简介
Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository 层中解耦出来,除了这些基本功能外,它还提供了动态 sql、延迟加载、缓存等功能。 相比 Hibernate,Mybatis 更面向数据库,可以灵活地对 sql 语句进行优化。
本文继续分析 Mybatis 的源码,第1点内容上一篇博客已经讲过,本文将针对 2 和 3 点继续分析:
- 加载配置、初始化
SqlSessionFactory; - 获取
SqlSession和Mapper; - 执行
Mapper方法。
除了源码分析,本系列还包含 Mybatis 的详细使用方法、高级特性、生成器等,相关内容可以我的专栏 Mybatis 。
注意,考虑可读性,文中部分源码经过删减。
隐藏在Mapper背后的东西
从使用者的角度来看,项目中使用 Mybatis 时,我们只需要定义Mapper接口和编写 xml,除此之外,不需要去使用 Mybatis 的其他东西。当我们调用了 Mapper 接口的方法,Mybatis 悄无声息地为我们完成参数设置、语句执行、结果映射等等工作,这真的是相当优秀的设计。
既然是分析源码,就必须搞清楚隐藏 Mapper 接口背后都是什么东西。这里我画了一张 UML 图,通过这张图,应该可以对 Mybatis 的架构及 Mapper 方法的执行过程形成比较宏观的了解。
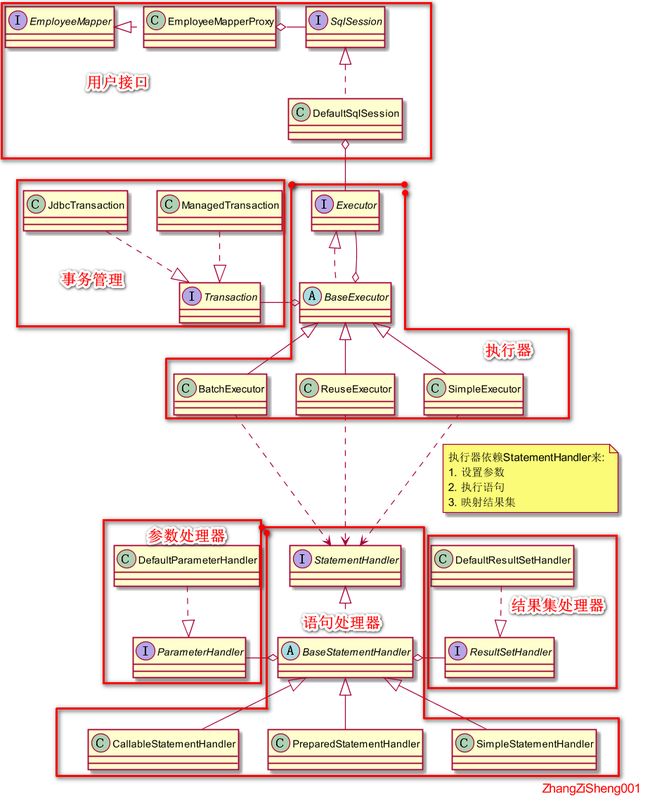
针对上图,我再简单梳理下:
Mapper和SqlSession可以认为是用户的入口(项目中也可以不用Mapper接口,直接使用SqlSession),Mybatis 为我们生产的Mapper实现类最终都会去调用SqlSession的方法;Executor作为整个执行流程的调度者,它依赖StatementHandler来完成参数设置、语句执行和结果映射,使用Transaction来管理事务。StatementHandler调用ParameterHandler为语句设置参数,调用ResultSetHandler将结果集映射为所需对象。
那么,我们开始看源码吧。
Mapper代理类的获取
一般情况下,我们会先拿到SqlSession对象,然后再利用SqlSession获取Mapper对象,这部分的源码也是按这个顺序开展。
// 获取 SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取 Mapper
EmployeeMapper baseMapper = sqlSession.getMapper(EmployeeMapper.class);
先拿到SqlSession对象
SqlSession的获取过程
上一篇博客讲了DefaultSqlSessionFactory的初始化,现在我们将利用DefaultSqlSessionFactory来创建SqlSession,这个过程也会创建出对应的Executor和Transaction,如下图所示。

图中的SqlSession创建时需要先创建Executor,而Executor又要依赖Transaction的创建,Transaction则需要依赖已经初始化好的TransactionFactory和DataSource。
进入到DefaultSqlSessionFactory.openSession()方法。默认情况下,SqlSession是线程不安全的,主要和Transaction对象有关,如果考虑复用SqlSession对象的话,需要重写Transaction的实现。
@Override
public SqlSession openSession() {
// 默认会使用SimpltExecutors,以及autoCommit=false,事务隔离级别为空
// 当然我们也可以在入参指定
// 补充:SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(PreparedStatement);BATCH 执行器不仅重用语句还会执行批量更新。
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 获取Environment中的TransactionFactory和DataSource,用来创建事务对象
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建执行器,这里也会给执行器安装插件
final Executor executor = configuration.newExecutor(tx, execType);
// 创建DefaultSqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
如何给执行器安装插件
上面的代码比较简单,这里重点说下安装插件的过程。我们进入到Configuration.newExecutor(Transaction, ExecutorType),可以看到创建完执行器后,还需要给执行器安装插件,接下来就是要分析下如何给执行器安装插件。
protected final InterceptorChain interceptorChain = new InterceptorChain();
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根据executorType选择创建不同的执行器
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 安装插件
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
进入到InterceptorChain.pluginAll(Object)方法,这是一个相当通用的方法,不是只能给Executor安装插件,后面我们看到的StatementHandler、ResultSetHandler、ParameterHandler等都会被安装插件。
