的一个数据')
print(arr4*100.0)
3、索引与切片
3.1 一维数组
import numpy as np
arr1 = np.arange(10)
print('原始数组',arr1)
print('取单独的一个数据')
print(arr1[0])
print(arr1[-1])
print('取多个数据')
print(arr1[0:-1])
print(arr1[0:3])
注意点:
1、取单个数据,取下标,下标从0开始
2、取多个数据,:隔开,左闭右开
3、参考列表【起始位置:终点位置:步长】左闭右开
3.2 多维数组
print('#####取单独的一行######')
print(arr1[0])
print('#####取单独的一行中的一列(取单个元素)######')
print(arr1[0][-1])
print(arr1[0,-1])
arr1 = np.random.randint(0,99,(3,4))
print('原始数组',arr1)
print('######取单独的一列######')
print(arr1[:,2])
展示:
原始数组 [[24 65 37 70]
[46 84 67 37]
[55 68 75 15]]
######取单独的一列######
[37 67 75]
arr1 = np.random.randint(0,99,(3,4))
print('原始数组',arr1)
print('######取连续多行######')
print(arr1[0:2])
print('######取连续多行指定多列######')
print(arr1[0:2,0:2])
print('######取不连续多行######')
print(arr1[[0,2]])
print(arr1[[0,-1]])
展示
原始数组 [[ 1 16 77 15]
[24 62 88 83]
[60 50 52 4]]
######取连续多行######
[[ 1 16 77 15]
[24 62 88 83]]
######取连续多行指定多列######
[[ 1 16]
[24 62]]
######取不连续多行######
[[ 1 16 77 15]
[60 50 52 4]]
[[ 1 16 77 15]
[60 50 52 4
arr1 = np.random.randint(0,99,(3,4))
print('原始数组',arr1)
print('######取连续多行,不连续多列######')
print(arr1[0:2,[0,-1]])
print('######取不连续多行,不连续多列######')
print(arr1[[0,2],[0,-1]])
print('**************')
print(arr1[[0,2]][:,[0,-1]])
展示:
原始数组 [[43 56 1 95]
[43 89 76 16]
[15 67 64 52]]
######取连续多行,不连续多列######
[[43 95]
[43 16]]
######取不连续多行,不连续多列######
[43 52]
**************
[[43 95]
[15 52]]
3.3 条件索引
arr1 = np.array([
[2010,2011,2012],
[2013,2014,2015],
[2019,2018,2020]
])
print('原始数组',arr1)
print('##################')
print(arr1>2013)
print(arr1[arr1>20])
展示:
原始数组 [[2010 2011 2012]
[2013 2014 2015]
[2019 2018 2020]]
##################
[[False False False]
[False True True]
[ True True True]]
[2010 2011 2012 2013 2014 2015 2019 2018 2020]
注意点:
返回所有条件为真的数据,组合成了一个一维数组
arr1 = np.array([
[2010,2011,2012],
[2013,2014,2015],
[2019,2018,2020]
])
print('原始数组',arr1)
print('##################')
print(arr1>2013)
print(arr1[arr1>20])
print(arr1[(arr1>2013) & (arr1<2019)])
print(arr1[(arr1<=2013)|(arr1>2019)])
print('#########取闰年##########')
# 1、能被4整除但是不能被100整除2、能被400整除
print(arr1[((arr1%4==0)&(arr1%100!=0))|(arr1%400==0)])
4、通用函数(ufunc)
4.1 一元计算函数
import numpy as np
arr1 = np.random.uniform(-5,10,(3,4))
print(arr1)
print('向上取整')
print(np.ceil(arr1))
print('向下取整')
print(np.floor(arr1))
print('四舍五入')
print(np.rint(arr1))
print('取绝对值')
print(np.abs(arr1))
print('取反')
print(np.negative(arr1))
print(np.negative(-1))
print('平方')
print(np.square(arr1))
print('平方根')
print(np.sqrt(np.abs(arr1)))
print('分成小数与整数部分')
print(np.modf(arr1)[0])
print(np.modf(arr1)[1])
print('判断空值')
print(np.isnan(arr1))
展示:
[[-0.69587753 1.14875406 8.53686918 9.4968895 ]
[ 3.68639285 6.79418179 -0.44578217 -3.71251504]
[ 1.38537669 9.2594615 -4.54692681 8.64836814]]
向上取整
[[-0. 2. 9. 10.]
[ 4. 7. -0. -3.]
[ 2. 10. -4. 9.]]
向下取整
[[-1. 1. 8. 9.]
[ 3. 6. -1. -4.]
[ 1. 9. -5. 8.]]
四舍五入
[[-1. 1. 9. 9.]
[ 4. 7. -0. -4.]
[ 1. 9. -5. 9.]]
取绝对值
[[0.69587753 1.14875406 8.53686918 9.4968895 ]
[3.68639285 6.79418179 0.44578217 3.71251504]
[1.38537669 9.2594615 4.54692681 8.64836814]]
取反
[[ 0.69587753 -1.14875406 -8.53686918 -9.4968895 ]
[-3.68639285 -6.79418179 0.44578217 3.71251504]
[-1.38537669 -9.2594615 4.54692681 -8.64836814]]
1
平方
[[ 0.48424553 1.31963589 72.87813532 90.19091012]
[13.58949223 46.16090626 0.19872174 13.78276796]
[ 1.91926856 85.73762719 20.67454338 74.79427144]]
平方根
[[0.83419274 1.07179945 2.92179212 3.08170237]
[1.91999814 2.60656513 0.6676692 1.92678879]
[1.17702026 3.04293633 2.13235241 2.9408108 ]]
分成小数与整数部分
[[-0.69587753 0.14875406 0.53686918 0.4968895 ]
[ 0.68639285 0.79418179 -0.44578217 -0.71251504]
[ 0.38537669 0.2594615 -0.54692681 0.64836814]]
[[-0. 1. 8. 9.]
[ 3. 6. -0. -3.]
[ 1. 9. -4. 8.]]
判断空值
[[False False False False]
[False False False False]
[False False False False]]
注意点:
isnan这个函数,一般配合条件索引
4.2 二元计算函数
import numpy as np
# arr1 = np.random.uniform(-5,10,(3,4))
# print(arr1)
# print('向上取整')
# print(np.ceil(arr1))
# print('向下取整')
# print(np.floor(arr1))
# print('四舍五入')
# print(np.rint(arr1))
# print('取绝对值')
# print(np.abs(arr1))
# print('取反')
# print(np.negative(arr1))
# print(np.negative(-1))
# print('平方')
# print(np.square(arr1))
# print('平方根')
# print(np.sqrt(np.abs(arr1)))
# print('分成小数与整数部分')
# print(np.modf(arr1)[0])
# print(np.modf(arr1)[1])
# print('判断空值')
# print(np.isnan(arr1))
arr1 = np.arange(10).reshape((2,5))
arr2 = np.arange(10,20).reshape((2,5))
print('arr1',arr1)
print('arr2',arr2)
print('两个数组之间的相加操作')
print(np.add(arr1,arr2))
print('两个数组之间的相减')
print(np.subtract(arr1,arr2))
print('两个数组之间相除')
print(np.divide(arr1,arr2))
print(np.floor_divide(arr1,arr2)) #取整
print(np.mod(arr1,arr2)) #取余
print('元素相乘')
print(np.multiply(arr1,arr2))
展示:
arr1 [[0 1 2 3 4]
[5 6 7 8 9]]
arr2 [[10 11 12 13 14]
[15 16 17 18 19]]
两个数组之间的相加操作
[[10 12 14 16 18]
[20 22 24 26 28]]
两个数组之间的相减
[[-10 -10 -10 -10 -10]
[-10 -10 -10 -10 -10]]
两个数组之间相除
[[0. 0.09090909 0.16666667 0.23076923 0.28571429]
[0.33333333 0.375 0.41176471 0.44444444 0.47368421]]
[[0 0 0 0 0]
[0 0 0 0 0]]
[[0 1 2 3 4]
[5 6 7 8 9]]
元素相乘
[[ 0 11 24 39 56]
[ 75 96 119 144 171]]
注意点:
这些函数的参数可以是数字,也可以是数组
4.3 三元计算函数
arr1 = np.arange(10).reshape((2,5))
arr2 = np.arange(10,20).reshape((2,5))
print('1',arr1)
print('2',arr2)
print(np.where(arr1%2==0,arr1,100))
print('###################')
print(np.where(arr1>arr2,arr1,arr2))
list1 = arr1.tolist()
list2 = arr2.tolist()
print([x if x>y else y for x,y in zip(list1,list2)])
arr4 = np.random.uniform(10,50,(3,4))
# 四舍五入之后大于20小于30的数字,修改为100
print(np.where((np.rint(arr4)>20) & (np.rint(arr4)<30),100,arr4))
print(np.where(np.isnan(arr4),0,arr4))
4.4常用的元素统计函数
axis是指按照指定轴计算,0代表的是列,1代表的是行
np.mean() #求均值
np.sum() #求和
np.max() #最大值
np.min() #最小值
np.std() #标准差
np.var() #方差、
np.argmax() #最大值的下标索引
np.argmin() #最小值的下标索引
np.cumsum() #所有元素都是之前元素的累加,一维数组
np.cumprod() # 所有元素都是之前元素的累乘,一维数组
arr1 = np.arange(1,50).reshape(7,7)
print(arr1)
print('###################')
print(np.mean(arr1,axis=1)) #求均值
print(np.mean(arr1,axis=0)) #求均值
print(np.mean(arr1)) #求均值
print('###################')
print(np.sum(arr1)) #求和
print(np.max(arr1)) #最大值
print(np.min(arr1)) #最小值
print(np.std(arr1)) #标准差
print(np.var(arr1)) #方差、
print(np.argmax(arr1)) #最大值的下标索引
print(np.argmin(arr1)) #最小值的下标索引
print(np.cumsum(arr1)) #所有元素都是之前元素的累加,一维数组
print(np.cumprod(arr1)) # 所有元素都是之前元素的累乘,一维数组
4.5 判断函数
arr1 = np.random.randint(0,50,(4,4))
print(arr1)
np.all((arr1>0)&(arr1<100))
np.all(arr1>10,axis=1)
np.any(arr1>10)
np.any(arr1>10,axis=0)
注意点:
1、返回的是布尔值
2、all 需要元素全部符合,any至少一位满足
3、axis指定轴
5 、数组的增加、插入、删除、合并
append()
insert()
delete()
concatenate()
5.1 append()
import numpy as np
arr1 = np.arange(10,20)
arr2 = np.arange(20,30)
arr3 = np.arange(20).reshape(4,5)
arr4 = np.arange(20).reshape(4,5)
print(arr1)
print(arr2)
print(arr3)
print('##########append#####')
print('#######一维数组的append#####')
print(np.append(arr1,100))
print(np.append(arr3,100))
print(np.append(arr1,arr2))
print('%%%%%%%%%%%%%%%%%')
print(np.append(arr3,arr2))
print('****************')
print(np.append(arr3,arr4))
展示:
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
##########append#####
#######一维数组的append#####
[ 10 11 12 13 14 15 16 17 18 19 100]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 100]
[10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29]
%%%%%%%%%%%%%%%%%
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29]
****************
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 0 1 2 3
4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
注意点:
1、append是在数组的末尾做追加
2、append返回的是一个新数组,对于原来数据不做操作
3、多维数组追加一个数据,会返回一个一维数组
4、一维数组追加一维数组,返回一个一维数组
5.2 insert
print(np.insert(arr1,0,100))
print(np.insert(arr3,0,100))
print(np.insert(arr1,0,arr2))
print(np.insert(arr1,0,[100,200]))
print(np.insert(arr3,0,arr5,axis=0))
print(np.insert(arr3,0,arr6,axis=1))
注意点:
1、多维数组在指定位置上加入一个值,默认当做一位数组进行操作,返回的是一维数组
2、insert()参数整理
第一个参数表示需要操作的数组
第二个参数表示的是下标
第三个是需要插入的值
第四个表示的轴,0代表在每一列上增加数据,1代表在每一行上操作数据
3、需要插入的数据能在原始数据上做广播
5.3 delete
print(np.delete(arr1,0))
print(arr1)
print(np.delete(arr3,0,axis=0))
print('############')
print(arr3)
注意点:
1、一维数组删除单个元素
2、多维数组删除单个元素,会导致原始的结构发生变化,返回一维数组,所以一般情况下,配合axis指定行1(删除每一行的第几个元素,就是删除那一列)列0
###5.4 concatenate
print(np.concatenate((arr1,arr2)))
print(11111111111111)
print(np.concatenate((arr3,arr4),axis=0))
print(2222222222222222222)
print(np.concatenate((arr3,arr4),axis=1))
展示:
[10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29]
11111111111111
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
2222222222222222222
[[ 0 1 2 3 4 0 1 2 3 4]
[ 5 6 7 8 9 5 6 7 8 9]
[10 11 12 13 14 10 11 12 13 14]
[15 16 17 18 19 15 16 17 18 19]]
注意点:
1、一维数组合并,默认按照行
2、多维数组合并,axis=1 ,是指按照行合并,增加的是多列数据
3、多维数组合并,axis=0 ,是指按照列合并,增加对的是多行数据
6、数组的集合函数
import numpy as np
# s1 = {10,20,30,40}
# s2 = {10,100,20,200}
# #交集
# print(s1&s2)
# print(s1|s2)
arr1 = np.arange(10,20)
arr2 = np.arange(0,5)
arr3 = np.array([100,10,10,10,20,30,40,50,1])
print('##########数组去重,排序##########')
print(np.unique(arr3))
print('#####数组的交集####')
print(np.intersect1d(arr1,arr3))
print('######数组的并集###')
print(np.union1d(arr1,arr2))
print('###差集:arr1有,但是arr2没有的##')
print(np.setdiff1d(arr1,arr2))
print(np.setdiff1d(arr2,arr1))
print('#######对称差集:二者差集的集合#####')
print(np.setxor1d(arr1,arr3))
print(np.setxor1d(arr3,arr1))
print('#########判断是否包含元素###')
print(np.in1d(arr1,arr2))
展示:
##########数组去重,排序##########
[ 1 10 20 30 40 50 100]
#####数组的交集####
[10]
######数组的并集###
[ 0 1 2 3 4 10 11 12 13 14 15 16 17 18 19]
###差集:arr1有,但是arr2没有的##
[10 11 12 13 14 15 16 17 18 19]
[0 1 2 3 4]
#######对称差集:二者差集的集合#####
[ 1 11 12 13 14 15 16 17 18 19 20 30 40 50 100]
[ 1 11 12 13 14 15 16 17 18 19 20 30 40 50 100]
#########判断是否包含元素###
[False False False False False False False False False False]
7、数组排序
def sort(a, axis=-1, kind='quicksort', order=None):
"""
Return a sorted copy of an array.
注意点:
返回的是原始数据的复制版本排序之后的
def sort(self, axis=-1, kind='quicksort', order=None): # real signature unknown; restored from __doc__
"""
a.sort(axis=-1, kind='quicksort', order=None)
Sort an array, in-place.
Parameters
----------
axis : int, optional
Axis along which to sort. Default is -1, which means sort along the
last axis.
kind : {'quicksort', 'mergesort', 'heapsort'}, optional
Sorting algorithm. Default is 'quicksort'.
order : str or list of str, optional
When `a` is an array with fields defined, this argument specifies
which fields to compare first, second, etc. A single field can
be specified as a string, and not all fields need be specified,
but unspecified fields will still be used, in the order in which
they come up in the dtype, to break ties.
注意点:
在原始数据上做排序
8、文件读写
###8.1 保存npy,npz格式,数组保存二进制文件
import numpy as np
arr1 = np.arange(20).reshape(4,5)
np.save('a1',arr1)
#保存数组的二进制文件
#读取数组的二进制文件
arr2 = np.load('a1.npy')
print(arr2)
# np.savez()
import numpy as np
arr1 = np.arange(20).reshape(4,5)
arr2 = np.arange(20).reshape(4,5)
np.save('a1',arr1)
#保存数组的二进制文件
#读取数组的二进制文件
arr3 = np.load('a1.npy')
print(arr3)
np.savez('test',nd1=arr1,nd2=arr2)
arr4 = np.load('test.npz')
print('###########')
print(arr4['nd1'])
展示:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
###########
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
8.2 指定文件格式存储
arr1 = np.array([
['col1','col2','col3'],
['java','python','go'],
['mysql','redis','mongodb']
])
print(arr1)
np.savetxt('aaa.csv',arr1,delimiter=',',fmt='%s')
注意点:
def savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='',
footer='', comments='# ', encoding=None)
delimiter:分隔符,CSV文件需要指定','
fmt指定的是数据的格式 '%s' '%d' '%f'
arr2 = np.genfromtxt('aaa.csv',delimiter=',',dtype=str,usecols=(1,))
print(arr2)
fname, dtype=float, comments='#', delimiter=None,
usecols=None
usecols指定的是读取的列,下标从0 开始,如果元组,要使用','
##9、pandas—series
9.1 series对象
import pandas as pd
# series
ser_obj = pd.Series(data=list('asdf'))
print(ser_obj)
print(ser_obj.index)
print(ser_obj.values)
print('#########')
print(type(ser_obj.index))
print(type(ser_obj.values))
ser2 = pd.Series(np.random.randint(-5,50,10))
print(ser2)
展示:
0 a
1 s
2 d
3 f
dtype: object
RangeIndex(start=0, stop=4, step=1)
['a' 's' 'd' 'f']
#########
0 40
1 23
2 30
3 -5
4 10
5 41
6 41
7 35
8 10
9 29
dtype: int32
注意点:
series = index对象+ ndarray对象
9.2 series对象的参数
ser3 = pd.Series(data=['python','java','c++','go'],index=list('abcd'),dtype=str,name='ser1')
ser4 = pd.Series(data=[1,2,3,4],index=list('abcd'),dtype=str,name='ser2')
print(ser3)
print(ser4)
展示:
a python
b java
c c++
d go
Name: ser1, dtype: object
a 1
b 2
c 3
d 4
Name: ser2, dtype: object
9.3 创建series对象的方法
1、通过数组创建
ser2 = pd.Series(np.random.randint(-5,50,10))
2、通过列表
ser3 = pd.Series(data=['python','java','c++','go'],index=list('abcd'),dtype=str,name='ser1')
3、通过字典,字典的键作为index ,值作为values, int----->float------>object
print('############################')
ser5 = pd.Series(data={'name':'wang','age':18})
print(ser5)
10 、pandas-----DataFrame
10.1 创建dataframe对象
import numpy as np
import pandas as pd
df1 = pd.DataFrame(list('asdf'),columns=['M'])
print(df1)
print('%%%%%%%%%%%%%%%%%%')
df2 = pd.DataFrame(np.random.randint(10,100,(4,4)))
print(df2)
print('%%%%%%%%%%%%%%%%%')
dict_new = {
'names':['大王','wang2','wang3'],
'age':18,
'country':'中国',
}
df3 = pd.DataFrame(dict_new)
print(df3)
print(df3.dtypes)
print(df3.index)
print(df3.columns)
展示:
M
0 a
1 s
2 d
3 f
%%%%%%%%%%%%%%%%%%
x y z z2
0 36 67 88 20
1 69 43 86 37
2 68 79 22 11
3 59 61 18 13
%%%%%%%%%%%%%%%%%
age country names
0 18 中国 大王
1 18 中国 wang2
2 18 中国 wang3
dtype: object
RangeIndex(start=0, stop=3, step=1)
Index(['age', 'country', 'names', 'price'], dtype='object')
注意点:
1、dataframe对象创建可以通过一维数组和多维数组创建
2、可以指定行,列索引,index指定的是行索引,columns指定的是列索引
3、如果使用的是字典创建:
(1)字典的键名作为列索引
(2)单个的字符串或者数字,扩充到最大个数
(3)如果是多个元素,保证元素的个数是相同的
4、series对象的本质是一个一维数组加索引
dataframe对象的本质是多个series对像共用一个行索引
10.2 df对象的讲解
print('^^^^^^^^^^^^^^^^')
print(df3['names'])
print(df3['names'].values)
print(type(df3['names']))
展示:
A 大王
B wang2
C wang3
Name: names, dtype: object
['大王' 'wang2' 'wang3']
注意点:
1、dataframe对象是由很多个series对象组成的,只不过这些series对象共享一个行索引
2、df[索引]获取了一列数据
print('查看当前df对象的详细信息')
print(df3.info())
展示:
查看当前df对象的详细信息
Index: 3 entries, A to C
Data columns (total 4 columns):
age 3 non-null int64
country 3 non-null object
names 3 non-null object
price 3 non-null float64
dtypes: float64(1), int64(1), object(2)
memory usage: 120.0+ bytes
None
df3 = pd.DataFrame(dict_new,index=list('ABC'))
df3.index.name='index_name'
df3.columns.name = 'col_name'
展示:
col_name age country names price
index_name
A 18 中国 大王 1.23
B 18 中国 wang2 1.23
C 18 中国 wang3 1.23
##11、pandas索引操作
11.1 series的索引操作
####11.1.1 series对象,index索引名不是数组的
import pandas as pd
import numpy as np
#series的索引操作
ser1 = pd.Series(range(10,15),index=list('ABCDE'))
print(ser1)
print('#######取单个数据的时候#######')
print(ser1['A'])
print(ser1[0])
print('########取连续数据#########')
print(ser1['A':'C'])
print(ser1[0:2])
print('如果取连续多个数据的时候,下标取值不包含结束位置,如果是索引切片,包含结束位置')
print('取不连续多个')
print(ser1[['A','C','E']])
print(ser1[[0,2,3]])
print('#########布尔索引(条件筛选)#########')
print(ser1[(ser1>12) & (ser1<15)])
print(ser1[(ser1<12)|(ser1>15)])
print(ser1[ser1!=13])
print(ser1[~(ser1==13)])
展示:
A 10
B 11
C 12
D 13
E 14
dtype: int64
#######取单个数据的时候#######
10
10
########取连续数据#########
A 10
B 11
C 12
dtype: int64
A 10
B 11
dtype: int64
如果取连续多个数据的时候,下标取值不包含结束位置,如果是索引切片,包含结束位置
取不连续多个
A 10
C 12
E 14
dtype: int64
A 10
C 12
D 13
dtype: int64
#########布尔索引(条件筛选)#########
D 13
E 14
dtype: int64
A 10
B 11
dtype: int64
A 10
B 11
C 12
E 14
dtype: int64
A 10
B 11
C 12
E 14
dtype: int64
注意点:
1、索引名是字符串类型的时候,取单个值既可以通过索引名,也可以通过下标,但是如果索引名也是数组的时候,默认按照索引名进行取值
2、取连续多个数据,如果使用下标,不包含结束位,使用索引包含结束位
3、取多个数据返回的是一个series对象
11.1.2 series对象,但是索引名是数字
print('**********************')
ser2 = pd.Series(range(10,15),index=range(1,6))
print(ser2)
print(ser2[1])
展示:
**********************
1 10
2 11
3 12
4 13
5 14
dtype: int64
10
注意点:
但是如果索引名也是数组的时候,默认按照索引名进行取值,不会按照下标取值
11.2 dataframe的索引操作
11.2.1 列索引取值
11.2.1.1 取出一列数据
df1 = pd.DataFrame(np.random.randint(10,50,(3,4)),index=list('ABC'),columns=list('abcd'))
print(df1)
print('######取出一列数据#######')
print(df1['a'])
print(df1['a'].values)
print('取出的数据是一个series对象')
展示:
a b c d
A 20 34 40 26
B 18 13 39 17
C 15 33 40 36
######取出一列数据#######
A 20
B 18
C 15
Name: a, dtype: int32
[20 18 15]
取出的数据是一个series对象
11.2.1.2 取出一列数据的某一行数据(取单个数据)
print('取出一列数据的某一行数据(取单个数据)')
print(df1['a']['B'])
print(df1['a'][1])
展示:
取出一列数据的某一行数据(取单个数据)
33
33
11.2.1.3 取不连续多列
print('########不连续多列######')
print(df1[['a','c']])
展示:
########不连续多列######
a c
A 21 20
B 19 13
C 41 19
#####11.2.1.4 取连续多列
注意点:默认不支持取连续多列数据,通过高级索引实现
11.2.2 行索引取值
11.2.2.1 取单行
print('11.2.2.1 取单行')
print(df1['A':'A'])
展示
11.2.2.1 取单行
a b c d
A 32 16 29 17
11.2.2.2 取连续多行
print('11.2.2.2 取连续多行')
print(df1['A':'C'])
展示:
11.2.2.2 取连续多行
a b c d
A 32 16 29 17
B 10 29 41 16
C 34 49 35 22
11.2.2.3 取不连续多行
默认不支持取不连续多行
11.3 高级索引
11.3.1 标签索引 loc
# series取值
# print(ser1['A'])
# print(ser1['A':'C'])
# print(ser1[['A','C','E']])
print(ser1.loc['B'])
print(ser1.loc['B':'D'])
print(ser1.loc[['B','D']])
展示:
a b c d
A 28 43 22 21
B 34 35 27 39
C 11 41 15 44
A 10
B 11
C 12
D 13
E 14
dtype: int64
#标签索引 loc##
11
B 11
C 12
D 13
dtype: int64
B 11
D 13
dtype: int64
print('取单行')
print(df1['A':'A'])
print(df1.loc['A'])
展示:
a b c d
A 20 11 17 25
a 20
b 11
c 17
d 25
Name: A, dtype: int32
注意点:
原始的取值方式,取出的是一个df对象
标签索引取单行数据,取出的是一个series对象
print('取单列')
print(df1['a'])
print(df1.loc[:,'a'])
展示:
取单列
A 21
B 22
C 26
Name: a, dtype: int32
A 21
B 22
C 26
Name: a, dtype: int32
print('取连续多行')
print(df1['A':'C'])
print(df1.loc['A':'C'])
展示
取连续多行
a b c d
A 25 37 47 33
B 36 20 26 17
C 46 44 19 31
a b c d
A 25 37 47 33
B 36 20 26 17
C 46 44 19 31
print('####取连续多列###')
print(df1.loc[:,'a':'c'])
展示:
####取连续多列###
a b c
A 34 44 40
B 37 24 38
C 44 21 11
print('#####取连续多行多列####')
print(df1.loc['B':'C','c':'d'])
展示:
#####取连续多行多列####
c d
B 36 12
C 42 38
print('#取不连续多行#')
print(df1.loc[['A','C']])
展示:
取不连续多行#
a b c d
A 43 19 16 16
C 33 10 41 48
print('###取不连续多列###')
print(df1.loc[:,['a','c','d']])
展示:
###取不连续多列###
a c d
A 24 21 36
B 49 33 29
C 40 41 45
print('###取不连续的多行多列##')
print(df1.loc[['A','C'],['a','d','c']])
展示
###取不连续的多行多列##
a d c
A 45 32 43
C 34 46 15
11.3.2 位置索引 iloc(根据下标取值,不包含结束位)
print(df1.iloc[0,0])
print(df1.iloc[0:2])
print(df1.iloc[:,0:3])
print(df1.iloc[[0,2],[0,3]])
展示:
a b c d
A 45 44 36 10
B 14 42 46 11
C 46 18 20 17
A 10
B 11
C 12
D 13
E 14
dtype: int64
#标签索引 loc##
45
a b c d
A 45 44 36 10
B 14 42 46 11
a b c
A 45 44 36
B 14 42 46
C 46 18 20
a d
A 45 10
C 46 17
11.3.3 混合索引 ix
print(df1.ix['A':'B',0:3])
展示:
a b c
A 29 34 20
B 17 42 34
11.3.4 根据索引增加行/列数据
df1 = pd.DataFrame(np.random.randint(10,20,(3,4)),index=list('ABC'),columns=list('accd'))
print(df1)
print('增加一列数据')
df1['e'] = df1['d']*10
print(df1)
print('增加一行数据')
df1.loc['D'] = [1,2,3,4,5]
print(df1)
print('将各列数据相加之和作为下一列')
df1['f'] = df1['a']+df1['b']+df1['c']+df1['d']+df1['e']
print(df1)
展示:
a c c d
A 16 14 17 16
B 17 18 11 10
C 13 18 19 10
增加一列数据
a c c d e
A 16 14 17 16 160
B 17 18 11 10 100
C 13 18 19 10 100
增加一行数据
a c c d e
A 16 14 17 16 160
B 17 18 11 10 100
C 13 18 19 10 100
D 1 2 3 4 5
将各列数据相加之和作为下一列
a b c d e f
A 12 16 11 15 150 204
B 10 18 16 11 110 165
C 11 13 13 15 150 202
D 1 2 3 4 5 15
11.3.5 根据索引删除数据
def drop(self, labels=None, axis=0, index=None, columns=None, level=None,
inplace=False, errors='raise'):
"""
Return new object with labels in requested axis removed.
Parameters
----------
labels : single label or list-like
Index or column labels to drop.
axis : int or axis name
Whether to drop labels from the index (0 / 'index') or
columns (1 / 'columns').
index, columns : single label or list-like
Alternative to specifying `axis` (``labels, axis=1`` is
equivalent to ``columns=labels``).
.. versionadded:: 0.21.0
level : int or level name, default None
For MultiIndex
inplace : bool, default False
If True, do operation inplace and return None.
errors : {'ignore', 'raise'}, default 'raise'
If 'ignore', suppress error and existing labels are dropped.
df1 = pd.DataFrame(np.random.randint(10,20,(3,4)),index=list('ABC'),columns=list('abcd'))
# print(df1)
# print('增加一列数据')
# df1['e'] = df1['d']*10
# print(df1)
# print('增加一行数据')
# df1.loc['D'] = [1,2,3,4,5]
# print(df1)
# print('将各列数据相加之和作为下一列')
# df1['f'] = df1['a']+df1['b']+df1['c']+df1['d']+df1['e']
# print(df1)
print('原始数据')
print(df1)
print('删除多列数据')
df2 = df1.drop(['c','d'],axis=1)
print(df1)
print(df2)
注意点:
删除指定的索引,必须配合axis使用,axis=1 表示列,axis=0表示的是行
drop()这个方法,返回删除之后的dataframe,原始数据不受影响
指定行列的时候不使用0或1,使用index和columns
# del df2
# print(df2)
del df1['d']
del df1.loc['A']
print(df1)
展示:
a b
A 11 13
B 14 17
C 14 18
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/python_new/数组/pandas索引操作.py", line 122, in
del df1.loc['A']
AttributeError: __delitem__
del 这个方法,只能删除列,不能删除行
而且实在原始数据上做的操作
11.3.6 索引对象的转换
print(df1)
index_data = df1.index
columns_data = df1.columns
index_data_list = list(index_data)
print('tolist',index_data_list)
print(np.array(index_data))
print('###################')
print(ser1)
print(ser1.index)
索引对象,支持转成列表,数组,series也能转
12、pandas的对齐操作
四种主要的运算:加add()减sub()乘mul()除div()
12.1 series
12.1.1 加法
import numpy as np
import pandas as pd
print('######series对齐运算####')
ser1 = pd.Series(data=range(10,15),index=list('abcde'))
ser2 = pd.Series(data=range(20,25),index=list('cdefg'))
print('###################ser1')
print(ser1)
print('###################ser2')
print(ser2)
print('###################add()')
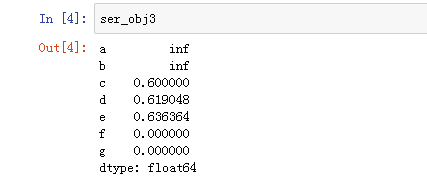
ser_obj3 = ser1.add(ser2)
print(ser_obj3)
展示:
######series对齐运算####
###################ser1
a 10
b 11
c 12
d 13
e 14
dtype: int64
###################ser2
c 20
d 21
e 22
f 23
g 24
dtype: int64
###################add()
a NaN
b NaN
c 32.0
d 34.0
e 36.0
f NaN
g NaN
dtype: float64
注意点:
1、series对象在进行相加操作的时候,它会将相同索引的对应的值进行相加操作
2、如果索引不同的话,就会使用NaN值进行填充操作
3、fill_value这个参数制定一个填充值,如果没有相同的索引,可以使用填充值进行操作
ser_obj4 = ser1.add(ser2,fill_value=0)
print(ser_obj4)
展示:
a 10.0
b 11.0
c 32.0
d 34.0
e 36.0
f 23.0
g 24.0
dtype: float64
12.1.2 除法
ser_obj3 = ser1.div(ser2,fill_value=0)
ser_obj3
12.2 dataframe
12.2.1 加法
print('dataframe对齐运算')
df1 = pd.DataFrame(np.arange(11,20).reshape(3,3),columns=list('ABC'))
df2 = pd.DataFrame(np.arange(20,40).reshape(4,5),columns=list('ABCDE'))
print(df1)
print(df2)
df3 = df1.add(df2,fill_value=0)
print(df3)
注意点:
和serie对象的相加是一样
12.3 series对象与dataframe对象做对齐操作
数据类型不同的时候做对齐操作,不支持fill_value
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hQqlENMI-1576206861909)(C:\Users\Administrator\Desktop\PAI0408\1573177955138.png)]
13、数据清洗
###13.1 判断是否存在空值
df1 = pd.DataFrame([np.random.randint(10,50,4),[1.1,2.2,3.3,]])
print(df1)
print('####判断是否存在缺失值##')
ret = df1.isnull()
print(ret)
ret2 = df1.notnull()
print(ret2)
展示:
####判断是否存在缺失值##
0 1 2 3
0 False False False False
1 False False False True
0 1 2 3
0 True True True True
1 True True True False
13.2 删除存在空值的行/列
ret3 = df1.dropna(axis=1,inplace=True)
print(ret3)
print(df1)
df1.dropna(axis='index')
df1.dropna(axis='columns')
1、dropna这个方法,默认删除一行
2、axis=1 列
3、inplace的参数默认值是false,代表不在原始数据上做操作,返回删除空值之后的数据,如果设置为True则,在原始数据做操作
4、建议直接记index和columns
13.3 填充缺失值
# ret3 = df1.fillna(0)
# print(ret3)
ret3 = df1.fillna({0:0,3:100})
print(ret3)
df1.fillna({
'A':100,
'B':200,
'C':300,
'D':400
})
注意点:
1、如果在fillna这个函数中填值,代表所有的nan数据直接换成指定的值
2、如果参数是字典,那么表示对于不同的列有不同的值,字典的键名是列名,值为填充的值
3、也可以通过设置inplace这个参数,修改原始数据
13.4 处理重复数据
duplicated()
对于指定列的每一个元素进行判断,如果已经出现该元素,标记为True,返回的是一个series对象
ret2 = df1.drop_duplicates('data1')
print(ret2)
展示:
data1 data2
0 a 1
1 a 2
2 b 3
3 b 4
4 c 1
5 c 2
6 d 3
7 d 5
data1 data2
0 a 1
2 b 3
4 c 1
6 d 3
注意点:
1、指定inplace可以指定是否在原始数据上做操作
13.5 替换
# ret1 = df1.replace('b',1,)
将数据中的'b'全部替换成1
# ret1 = df1.replace(['b','d'],1,)
将全部的b和d,替换成1
ret1 = df1.replace({'b':1,'d':2})
将b替换成1,'d'替换成2
ret2 = ret1.replace({'data1':1},'m')
将data1这一列的1,替换成'm'
print(ret1)
print(ret2)
展示:
data1 data2
0 a 1
1 a 2
2 b 3
3 b 4
4 c 1
5 c 2
6 d 3
7 d 5
data1 data2
0 a 1
1 a 2
2 1 3
3 1 4
4 c 1
5 c 2
6 2 3
7 2 5
data1 data2
0 a 1
1 a 2
2 m 3
3 m 4
4 c 1
5 c 2
6 2 3
7 2 5
正则:

14、pandas中的函数应用
14.1 求绝对值
import numpy as np
import pandas as pd
ser1 = pd.Series(np.random.randint(-10,10,10))
df1 = pd.DataFrame(np.random.randint(-10,10,(4,5)))
print(ser1)
print(np.abs(ser1))
print(df1)
展示:
0 -8
1 -6
2 -9
3 0
4 -9
5 -2
6 2
7 5
8 0
9 -5
dtype: int32
0 8
1 6
2 9
3 0
4 9
5 2
6 2
7 5
8 0
9 5
dtype: int32
0 1 2 3 4
0 4 1 8 1 7
1 -5 5 -8 -2 6
2 0 -9 -5 -7 -1
3 7 -10 3 9 -3
14.2 求和
print(np.sum(ser1))
print(np.sum(df1,axis=1))
展示:
-10
0 -21
1 13
2 6
3 0
dtype: int64
注意点:
1、axis=1 行,axis=0 列
14.3 apply()将自定义函数作用到dataframe的行或者列或者series的列上
def func(x):
# print(x)
num = np.max(x)-np.min(x)
# print(num)
return num
print(df1)
print('#########################')
print(df1.apply(func,axis=1))
print(df1.apply(lambda x:np.max(x)-np.min(x),axis=1))
print(df1.apply(lambda x:x**2,axis=1))
print(df1.apply(lambda x:x*x,axis=1))
注意点:
1、apply这个函数是将自定义的函数应用于每一行或者列上的
2、如果自定义的函数是一个计算型的函数,将应用在每一个元素上面
3、如果自定义的函数是一个统计型的函数,将应用于每一列或者每一行
4、axis=0 代表的是列,axis=1代表的是行
14.4applymap()将自定义的函数应用于每一个元素
def func1(x):
# print(x)
return abs(x)
print(df1.applymap(func1))
print(df1.applymap(lambda x:abs(x)))
15、排序
15.1 按照索引排序
print('######按照索引排序############')
print(ser1.sort_index()) #默认按照升序进行排序
print(ser1.sort_index(ascending=False)) #按照降序
print(df1)
注意点:
1、默认按照升序排序
2、默认返回了一个copy版本,没有在原始数据做操作
15.2 按照值进行排序
print('#######按照值进行排序##########')
print(ser1.sort_values()) #升序
print(ser1.sort_values(ascending=False)) #降序
print(df1.sort_values(by='a'))
注意点:
1、series对象的结构比较简单
2、dataframe对象比较复杂,需要指定按照那一列来进行排序
16、数据重构
16.1 常见的索引类型
MultiIndex
16.2 层级索引
MultiIndex(levels=[['a', 'b', 'c', 'd', 'e'], [1, 2, 3, 4, 5, 6, 7, 8, 9, 11]],
labels=[[0, 0, 1, 1, 2, 2, 3, 3, 4, 4], [0, 3, 4, 5, 1, 2, 6, 7, 8, 9]])
levels用来展示两个层级中,有那些索引
labels说明每一个位置是那些标签
16.3 按照层级取值
print('########按照外层索引取值######')
print(ser1['a'])
print(type(ser1['a']))
print('####按照内层索引取值#####')
print(ser1[:,1])
print('#######指定外层与内层###')
print(ser1['c',2])
16.4 交换分层
print(ser1.swaplevel())
展示:
MultiIndex(levels=[['a', 'b', 'c', 'd', 'e'], [1, 2]],
labels=[[0, 0, 1, 1, 2, 2, 3, 3, 4, 4], [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]])
a 1 9
2 1
b 1 -9
2 -9
c 1 2
2 -5
d 1 -1
2 1
e 1 -8
2 4
dtype: int32
1 a 9
2 a 1
1 b -9
2 b -9
1 c 2
2 c -5
1 d -1
2 d 1
1 e -8
2 e 4
dtype: int32
16.5 数据重构
# print(ser1.swaplevel())
print(ser1.unstack())
将有层级索引的series对象转化成dataframe对象,外层索引作为行索引,内层索引作为列索引
print(df1.stack())
将dataframe对象转成series对象
print(df1)
print('#################')
# print(df1.T)
行列转置
print(df1.to_dict())
print(df1.to_csv())
17、pandas的统计与汇总
17.1 求和
print(df1.sum())
print(df1.sum(axis=1))
默认按照列求和,axis=0 是列,axis=1行
17.2 求均值
print(df1.mean())
print(df1.mean(skipna=False))
print(df2.mean())
print(df2.mean(skipna=True))
print(df2.mean(skipna=False))
17.3 详细描述
print(df1.describe())
17.4 中位数
print(df1.median())
17.5 方差
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数
print(df1.var())
17.6 标准差
print(df1.std())
18、数据连接
定义:根据单个或者多个键将不同的dataframe对象的行连接起来
18.1 merge
pd.merge()
def merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None):
print('#########连接###########')
print(pd.merge(df1,df2,on='key'))
print(pd.merge(df1,df2))
print(pd.merge(df1,df2,on='key'))
print(pd.merge(df1,df2,on='data1'))
注意点:
1、两张表进行连接的过程中,如果没有指定,默认使用的是dataframe对象的同名的列作为外键进行关联
2、如果同名的列很多,就可以通过on来指定外键
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
{'key1':list('abcdefgh'),'data1':np.random.randint(-5,10,8)}
)
df2 = pd.DataFrame(
{'key2':list('abcde'),'data2':np.random.randint(-5,10,5)}
)
print(df1)
print(df2)
print('#########连接###########')
# print(pd.merge(df1,df2,on='key'))
# print(pd.merge(df1,df2,on='data1'))
print(pd.merge(df1,df2,left_on='key1',right_on='key2'))
展示:
data1 key1
0 -1 a
1 -1 b
2 0 c
3 3 d
4 9 e
5 0 f
6 5 g
7 -1 h
data2 key2
0 8 a
1 8 b
2 4 c
3 -5 d
4 6 e
#########连接###########
data1 key1 data2 key2
0 -1 a 8 a
1 -1 b 8 b
2 0 c 4 c
3 3 d -5 d
4 9 e 6 e
注意点:
1、当两张表没有同名的列的时候,可以通过left_on,right_on来指定连接的条件(列)
18.2可以通过how这个参数指定连接方式, 默认的多表关联方式是内连接(多表的交集)
print(pd.merge(df1,df2,left_on='key1',right_on='key2'))
print('#######outer####')
print(pd.merge(df1,df2,how='outer',left_on='key1',right_on='key2'))
print('######left####')
print(pd.merge(df1,df2,how='left',left_on='key1',right_on='key2'))
print('##right###')
print(pd.merge(df1,df2,how='right',left_on='key1',right_on='key2'))
注意点:
1、how=inner,默认的,内连接,多表的交集
2、how=outer ,这是外连接,多表的并集
3、how=left,指定为左连接,展示左表的完整数据,不管右表有没有匹配
4、how=right,指定为右连接,不管左表有没有匹配,完整的展示右表的数据
###18.3dataframe对象的列全部都是同名的时候
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
{'key1':list('abcdefgh'),'data1':np.random.randint(-5,10,8)}
)
df2 = pd.DataFrame(
{'key2':list('abcde'),'data1':np.random.randint(-5,10,5)}
)
print(df1)
print(df2)
print('#########连接###########')
# print(pd.merge(df1,df2,on='key'))
# print(pd.merge(df1,df2,on='data1'))
print('#####inner####')
print(pd.merge(df1,df2,left_on='key1',right_on='key2'))
展示:
data1 key1
0 4 a
1 5 b
2 1 c
3 7 d
4 0 e
5 0 f
6 5 g
7 2 h
data1 key2
0 -1 a
1 3 b
2 4 c
3 7 d
4 -3 e
#########连接###########
#####inner####
data1_x key1 data1_y key2
0 4 a -1 a
1 5 b 3 b
2 1 c 4 c
3 7 d 7 d
4 0 e -3 e
代码:
print('#####inner####')
print(pd.merge(df1,df2,left_on='key1',right_on='key2',suffixes=['_左表','_右表']))
展示:
#####inner####
data1_左表 key1 data1_右表 key2
0 9 a 6 a
1 5 b -4 b
2 5 c 3 c
3 7 d 7 d
4 -5 e 8 e
print('通过行索引来指定')
print(pd.merge(df1,df2,left_on='data1',right_index=True ))
展示:
data1 key1
0 -3 a
1 0 b
2 1 c
3 -2 d
4 -1 e
5 5 f
6 3 g
7 4 h
data2 key1
0 5 a
1 3 b
2 1 c
3 -4 d
4 -3 e
通过行索引来指定
data1 key1_x data2 key1_y
1 0 b 5 a
2 1 c 3 b
6 3 g -4 d
7 4 h -3 e
print('通过行索引来指定')
print(pd.merge(df1,df2,left_index=True,right_index=True ))
展示:
data1 key1
0 -1 a
1 8 b
2 -5 c
3 0 d
4 -3 e
5 -5 f
6 9 g
7 7 h
data2 key1
0 -1 a
1 6 b
2 8 c
3 6 d
4 7 e
通过行索引来指定
data1 key1_x data2 key1_y
0 -1 a -1 a
1 8 b 6 b
2 -5 c 8 c
3 0 d 6 d
4 -3 e 7 e
print('通过行索引来指定')
# print(pd.merge(df1,df2,left_on='data1',right_index=True ))
print(pd.merge(df1,df2,how='left',left_index=True,right_index=True ))
print('################')
print(pd.merge(df1,df2,how='right',left_index=True,right_index=True ))
展示:
通过行索引来指定
data1 key1_x data2 key1_y
0 9 a 2.0 a
1 9 b -2.0 b
2 -1 c 8.0 c
3 0 d -1.0 d
4 4 e 0.0 e
5 -2 f NaN NaN
6 1 g NaN NaN
7 2 h NaN NaN
################
data1 key1_x data2 key1_y
0 9 a 2 a
1 9 b -2 b
2 -1 c 8 c
3 0 d -1 d
4 4 e 0 e
注意点:
1、如果两个对象出现同名的列的时候,默认是将_x和_y加在左右表的同名列名上
2、suffixes=['_左表','_右表'],用来指定同名列的后缀,参数列表的顺序就是左右表的顺序
3、left_on用来指定左表的列为外键,right是指将右表的行索引进行外键
4、left_index,right_index,默认的情况下,将两张表按照行索引相同的情况,合成一条数据
5、按照行进行连接,也可以指定连接方式
19、数据的合并
19.1 numpy的合并 np.concatenate()
def concatenate(a_tuple, axis=0, out=None): # real signature unknown; restored from __doc__
"""
concatenate((a1, a2, ...), axis=0, out=None)
Join a sequence of arrays along an existing axis.
Parameters
----------
a1, a2, ... : sequence of array_like
The arrays must have the same shape, except in the dimension
corresponding to `axis` (the first, by default).
axis : int, optional
The axis along which the arrays will be joined. Default is 0.
out : ndarray, optional
If provided, the destination to place the result. The shape must be
correct, matching that of what concatenate would have returned if no
out argument were specified.
arr1 = np.random.randint(10,20,(3,4))
arr2 = np.random.randint(10,20,(3,4))
print(np.concatenate((arr1,arr2),axis=1))
print('####################')
print(np.concatenate((arr1,arr2)))
展示:
[[19 17 18 13 11 18 19 15]
[18 17 11 14 12 11 12 15]
[12 13 17 19 16 17 11 17]]
####################
[[19 17 18 13]
[18 17 11 14]
[12 13 17 19]
[11 18 19 15]
[12 11 12 15]
[16 17 11 17]]
注意点:
1、参与合并的数组,维度的大小是一致的
2、axis默认为按照列进行合并,axis=1,按照行进行排序
19.2 pandas的合并 pd.concat()
19.2.1 concat()
def concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True):
Parameters
----------
objs : a sequence or mapping of Series, DataFrame, or Panel objects
If a dict is passed, the sorted keys will be used as the `keys`
argument, unless it is passed, in which case the values will be
selected (see below). Any None objects will be dropped silently unless
they are all None in which case a ValueError will be raised
axis : {0/'index', 1/'columns'}, default 0
The axis to concatenate along
join : {'inner', 'outer'}, default 'outer'
How to handle indexes on other axis(es)
join_axes : list of Index objects
Specific indexes to use for the other n - 1 axes instead of performing
inner/outer set logic
ignore_index : boolean, default False
If True, do not use the index values along the concatenation axis. The
resulting axis will be labeled 0, ..., n - 1. This is useful if you are
concatenating objects where the concatenation axis does not have
meaningful indexing information. Note the index values on the other
axes are still respected in the join.
keys : sequence, default None
If multiple levels passed, should contain tuples. Construct
hierarchical index using the passed keys as the outermost level
levels : list of sequences, default None
Specific levels (unique values) to use for constructing a
MultiIndex. Otherwise they will be inferred from the keys
names : list, default None
Names for the levels in the resulting hierarchical index
verify_integrity : boolean, default False
Check whether the new concatenated axis contains duplicates. This can
be very expensive relative to the actual data concatenation
copy : boolean, default True
If False, do not copy data unnecessarily
19.2.2 series合并
ser1 = pd.Series(np.random.randint(10,20,3))
ser2 = pd.Series(np.random.randint(10,20,5))
ser3 = pd.Series(np.random.randint(10,20,7))
print(ser1)
print(ser2)
print(ser3)
print('#######series合并########')
print(pd.concat([ser1,ser2,ser3]))
展示:
0 18
1 19
2 12
dtype: int32
0 11
1 14
2 13
3 13
4 17
dtype: int32
0 18
1 13
2 19
3 12
4 13
5 12
6 11
dtype: int32
#######series合并########
0 18
1 19
2 12
0 11
1 14
2 13
3 13
4 17
0 18
1 13
2 19
3 12
4 13
5 12
6 11
dtype: int32
print('#######series合并########')
print(pd.concat([ser1,ser2,ser3],axis=1))
展示:
0 1 2
0 11.0 10.0 18
1 14.0 13.0 18
2 15.0 10.0 15
3 NaN 16.0 19
4 NaN 10.0 16
5 NaN NaN 18
6 NaN NaN 18
print('#######series合并########')
print(pd.concat([ser1,ser2,ser3],axis=1,join='inner'))
展示:
#######series合并########
0 1 2
0 17 13 13
1 18 15 16
2 11 12 13
注意点:
1、多个series对象进行合并的时候,需要用【】括起来
2、默认按照列来合并,axis-1,按照行索引来排序,如果索引对应的值没有,用nan值填充
3、这个默认是outer,说明是并集
19.2.3 dataframe对象的合并
df1 = pd.DataFrame(
{'key1':list('abcdefgh'),'data1':np.random.randint(-5,10,8)}
)
df2 = pd.DataFrame(
{'key2':list('abcde'),'data2':np.random.randint(-5,10,5)}
)
print(pd.concat((df1,df2)))
展示:
data1 data2 key1 key2
0 8.0 NaN a NaN
1 -5.0 NaN b NaN
2 7.0 NaN c NaN
3 -2.0 NaN d NaN
4 -2.0 NaN e NaN
5 1.0 NaN f NaN
6 6.0 NaN g NaN
7 -3.0 NaN h NaN
0 NaN 5.0 NaN a
1 NaN 2.0 NaN b
2 NaN 8.0 NaN c
3 NaN 3.0 NaN d
4 NaN 7.0 NaN
print(pd.concat((df1,df2),axis=1))
展示:
data1 key1 data2 key2
0 -5 a 5.0 a
1 9 b -1.0 b
2 6 c 2.0 c
3 -4 d 4.0 d
4 0 e -2.0 e
5 -5 f NaN NaN
6 4 g NaN NaN
7 2 h NaN NaN
print(pd.concat((df1,df2),axis=1,join='inner'))
展示:
data1 key1 data2 key2
0 7 a 0 a
1 0 b -2 b
2 0 c 1 c
3 6 d 4 d
4 3 e 5 e
20、分组
###20.1 groupby
def groupby(self, by=None, axis=0, level=None, as_index=True, sort=True,
group_keys=True, squeeze=False, **kwargs):
"""
Group series using mapper (dict or key function, apply given function
to group, return result as series) or by a series of columns.
Parameters
----------
by : mapping, function, str, or iterable
Used to determine the groups for the groupby.
If ``by`` is a function, it's called on each value of the object's
index. If a dict or Series is passed, the Series or dict VALUES
will be used to determine the groups (the Series' values are first
aligned; see ``.align()`` method). If an ndarray is passed, the
values are used as-is determine the groups. A str or list of strs
may be passed to group by the columns in ``self``
axis : int, default 0
level : int, level name, or sequence of such, default None
If the axis is a MultiIndex (hierarchical), group by a particular
level or levels
as_index : boolean, default True
For aggregated output, return object with group labels as the
index. Only relevant for DataFrame input. as_index=False is
effectively "SQL-style" grouped output
sort : boolean, default True
Sort group keys. Get better performance by turning this off.
Note this does not influence the order of observations within each
group. groupby preserves the order of rows within each group.
group_keys : boolean, default True
When calling apply, add group keys to index to identify pieces
squeeze : boolean, default False
reduce the dimensionality of the return type if possible,
otherwise return a consistent type
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
{'key1':list('abcdefgh'),'data1':np.random.randint(-5,10,8),'key2':list('11223344'),'data2':np.random.randint(-5,10,8)}
)
print(df1)
print(group_obj)
print(group_obj.sum())
求和
print(group_obj.mean())
求均值
print(group_obj.size())
求每一个分组的元素个数
展示:
data1 data2 key1 key2
0 4 -5 a 1
1 -1 3 b 1
2 0 -4 c 2
3 -4 -1 d 2
4 4 -1 e 3
5 -3 -4 f 3
6 -2 0 g 4
7 -4 -5 h 4
data1 data2
key2
1 3 -2
2 -4 -5
3 1 -5
4 -6 -5
注意点:
1、分组完成之后,返回的是一个分组对象
2、分组之后,可以使用函数进行下一步的处理
3、进行计算的过程中,非数字的数据不用参与计算
20.1 分组之后的数据展示
for name,data in group_obj:
print(name)
print('***********')
print(data)
print(type(data))
print('###########################')
展示:
1
***********
data1 data2 key1 key2
0 2 5 a 1
1 -4 8 b 1
###########################
2
***********
data1 data2 key1 key2
2 4 -3 c 2
3 5 5 d 2
###########################
3
***********
data1 data2 key1 key2
4 -4 4 e 3
5 0 9 f 3
###########################
4
***********
data1 data2 key1 key2
6 6 0 g 4
7 8 -4 h 4
###########################
注意点:
1、当迭代分组对象的时候,每一个元素的形式(分组名,属于该分组的数据)
2、属于该分组的数据,也是dataframe对象
20.2 分组对象转Python数据类型
print(list(group_obj))
print(dict(list(group_obj)))
展示:
[('1', data1 data2 key1 key2
0 0 -3 a 1
1 -1 -3 b 1), ('2', data1 data2 key1 key2
2 8 -4 c 2
3 1 2 d 2), ('3', data1 data2 key1 key2
4 0 -2 e 3
5 6 -4 f 3), ('4', data1 data2 key1 key2
6 -4 5 g 4
7 -1 3 h 4)]
{'1': data1 data2 key1 key2
0 0 -3 a 1
1 -1 -3 b 1, '2': data1 data2 key1 key2
2 8 -4 c 2
3 1 2 d 2, '3': data1 data2 key1 key2
4 0 -2 e 3
5 6 -4 f 3, '4': data1 data2 key1 key2
6 -4 5 g 4
7 -1 3 h 4}
20.3 聚合
数组产生标量的过程
常常用于分组之后的数据计算
20.3.1 内置的聚合函数
sum() 求和
mean()均值
max 最大值
min 最小值
count()
size()
print(group_obj.describe())
data1 data2 \
count mean std min 25% 50% 75% max count mean std
key2
1 2.0 5.5 4.949747 2.0 3.75 5.5 7.25 9.0 2.0 7.0 0.000000
2 2.0 4.5 0.707107 4.0 4.25 4.5 4.75 5.0 2.0 3.5 2.121320
3 2.0 -0.5 6.363961 -5.0 -2.75 -0.5 1.75 4.0 2.0 7.0 1.414214
4 2.0 4.0 5.656854 0.0 2.00 4.0 6.00 8.0 2.0 2.5 6.363961
min 25% 50% 75% max
key2
1 7.0 7.00 7.0 7.00 7.0
2 2.0 2.75 3.5 4.25 5.0
3 6.0 6.50 7.0 7.50 8.0
4 -2.0 0.25 2.5 4.75 7.0
20.3.2 agg() 自定义函数做聚合运算
print(group_obj.agg('max'))
print(group_obj.agg('min'))
#使用多个内置的聚合函数,需要使用列表的形式,将字符串全部写入
print(group_obj.agg(['max','min','mean']))
展示:
data1 data2
max min mean max min mean
key2
1 9 -1 4.0 7 7 7.0
2 5 -4 0.5 5 2 3.5
3 9 -1 4.0 4 1 2.5
4 -1 -4 -2.5 9 0 4.5
#使用内置的聚合函数起中文名
print(group_obj.agg([('最大值','max'),('最小值','min'),('均值','mean')]))
展示:
data1 data2
最大值 最小值 均值 最大值 最小值 均值
key2
1 5 1 3.0 -1 -3 -2.0
2 9 3 6.0 9 -5 2.0
3 3 2 2.5 5 1 3.0
4 6 -2 2.0 4 3 3.5
注意点:
1、agg()填充的是函数,如果需要使用内置的聚合函数,用字符串的形式填写
2、如果使用内置的函数起在别名的时候,注意(别名,字符串形式的内置函数名)
def func(x):
# print(x)
ret = x.max()-x.min()
return ret
print('***********************')
print(group_obj.agg([('差值',func)]))
#针对不同的列使用不同的函数
自定义函数
print(group_obj.agg(
{
'data1':['max'],
'data2':[('最小值','min')]
}
))
不同的列用不同的聚合函数
data1 data2
max 最小值
key2
1 3 -2
2 9 -5
3 1 5
4 8 0
21、分组聚合后数据的处理
21.1 先分组,再计算,添加前缀,merge关联
dict_new = {
'data1':np.random.randint(5,15,8),
'data2':np.random.randint(5,15,8),
'key1':list('aabbccdd'),
'key2':['one','two','three','one','two','one','two','three'],
# 'data3':4
}
df1 = pd.DataFrame(dict_new,index=list('ADCBEFGH'))
print(df1)
#按照key1进行分组
group_obj = df1.groupby('key1')
# for name,data in group_obj:
# print(name)
# print('###############')
# print(data)
#分组之后,进行求和操作
sum_data_group = group_obj.sum()
print(sum_data_group)
sum_data_group = sum_data_group.add_prefix('group_key1_')
print(sum_data_group)
#先用merge进行关联
merge_df = pd.merge(df1,sum_data_group,left_on='key1',right_index=True)
print('##########合并之后的数据####')
print(merge_df)
展示:
C:\ProgramData\Anaconda3\python.exe C:/Users/Administrator/Desktop/python_new/数组/分组聚合之后数据的处理.py
data1 data2 key1 key2
A 11 13 a one
D 12 12 a two
C 8 9 b three
B 8 6 b one
E 13 6 c two
F 13 14 c one
G 5 12 d two
H 7 9 d three
data1 data2
key1
a 23 25
b 16 15
c 26 20
d 12 21
group_key1_data1 group_key1_data2
key1
a 23 25
b 16 15
c 26 20
d 12 21
##########合并之后的数据####
data1 data2 key1 key2 group_key1_data1 group_key1_data2
A 11 13 a one 23 25
D 12 12 a two 23 25
C 8 9 b three 16 15
B 8 6 b one 16 15
E 13 6 c two 26 20
F 13 14 c one 26 20
G 5 12 d two 12 21
H 7 9 d three 12 21
注意点:
1、在当前案例中,指定的连接条件:左表的列名,右表的行索引名
21.2 transform
group_obj = df1.loc[:,['data1','data2']].groupby(df1['key1'])
# print(df1[['data1','data2']])
# for name,data in group_obj:
# print(name)
# print('######')
# print(data)
print(group_obj.sum())
print('$$$$$$$$$$$$$$$$$$$$$')
data = group_obj.transform('sum').add_prefix('trans_group_')
print(data)
ret = pd.concat([df1,data],axis=1)
print(ret)
展示:
data1 data2 key1 key2
A 6 9 a one
D 12 10 a two
C 6 5 b three
B 12 10 b one
E 7 6 c two
F 11 8 c one
G 9 13 d two
H 13 14 d three
data1 data2
key1
a 18 19
b 18 15
c 18 14
d 22 27
$$$$$$$$$$$$$$$$$$$$$
trans_group_data1 trans_group_data2
A 18 19
D 18 19
C 18 15
B 18 15
E 18 14
F 18 14
G 22 27
H 22 27
data1 data2 key1 key2 trans_group_data1 trans_group_data2
A 6 9 a one 18 19
D 12 10 a two 18 19
C 6 5 b three 18 15
B 12 10 b one 18 15
E 7 6 c two 18 14
F 11 8 c one 18 14
G 9 13 d two 22 27
H 13 14 d three 22 27
注意点:
1、transform 来计算的时候,会维持原来的数据结构
2、df1.loc[:,['data1','data2']].groupby(df1['key1']),选取数据其中的数据,按照原来数据中的列来进行分组
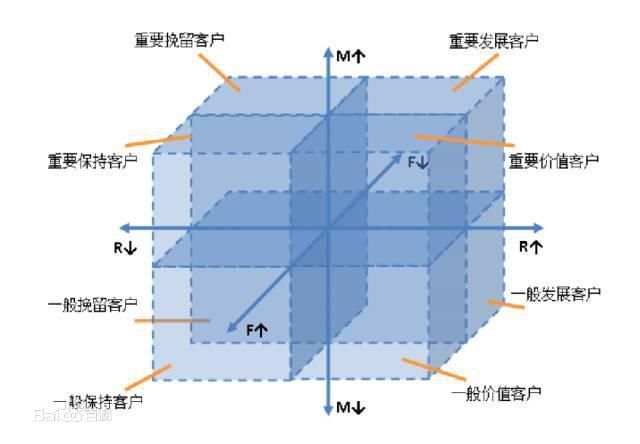
22 、RFM模型
###22.1 定义:
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的[客户关系管理](https://baike.baidu.com/item/%E5%AE%A2%E6%88%B7%E5%85%B3%E7%B3%BB%E7%AE%A1%E7%90%86)(CRM)的分析模式中,RFM模型是被广泛提到的。该机械模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有3个神奇的要素,这3个要素构成了数据分析最好的指标:
最近一次消费 (Recency)
消费频率 (Frequency)
消费金额 (Monetary)

22.2 案例
import pandas as pd
import numpy as np
import time
data = pd.read_csv('RFM_TRAD_FLOW.csv',encoding='gbk')
# print(data)
# print(data.head())
data['time']=data['time'].map(lambda x:time.mktime(time.strptime(x,'%d%b%y:%H:%M:%S')))
# print(data)、
group_obj = data.groupby(['cumid','type'])
R = group_obj[['time']].max()
#转透视表
r_trans = pd.pivot_table(R,index='cumid',columns='type',values='time')
# print(r_trans)
r_trans[['Special_offer','returned_goods']] = r_trans[['Special_offer','returned_goods']].apply(lambda x:x.replace(np.nan,min(x)),axis=0)
# print(r_trans)
r_trans['r_max'] = r_trans[['Normal', 'Presented','Special_offer']].apply(lambda x:max(x),axis=1)
# print(r_trans)
# F
F = group_obj[['transID']].count()
print(F)
f_trans = pd.pivot_table(F,index='cumid',columns='type',values='transID')
# print(f_trans)
#
f_trans[['Special_offer','returned_goods']] = f_trans[['Special_offer','returned_goods']].fillna(0)
# print(f_trans)
f_trans['returned_goods'] = f_trans['returned_goods'].map(lambda x:-x)
# print(f_trans)
f_trans['f_total'] =f_trans.apply(lambda x:sum(x),axis=1)
print(f_trans)
# M
M = group_obj[['amount']].sum()
m_trans = pd.pivot_table(M,index='cumid',columns='type',values='amount')
# print(f_trans)
#
m_trans[['Special_offer','returned_goods']] = f_trans[['Special_offer','returned_goods']].fillna(0)
# print(f_trans)
# print(f_trans)
m_trans['m_total'] =m_trans.apply(lambda x:sum(x),axis=1)
print(m_trans)
### 合并
RFM = pd.concat([r_trans['r_max'],f_trans['f_total'],m_trans['m_total']],axis=1)
print('##################')
print(RFM)
RFM['r_score' ]= pd.cut(RFM.r_max,3,labels=[0,1,2])
RFM['f_score' ]= pd.cut(RFM.f_total,3,labels=[0,1,2])
RFM['m_score'] = pd.cut(RFM.m_total,3,labels=[0,1,2])
print(RFM)
def rfm_label(x,y,z):
if x==2 and y==2 and z==2:
return '重要价值客户'
elif x==2 and (y in [0,1]) and z ==2:
return '重要发展客户'
elif (x in [0,1]) and y==2 and z==2:
return '重要保持客户'
elif (x in [0,1] ) and (y in [0,1]) and z ==2:
return '重要挽留客户'
elif x==2 and y==2 and (z in [0,1]):
return '一般价值客户'
elif x ==2 and (y in [0,1] and (z in [0,1])):
return '一般发展客户'
elif (x in [0,1]) and y==2 and (z in [0,1]):
return '一般保持客户'
elif (x in [0,1]) and (y in [0,1]) and (z in (0,1)):
return '一般挽留客户'
RFM['标签']=RFM[[ 'r_score', 'f_score', 'm_score']].apply(lambda x:rfm_label(x[0],x[1],x[2]),axis=1)
print(RFM)
#选择满足条件的行
# pd.read_sql_query()
23 、pandas中sql语句
23.1 基于第三方
sqlite3
sqlalchemy
23.2 sqlite3使用案例
import sqlite3
import pandas as pd
sale = pd.read_csv('sale.csv',encoding='gbk')
print(sale)
#使用特定的名称在内存中创建一个数据库
con = sqlite3.connect(':memory:')
print(con)
#将dataframe对象注册成可sql查询的表
sale.to_sql('sale',con)
#查询出单独的一列
year_data = pd.read_sql_query('select year from sale',con)
year_data_1 = pd.read_sql_query('select DISTINCT year from sale',con)
print(year_data_1)
展示:
year market sale profit
0 2010 东 33912 2641
1 2010 南 32246 2699
2 2010 西 34792 2574
3 2010 北 31884 2673
4 2011 东 31651 2437
5 2011 南 30572 2853
6 2011 西 34175 2877
7 2011 北 30555 2749
8 2012 东 31619 2106
9 2012 南 32443 3124
10 2012 西 32103 2593
11 2012 北 31744 2962
year
0 2010
1 2011
2 2012
23.3 sqlalchemy使用案例
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:mysql@localhost/new_db?charset=utf8')
sale = pd.read_csv('sale.csv',encoding='gbk')
#将dataframe对象填写进入数据库
sale.to_sql('sale',engine)
24、绘图
%matplotlib inline
在jupyter notebook里面,注意
plt不支持中文,所以要修改字体
plt.rcParams['font.sans-serif'] = ['SimHei']
#修改字体的大小
plt.rcParams['font.size'] = 24
x\y轴的标签,可以设置字体的大小
plt.xlabel('数据',fontsize=18)
plt.ylabel('值',fontsize=18)
# 去除-号,当字体是中文的时候,负号显示不出来
plt.rcParams['axes.unicode_minus'] = False
#增加图例
plt.legend()
#显示网格
plt.grid()
24.1创建画布
def figure(num=None, # autoincrement if None, else integer from 1-N
figsize=None, # defaults to rc figure.figsize
dpi=None, # defaults to rc figure.dpi
facecolor=None, # defaults to rc figure.facecolor
edgecolor=None, # defaults to rc figure.edgecolor
frameon=True,
FigureClass=Figure,
clear=False,
**kwargs
):
注意点:
1、dpi分辨率
2、figsize 指定画布的大小
24.2 线型图
import matplotlib.pyplot as plt
import numpy as np
# %matplotlib inline
fig = plt.figure()
print(fig)
arr1 = np.arange(10,50)
print(arr1)
plt.plot(arr1)
plt.savefig('a.png')
plt.show()
plt.plot(arr1,color='green',marker='*',markerfacecolor='red',markersize=10,linestyle='None')
plt.show()
注意点:
1、plt.show()显示最后一次画布绘制的图形,显示完成之后,会清空内存中的数据
24.3 add_subplot分割区域(绘制子图)
####24.3.1 第一种绘制子图的方式
def add_subplot(self, *args, **kwargs):
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
arr1 = np.random.randint(10,20,20)
arr2 = np.random.randint(10,20,20)
arr3 = np.random.randint(10,20,20)
arr4 = np.random.randint(10,20,20)
ax1.plot(arr1,color='r')
ax2.plot(arr2,color='g')
ax3.plot(arr3,color='purple')
ax4.plot(arr4,color='y')
24.3.2 第二种子图的绘制方式
fig.add_subplot(2,3,1)
plt.plot(arr1)
# plt.show()
fig.add_subplot(232)
plt.plot(arr2)
fig.add_subplot(235)
plt.plot(arr2)
plt.show()
24.4 直方图
def hist(x, bins=None, range=None, density=None, weights=None, cumulative=False,
bottom=None, histtype='bar', align='mid', orientation='vertical',
rwidth=None, log=False, color=None, label=None, stacked=False,
normed=None, hold=None, data=None, **kwargs):
注意点:
1、bins是直方图特有的参数,表示的是直方的个数
2、alpha是指透明度
plt.hist(np.random.randint(10,100,40),bins=40,color='r',alpha=0.1)
plt.show()
24.5 散点图
def scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None,
vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None,
hold=None, data=None, **kwargs):
ax = gca()
x = np.random.randint(10,200,50)
y = x + 50 * np.random.rand(50)
print(x)
print(y)
plt.scatter(x,y,color='g')
plt.show()
###24.6 柱形图
x = np.arange(5)
# print(np.array(range(5)))
print(x)
y1 = np.random.randint(10,100,5)
y2 = np.random.randint(10,100,5)
plt.bar(x,y1,0.25,color='red')
plt.bar(x+0.25,y2,0.25,color='green')
plt.show()
注意点:
1、第一个参数是X轴的刻度
2、第二个参数是Y轴的刻度
3、第三个参数是柱形图的宽度
24.7 混淆矩阵(表示二维数据的分布情况)
监督学习:混淆矩阵
非监督学习:匹配矩阵
def imshow(X, cmap=None, norm=None, aspect=None, interpolation=None, alpha=None,
vmin=None, vmax=None, origin=None, extent=None, shape=None,
filternorm=1, filterrad=4.0, imlim=None, resample=None, url=None,
hold=None, data=None, **kwargs):
ax = gca()
arr1 = np.random.randint(10,50,(10,10))
print(arr1)
plt.imshow(arr1,cmap=plt.cm.Blues)
plt.colorbar()
plt.show()
注意点:
1、cmap指定颜色风格
###24.8 饼图(展示百分比的情况)
def pie(x, explode=None, labels=None, colors=None, autopct=None,
pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=None,
radius=None, counterclock=True, wedgeprops=None, textprops=None,
center=(0, 0), frame=False, rotatelabels=False, hold=None, data=None):
ax = gca()
arr10 = np.random.randint(10,20,6)
plt.pie(arr10,shadow=True,autopct='%2.2f%%',explode=[1,0,0,0,0,0],labels=['一月','2','3','4','5','6'])
plt.show()
注意点:
1、labels的长度要和数据一致
25、数理统计技术
右偏时一般算术平均数>中位数>众数,左偏时相反,即众数>中位数>平均数。正态分布三者相等。
25.1 客户的标签
分类为:基础标签,统计标签,模型标签
基础的客户标签:性别、年龄、职业,可以从原始数据中直接获取的
统计标签:原始数据的汇总得到的,比如客户的价值标签
模型标签:基础标签、统计标签和已经存在的模型经过构建数据挖掘模型得到的,比如说客户的流失概率、违约概率
25.2 RFM模型
R:代表的是最后一次消费的时间(最新消费时间),可以代表用户的流失可能性,消费时间越久远,说明顾客的流失可能性越高
F:代表一段时间内消费的频次
M:一段时间内消费的总金额,可以代表顾客的价值
25.3 描述性统计分析
从总体数据中提炼变量的主要信息,完成业务分析报告
25.4 统计推断与统计建模
25.4.1 预测性

25.4.2 描述性

26、数据挖掘的技术与方法
27、描述性数据挖掘算法
27.1 聚类分析:客户细分
27.2 关联规则分析
28、预测性数据挖掘
21.1 决策树
21.2 knn算法
21.3 logistic回归
21.4 神经网络
21.5 支持向量机
21.6 集成学习
21.7 预测类模型
29、scikit-learn与机器学习
30、机器学习的基础知识点
从数据中自动分析获得规律,并且利用获取的规律进行预测的算法
30.1 特征值

30.2 目标值
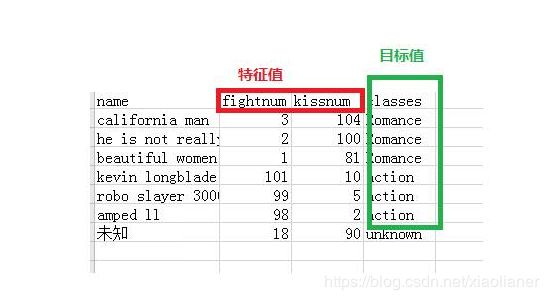
30.3 监督学习与非监督学习
训练集(training set/data)/训练样例(training examples): 用来进行训练,也就是产生模型或者算法的数据集
测试集(testing set/data)/测试样例 (testing examples):用来专门进行测试已经学习好的模型或者算法的数据集
一般情况下,训练集与测试集的比例一般是7:3,6:4,8:2
30.4 机器学习的步骤
8.1 把数据拆分为训练集和测试集
8.2 用训练集和训练集的特征向量来训练算法
8.2 用学习来的算法运用在测试集上来评估算法 (可能要设计到调整参数(parameter tuning), 用验证集(validation set)
30.5 监督学习的分类与算法
(1)分类
决策树 银行信用自动评估系统
临近取样 人脸识别
支持向量机 图片中的红眼检测 结肠癌早晚期分类
神经网络算法 手写数字识别 图片分类
(2)回归
线性回归 销售预测 价格预测
零线性回归
30.6 数据的类型
按照机器学习的数据分类
标称型:标称型目标变量的结果只在有限目标值中取值,比如说:去、不去(用于分类)
数值型:数值型的目标变量的结果在无限的数值集合中取值,比如说:100.1 ,10000.001(用于回归分析)
按照数据本身的分布特性
离散型:没有规律,数值只能用自然数或者整数单位计算的,比如公司人数、进球个数或者某个类别
连续型:存在规律,在指定的区间内,可以是任何一个数值,比如电影的票房,叶片的大小
31、 特征工程
更好的特征意味着更好的结果
更好的特征意味着更简单的模型
更好的特征意味这更强的鲁棒性
31.1 特征预处理
单个特征:
归一化、标准化、缺失值处理
多个特征:
降维:PCA降维
31.2 特征提取
现实生活中,存在很多特征不是连续变量,比如文字、图片以及分类,但是我们需要对他进行数学化表述,用到特征提取,所以将这些特征进行数学化描述的时候需要转换为特征提取
31.3 分类特征变量的提取
31.3.1 字典特征提取
from sklearn import feature_extraction
from sklearn.feature_extraction import DictVectorizer
data = [{'hair':'黑色','country':'中国'},{'hair':'棕色','country':'英国'},{'hair':'黑色','country':'西班牙'}]
def old():
dv = DictVectorizer()
#如果DictVectorizer(),没有进行任何设置使用默认值,转换出来的结果是一个稀疏矩阵
ret = dv.fit_transform(data)
print(ret)
print(dv.get_feature_names())
print(ret.toarray())
#稀疏矩阵可以使用toarray的方式转化成数组
def new():
dv = DictVectorizer(sparse=False)
#sparse=False代表直接转成数组
ret = dv.fit_transform(data)
print(ret)
print(dv.inverse_transform(ret))
#转化成原始数据
if __name__ == '__main__':
new()
31.3.2 文本特征提取
def text_handler():
# 文本数据分析
str1 = 'i love python'
str2 = 'good good study,day day up'
# 创建词频统计对象
# cv = CountVectorizer(stop_words='english')
cv = CountVectorizer(stop_words=['good'])
#CountVectorizer统计词语出现的个数
ret = cv.fit_transform([str1,str2])
print(cv.get_feature_names())
print(ret.toarray())
print(ret)
pass
注意点:
1、stop_words表示的是停用词,english表示使用英文停用词,如果需要自己指定,我们可以使用列表的方式写入
2、一般情况下,我们直接使用sparse矩阵,因为语料库非常庞大,
3、fit_transform填写可迭代对象
def text_handler_tf():
# 文本数据分析
str1 = 'i love python'
str2 = 'scikit-learn 是基于 Python 语言的机器学习工具。简单高效的数据挖掘和数据分析工具,可供大家在各种环境中重复使用'
new_str = cutword(str2)
print(new_str)
tv = TfidfVectorizer(stop_words=['大家'])
data = tv.fit_transform([str1,new_str])
print(tv.get_feature_names())
print(data.toarray())
当前的主旨:如果一个词在当前文章中出现的概率较高,但是在其他文件中出现的很少,所以,这个词能够代表文章主旨
中文分词工具
jieba,SnowNLP,NLPIR
31.3.3 jieba分词
模式:
全模式:将句子中所有的词组全部扫描出来
精确模式:cut_all=False,适用于文本分析
搜索引擎模式:搜索引擎分词
31.4 数据的特征预处理
31.4.1 归一化
出现问题:
在特征(维度)较多的时候,可以预防某一维或者几维对于数据的影响过大。例如身高170,体重50kg,所以将不同来源的数据归类到同一个参考区间下
常用方法:
(1)对于比较常见的方法,是使用线性转换将数据映射到[0,1]之间的区间,变换的函数是
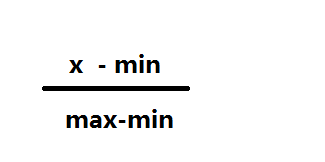
min:代表的是整个数据中的最小值
max:代表的是整个数据中的最大值
min和max的值,容易收到异常点的影响,并且在数据流的情况下,最大值和最小值是不断变化的
适用情况:适用于精确的小数据场景下
def minmax():
print('########原始数据#########')
print(data_old)
minmax = MinMaxScaler()
data = minmax.fit_transform(data_old)
print('######转换之后的数据######')
print(data)
31.4.2 标准化
经过处理之后,数据的均值为0,标准差1,处理函数:
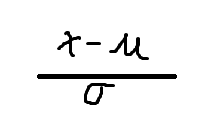
适用于比较稳定,嘈杂的数据场景
μ代表的是样本的平均值
σ 代表样本的标准差
将数据处理成符合正态分布的数据
def standar(dataset):
ss = StandardScaler()
data_new = ss.fit_transform(dataset)
return data_new
31.4.3 异常缺失值处理
strategy : string, optional (default="mean")
The imputation strategy.
- If "mean", then replace missing values using the mean along
the axis.
- If "median", then replace missing values using the median along
the axis.
- If "most_frequent", then replace missing using the most frequent
value along the axis.
填充策略
def handler_nan():
data = [[1,3],[np.nan,7],[9,11]]
im = Imputer()
data_new = im.fit_transform(data)
print(data_new)
注意点:
1、空值填充三种:均值,中位数,众数
2、axis=0代表的是列,axis=1 代表行
31.4.4 降维
主成分分析:PCA
PCA致力解决的问题:
第一,降维可以缓解维度灾难问题。
第二,降维可以在压缩数据的同时让信息损失最小化。
第三,理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解。

数据的降维,必然带来数据的损失
在降维之前保证每一个维度的重要性是等同的
https://blog.csdn.net/javastart/article/details/79748677
def __init__(self, n_components=None, copy=True, whiten=False,
svd_solver='auto', tol=0.0, iterated_power='auto',
random_state=None):
n_components:指定的是降维之后存在的特征的维度
whiten:白化,对降维之后的每一个特征进行归一化处理
def pca():
data = [[1,2,3,4],[3,4,5,6],[6,7,8,1]]
print('降维之前')
print(data)
pa = PCA(n_components=2)
data_new = pa.fit_transform(data)
print('#降维之后')
print(data_new)
注意点:
1、如果没有指定降维的个数的化,在原始的基础上,降下一维
2、降维不是指的数组的维度个数,而是说明的特征值的个数
31.4.5 特征选择
原因:
1、冗余:特征的相关度很高,容易消耗计算性能
2、噪声:部分特征对于最终的预测结果有负影响
特征选择方法:
1、filter过滤式VarianceThreshold(删除低方差数据)
2、emdedded 嵌入式:正则化、决策树
3、wrapper 包裹式
特征选择的功能
减少特征的数量,降维,减少过拟合
def vtd():
data = [[1, 0, 3, 4], [3, 4, 5, 0], [6, 7, 0, 1]]
print(data)
vt = VarianceThreshold(1)
ret = vt.fit_transform(data)
print(ret)
31.5 数据收集
数据的来源:
爬虫、买、实时数据、网上公开的数据集
数据处理成指定的格式
筛选数据
输入模型,进行训练
调优
保存模型
load开头的小数据集
fetch开头的是大数据集
make 本地数据集
from sklearn.datasets import *
data = load_iris()
print(data)
#获取的特征名
print(data.feature_names)
获取的特征数组
print(data.data)
获取的目标值名字
print(data.target_names)
获取的目标数组
print(data.target)
注意点:
加载本地数据集
data = fetch_20newsgroups()
print(data)
注意点:联网下载大数据集
data = make_classification()
print(data[0])
print(data[1])
生成本地的分类数据集
32、模型的选择
有监督学习(supervised learning): 训练集有类别标记(class label)
无监督学习(unsupervised learning): 无类别标记(class label)
半监督学习(semi-supervised learning):有类别标记的训练集 + 无标记的训练集
监督学习:
分类 K-近邻 决策树 贝叶斯 逻辑回归 支持向量机
回归 线性回归 岭回归
标注 隐马尔科夫(HMM)
无监督:
聚类
33、决策树
###33.1 信息熵
熵,热力学中表征物质状态的参量之一,用符号S表示,其物理意义是体系混乱程度的度量。
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。
直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
信息熵的单位:比特bit
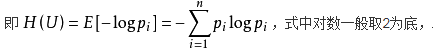
例子:猜世界杯冠军,假如一无所知,猜多少次?
33.2 关于节点的选择,算法(ID3)

33.3 案例实现
import pandas
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import LabelBinarizer
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
# import csv
# data = csv.reader('buy_computer.xlsx')
data = pandas.read_excel('buy_computer.xlsx')
x = data.loc[:,['age','income','student','credit_rating']]
y = data[['Class:buys_computer']]
print('#########特征集#######')
print(x)
print('###########目标集######')
print(y)
x_dict = x.to_dict(orient='records')
dv = DictVectorizer()
X = dv.fit_transform(x_dict).toarray()
print(dv.get_feature_names())
print(X)
Y = LabelBinarizer().fit_transform(y)
print(Y)
#导入自带的决策树模型
dtc = DecisionTreeClassifier(random_state=0)
#带入数据进行训练
dtc.fit(X,Y)
# 生成模型,进行预测
# y_predict = dtc.predict([[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]])
#展示出决策树
dot_data = tree.export_graphviz(feature_names=dv.get_feature_names(),decision_tree=dtc,out_file=None,rounded=True,filled=True,special_characters=True)
print(dot_data)
import pydotplus
gra = pydotplus.graph_from_dot_data(dot_data)
print(gra)
# gra.write_pdf('file.pdf')
33.4 优缺点
决策树的优点: 直观,便于理解,小规模数据集有效,对于数据只需要较少的处理
决策树的缺点: 处理连续变量不好 类别较多时,错误增加的比较快 可规模性一般,不能处理过于复杂的树,决策树不太稳定,因为数据细小的变化
33.5 算法选择
C4.5: Quinlan Classification and Regression Trees
(CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)
共同点:都是贪心算法,自上而下(Top-down approach)
区别:属性选择度量方法不同: C4.5 (gain ratio), CART(gini index), ID3 (Information Gain)
##34 、K近邻(knn)
34.1 超参数
k
34.2 k近邻的距离

欧式距离
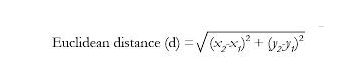
34.3 pandas的展示
import pandas as pd
import numpy as np
dataset = pd.read_excel('./knn案例.xls')
print(dataset)
feature = dataset.iloc[:-1,[1,2]]
print(feature)
x_unknown,y_unknown = (18,90)
feature['new_x'] = (feature[['fightnum']]-x_unknown)**2
feature['new_y'] = (feature[['kissnum']]-y_unknown)**2
feature['distance'] = (feature['new_x']+feature['new_y'])**(1/2)
print(feature)
34.4 sklearn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
data_set = load_iris()
# print(data_set)
features = data_set.data
lables = data_set.target
print(features)
print(lables)
X_train, X_test, y_train, y_test = train_test_split(features,lables,test_size=0.23)
'''
X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.33, random_state=42)
'''
knn_cls = KNeighborsClassifier()
knn_cls.fit(X_train,y_train)
y_pedict = knn_cls.predict(X_test)
print('这是原始测试集的目标值')
print(y_test)
print('预测数据')
print(y_pedict)
score = knn_cls.score(X_test,y_test)
print('得分')
print(score)
34.5 分类器性能
| 正例 | 假例 | |
|---|---|---|
| 正例 | 真正例(TP) | 伪反例(FN) |
| 假例 | 伪正例(FP) | 真反例(TN) |
精确率:预测结果为正例样本中真实为正例的比例(查的准)
召回率:真实为正例的样本中预测结果为正例的比例(查的全)
准确率 = 预测对的/所有 = (TP+TN)/(TP+FP+FN+TN)
精确率 = TP/(TP+FP)
召回率 = TP/(TP+FN)
调和平均数 F1
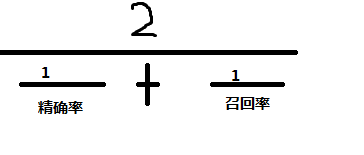
如果精确率和召回率差距过大的模型,没有意义再使用,
F1表示了模型的稳健性
34.6 K值对与模型的影响
K过小,容易收到噪声数据的影响
K过大,容易收到数量的影响
34.7 优缺点
优点:
简单
易于理解
容易实现
通过对K的选择可具备丢噪音数据的健壮性
缺点:
需要大量空间储存所有已知实例
算法复杂度高(需要比较所有已知实例与要分类的实例)
当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本
使用场景
适用于小数据场景,几千--几万的数据量
35、朴素贝叶斯
非常简单,但是实用性很强的模型,解决分类问题
基础:贝叶斯理论
概率:一件事情发生的可能性
一件事情的概率记成:P(X),大于等于0,小于等于1
35.1 联合概率与条件概率
联合概率:包含多个条件,且条件同时成立的概率
P(A,B) = P(A)P(B)
条件概率:事件A在另外一个事件B已经发生的条件下发生概率
P(A|B)
特性
P(A1,A2|B) = P(A1|B)*P(A2|B)
注意点
条件概率成立,建立在A1,A2相互独立的基础上
35.2 朴素贝叶斯公式
P(C|W) = P(W|C)P(C)/P(W)
C是指文档的类别
W为给定文章的特征值
P(C|F1,F2,F3........) = P(F1,F2,F3|C)P(C)/P(F1,F2,F3.......)
P(C)是指每个文档类别的概率(文档的类别/总文档数)
P(F1,F2,F3|C) = 在给定的类别情况下,特征出现的概率
P(F1,F2,F3.......)预测文档中每一个词的概率
p(影院,支付宝,云计算|科技)*P(科技)=0.0045
p(影院,支付宝,云计算|娱乐)*P(娱乐)=0
35.3 拉普拉斯平滑系数
a= "life is short,i like python’
b= “life is too long,i dislike python”
C =“yes,i like python”
label=[1,0,1]
贝叶斯公式: p(ci|W) = p(w|ci)p(ci)/p(W)
ci是类别
w:特征向量
出现的原因:
在进行词频统计的时候,可能会出现多个词语出现次数为0的情况,算出来的该楼层可能为0,但是是不合理的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l2KasAdC-1576206861915)(image-20191121162352871.png)]
a为指定的系数,一般为1,m为特征词出现的个数
35.4 优缺点
由古典的数学理论,所以有稳定的分类效率
分类准确率较高,速度快
适用于文本分析
缺点:
建立在样本属性相互独立的基础上,如果属性之间存在相关联的情况下,分类效果不好
36 、SVM
36.1 过拟合与欠拟合的情况

36.2 参数的问题
kernel='linear'时,为线性核,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
kernel='rbf'时(default),为高斯核,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
decision_function_shape='ovr'时,为one v rest,即一个类别与其他类别进行划分,
decision_function_shape='ovo'时,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
def __init__(self,
C=1.0, # 惩罚系数,c越大,说明错误分类的惩罚在增大,对于我们的训练集的准确率会非常高,但是泛化能力降低,会出现过拟合的情况,c越小,对错误分类的惩罚变小,容错情况增强,泛化能力增强,可能会出现欠拟合的情况
kernel='rbf', degree=3, gamma='auto_deprecated',
coef0=0.0, shrinking=True, probability=False,
tol=1e-3, cache_size=200, class_weight=None,
verbose=False, max_iter=-1, decision_function_shape='ovr',
random_state=None):
37 、线性回归
37.1 线性回归的基本介绍
简单线性回归(Simple Linear Regression)
1 很多做决定过过程通常是根据两个或者多个变量之间的关系
2 回归分析(regression analysis)用来建立方程模拟两个或者多个变量之间如何关联
3 被预测的变量叫做:因变量(dependent variable), y, 输出(output)
4 被用来进行预测的变量叫做: 自变量(independent variable), x, 输入(input)
37.2 简单线性回归介绍
1 简单线性回归包含一个自变量(x)和一个因变量(y)
2 以上两个变量的关系用一条直线来模拟
3 如果包含两个以上的自变量,则称作多元回归分析(multiple regression)
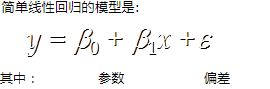
简单线性回归方程
E(y) = β0+β1x
这个方程对应的图像是一条直线,称作回归线
其中,
β0是回归线的截距
β1是回归线的斜率
E(y)是在一个给定x值下y的期望值(均值)
正向关系、负向关系、无关系
β1 >0 β1<0 β1=0
37.3 多元线性回归
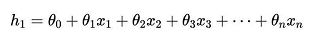
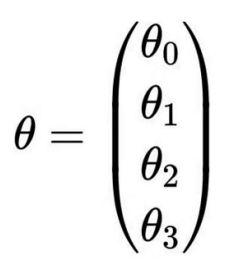

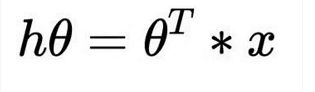
注意:特殊的是X0为1
37.4损失函数(误差大小)
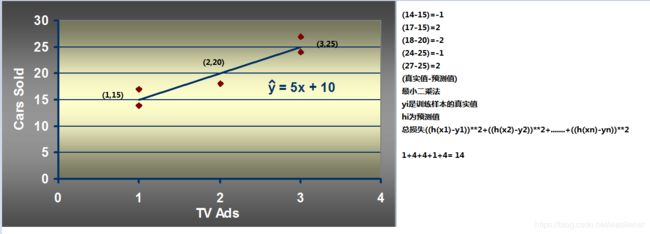
损失函数:
![]()
是的损失函数是最小值:误差是最小的
(1)使用梯度下降算法
(2)正规方程(简单的线性回归)
37.5 正规方程
![]()
X是指特征值矩阵
y目标值矩阵缺点:特征值过于复杂的时候,求解速度太慢了
37.6 梯度下降算法
以单变量为例

a是指学习速率

这个过程按照某一点在W1上的偏导数下降来寻找最低点
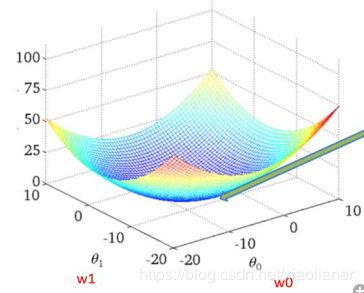
函数的意义:沿着这个函数的下降的方向,找到山谷的最低点,不断的取更新w的值
37.7 均方误差(MSE)
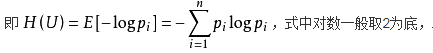
from sklearn.metrics import mean_squared_error
def mean_squared_error(y_true, y_pred,
sample_weight=None,
multioutput='uniform_average'):
注意点:
1、真实值与预测值为标准化之前的值
2、返回值是一个浮点型数据
37.7 梯度下降与正规方程的对比
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要多次迭代 | 一次运算就可以了 |
| 当特征量很多的时候,适用情况很好 | 需要计算,如果特征数量很大的化,计算比较大,因为矩阵逆的计算时间复杂度为o(n**3) |
| 适用与各种模型的计算 | 只适合于线性模型,不适合逻辑回归模型 |
小规模数据集 :正规方程
大规模数据集:SGD
37.8 过拟合与欠拟合

| 过拟合 | 在训练集上获得更好的拟合,但是在训练集以外的数据集上表现很差 |
|---|---|
| 欠拟合 | 在训练集上表现不好,在训练集以外的数据集上表现也不好 |
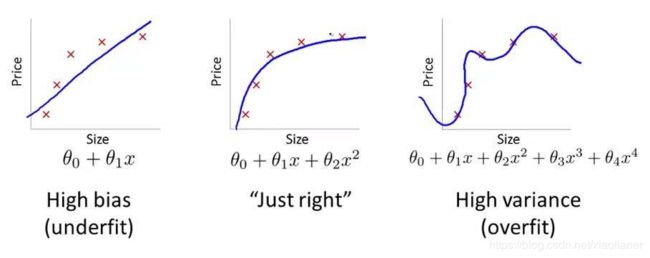
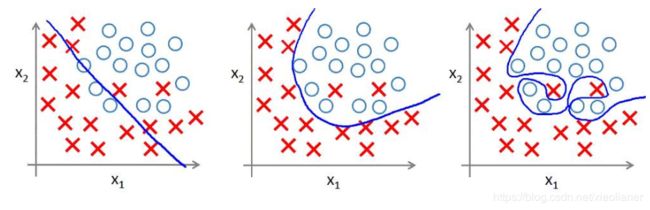
37.9 解决过拟合与欠拟合的问题
解决:
欠拟合:
原因:学习到的特征过少
解决:增加特征数量
过拟合:
原因:原始输入的数据的特征过多,存在一些没有必要的嘈杂数据,模型之所以过于复杂,是因为模型想要更多的取匹配兼顾每一个数据点
解决:
1、进行特征的选择,消除一些关联数据较大的特征(最困难)
2、交叉验证
3、正则化
37.10 L2正则化
![]()

优点:
参数越小,说明模型越简单,模型越简单就越不容易出现过拟合的现象
37.11 岭回归
具有L2正则化的线性最小二乘法
from sklearn.linear_model import Ridge
from sklearn.linear_model import Ridge,RidgeCV
37.12 线性回归与岭回归
岭回归,在病态数据较多的时候,岭回归具有更高的价值,使模型估计参数更加的稳定
38、模型的调优
38.1 交叉验证
目的:为了让被评估的模型更加的准确
步骤:
1、将拿到的训练数据,再次分为训练集和验证集
2、将多次训练的模型结果取平均值作为最终的结果

38.2 网格搜索
为了查找到最优的参数组合来创建模型
| k近邻的值 | k=1 | k=3 | k=7 |
|---|---|---|---|
| 模型 | 模型1 | 模型2 | 模型3 |
接口:
from sklearn.model_selection import GridSearchCV
参数:
estimator : estimator object. 估计器:分类器和回归器
param_grid : dict or list of dictionaries 估计器的参数,其中以字典类型写入{'n_neighbors':[1,3,7]}
cv : 几折交叉验证
结果:
#在交叉验证中最好的结果
print(gsc.best_ score_ )
#最好的参数模型
print(gsc.best_ estimator_ )
#每次交叉验证的测试集隹确率结果和训练集准确率结果
print(gsc.cv_ results_ )
使用网格搜索的步骤:
1、确定超参数,使用的是字典
2、创建网格搜索模型,传入超参数:估计器,超参数,CV
3、使用fit来训练模型,传入指定的训练集
4、查看最终的结果,可以将最好的模型保存起来
39 、逻辑回归
目的:解决的是二分类问题
39.1 sigmod
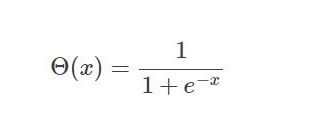
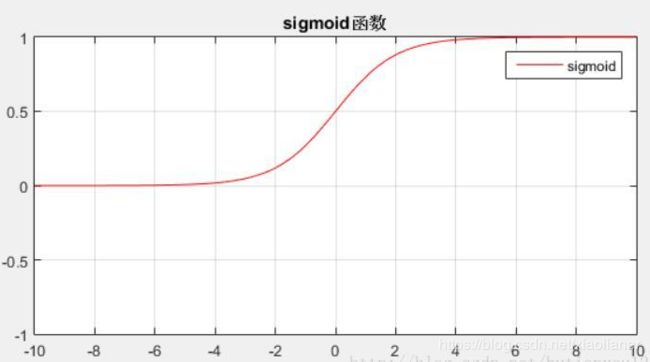
注意点:
sigmod的取值范围在(0,1)之间
39.2 逻辑回归的公式
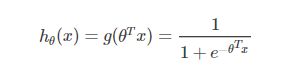
让线性回归的结果进行sigmod的激活,转成了(0,1)之间的数据,默认情况下,取值为0.5作为阈值
39.3 对数似然损失函数
目的:由于是分类问题,损失函数不能使用原始的线性模型的损失函数
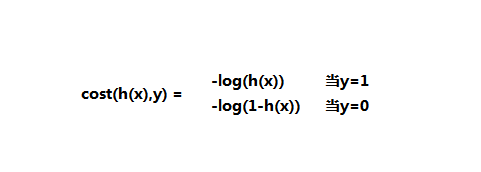
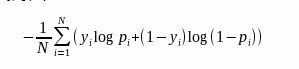
注意点:
yi 为输入实例 xi 的真实类别, pi 为预测输入实例 xi 属于类别 1 的概率. 对所有样本的对数损失表示对每个样本的对数损失的平均值, 对于完美的分类器, 对数损失为 0 .
39.4 逻辑回归的api
from sklearn.linear_model import LogisticRegression
39.5 局限性问题
适用于二分类问题
如果需要适用多分类,需要借助softmax
40、聚类
k-means:劳埃德算法
非监督学习经典算法:
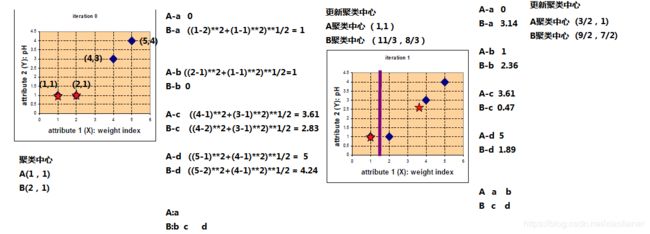
40.1 流程(算法描述)
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的中心所在 的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束, 否则继续迭代。
40.2 优缺点
优点:速度快,简单
缺点:最终结果跟初始点选择相关,容易陷入局部最优,需直到k值
41、 层次聚类
41.1 计算距离的方法
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。这里介绍一下三种:
SingleLinkage:又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
CompleteLinkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
Average-linkage:这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。
41.2 图例
1、(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2、寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3、重新计算新生成的这个类与各个旧类之间的相似度;
4、重复2和3直到所有样本点都归为一类,结束
42 、集成学习
建立多个模型的组合,来解决单一预测问题
生成多个模型
42.2 随机森林
随机森林包含多个决策树,其中最终结果由每个树的结果的众数来决定
from sklearn.ensemble import RandomForestClassifier
def __init__(self,
n_estimators=10, #为了确定随机森林里面存在几棵树
criterion="gini",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features="auto",
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=1,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None):
42.3 随机森林的优缺点
优点:
1、在当前的算法当中,准确率极好
2、运行大数据集
3、能够处理高维数据,不需要降维,直接用
43 、描述性统计分析与绘图
43.1 基本概念
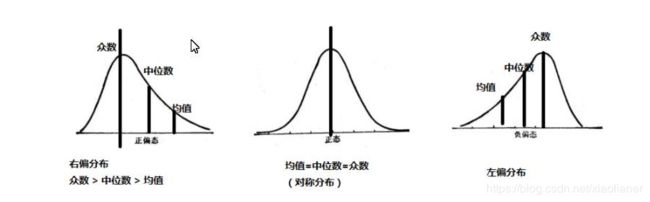
43.2 表分析
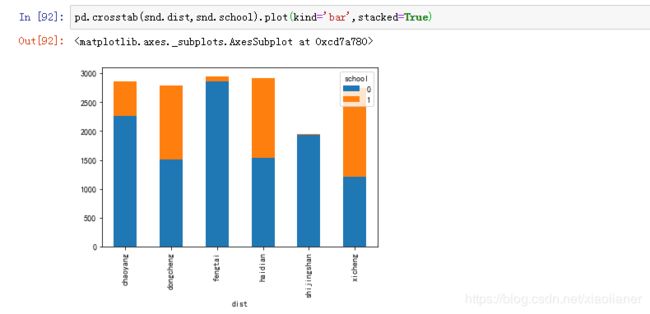

43.3 分类汇总
groupby
43.4 汇总表
snd1.pivot_table(
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All',
)
Docstring:
Create a spreadsheet-style pivot table as a DataFrame. The levels in
the pivot table will be stored in MultiIndex objects (hierarchical
indexes) on the index and columns of the result DataFrame.
Parameters
----------
values : column to aggregate, optional
index : column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The
list can contain any of the other types (except list).
Keys to group by on the pivot table index. If an array is passed,
it is being used as the same manner as column values.
columns : column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The
list can contain any of the other types (except list).
Keys to group by on the pivot table column. If an array is passed,
it is being used as the same manner as column values.
aggfunc : function, list of functions, dict, default numpy.mean
If list of functions passed, the resulting pivot table will have
hierarchical columns whose top level are the function names
(inferred from the function objects themselves)
If dict is passed, the key is column to aggregate and value
is function or list of functions
fill_value : scalar, default None
Value to replace missing values with
margins : boolean, default False
Add all row / columns (e.g. for subtotal / grand totals)
dropna : boolean, default True
Do not include columns whose entries are all NaN
margins_name : string, default 'All'
Name of the row / column that will contain the totals
when margins is True.
Returns
44、数据的清洗与处理
44.1 缺失值的处理
当缺失值少于20%的时候,建议用均值和中位数进行填补
| 连续变量 | 分类变量 | |
|---|---|---|
| 缺失值少于20% | 均值或者中位数 | 不需要填补,单算一类或者用众数补充 |
| 缺失值在20%到80%之间 | 均值或者中位数 | 不需要填补,单算一类或者用众数补充 |
| 缺失值在80%以上 | 每一个有缺失值的变量生成一个指示哑变量,参与建模,不再参与原始数据 |
44.2 噪声处理
噪声值是指该数据中有一个或者多个数据与其他数据存在较大差异值
噪声值,异常值,离群值
| 单变量 | 盖帽法,分箱法 |
| 多变量 | 聚类 |
44.2.1 盖帽法
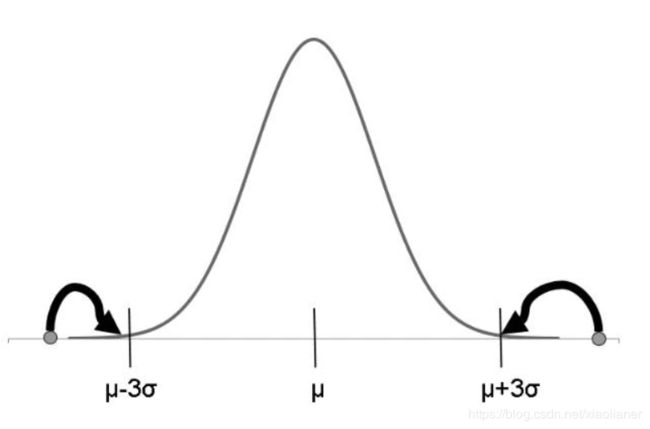
盖帽法将某连续变量均值上下三倍标准差范围外的记录替换为均值上下三倍标准差值,即盖帽处理
默认情况:
将小于1%分位数和大于99%分位数的值直接替换成1%或者99%
# 计算百分位数据
per1=df1.Age.quantile(0.01)
per1
per2=df1.Age.quantile(0.99)
per2
def change(per1,per2):
pass
def func(x):
if xper2:
x=per2
elif per1<=x and x<=per2:
x=x
else:
x=0
return x
df1.Age.apply(func)
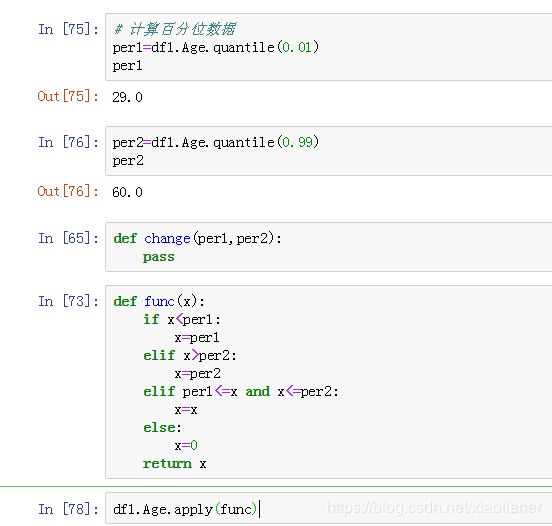
44.2.2 分箱法

![]()
45、分类器性能评估
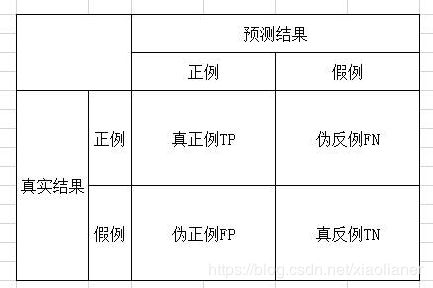
第一个正确率
TP/(TP+FP)
第二个指标召回率
TP/(TP+FN) :预测为真的情况下的正例的比例
46、
47、神经网络算法

47.1 神经网络基础知识点
1、多层神经网络
2、神经网络由输入层、隐藏层。输出层组成
3、每层由多个单元组成,每个单元叫做神经节点(生物学定义)
4、以上的神经网络称为两层神经网络,(输入层不计入)
5、隐藏层理论上可以存在多个,如果有足够多的隐藏层和足够大的训练量,可以模拟任何方程
47.2 设计神经网络的结构
1、在使用神经网络训练数据之前需要确定神经网络的层数
2、确定每一层有多少个神经节点
3、特征向量在被传入输入层之前通常需要进行标准化0和1之间(加速学习)
47.3 BP神经网络
一般情况下,BP会应用在向前神经网络中
反方向进行算法迭代(输出层隐藏层=输入层),进行权重的更新
47.4 基础散发以及公式
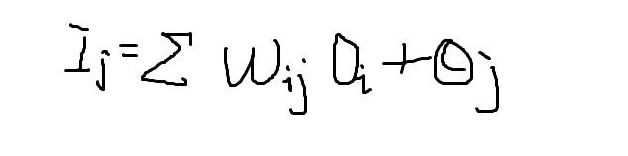

BP神经网络进行反向修正的算法:
1、隐藏层误差计算