private final List interceptors = new ArrayList<>();
public Object pluginAll(Object target) {
// 遍历安装所有执行器
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
// 进入到Interceptor.plugin(Object)方法,这个是接口里的方法,使用 default 声明
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
在定义插件时,一般我们都会采用注解来指定需要拦截的接口及其方法,如下。安装插件的方法之所以能够通用,主要还是@Signature注解的功劳,注解中,我们已经明确了拦截哪个接口的哪个方法。注意,这里我也可以定义其他接口,例如StatementHandler。
@Intercepts(
{
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
}
)
public class PageInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
// do something
}
}
上面这个插件将对Executor接口的以下两个方法进行拦截:
List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
那么,Mybatis 是如何实现的呢?我们进入到Plugin这个类,它是一个InvocationHandler,也就是说 Mybatis 使用的是 JDK 的动态代理来实现插件功能,后面代码中, JDK 的动态代理也会经常出现。
public class Plugin implements InvocationHandler {
// 需要被安装插件的类
private final Object target;
// 需要安装的插件
private final Interceptor interceptor;
// 存放插件拦截的接口接对应的方法
private final Map, Set> signatureMap;
private Plugin(Object target, Interceptor interceptor, Map, Set> signatureMap) {
this.target = target;
this.interceptor = interceptor;
this.signatureMap = signatureMap;
}
public static Object wrap(Object target, Interceptor interceptor) {
// 根据插件的注解获取插件拦截哪些接口哪些方法
Map, Set> signatureMap = getSignatureMap(interceptor);
// 获取目标类中需要被拦截的所有接口
Class type = target.getClass();
Class[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
// 创建代理类
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap));
}
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 以“当前方法的声明类”为key,查找需要被插件拦截的方法
Set methods = signatureMap.get(method.getDeclaringClass());
// 如果包含当前方法,那么会执行插件里的intercept方法
if (methods != null && methods.contains(method)) {
return interceptor.intercept(new Invocation(target, method, args));
}
// 如果并不包含当前方法,则直接执行该方法
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
以上就是获取SqlSession和安装插件的内容。默认情况下,SqlSession是线程不安全的,不断地创建SqlSession也不是很明智的做法,按道理,Mybatis 应该提供线程安全的一套SqlSession实现才对。
再获取Mapper代理类
Mapper 代理类的获取过程比较简单,这里我们就不一步步看源码了,直接看图就行。我画了 UML 图,通过这个图基本可以梳理以下几个类的关系,继而明白获取 Mapper 代理类的方法调用过程,另外,我们也能知道,Mapper 代理类也是使用 JDK 的动态代理生成。

Mapper 作为一个用户接口,最终还是得调用SqlSession来进行增删改查,所以,代理类也必须持有对SqlSession的引用。通常情况下,这样的 Mapper代理类是线程不安全的,因为它持有的SqlSession实现类DefaultSqlSession也是线程不安全的,但是,如果实现类是SqlSessionManager就另当别论了。
Mapper方法的执行
执行Mapper代理方法
因为Mapper代理类是通过 JDK 的动态代理生成,当调用Mapper代理类的方法时,对应的InvocationHandler对象(即MapperProxy)将被调用,所以,这里就不展示Mapper代理类的代码了,直接从MapperProxy这个类开始分析。
同样地,还是先看看整个 UML 图,通过图示大致可以梳理出方法的调用过程。MethodSignature这个类可以重点看下,它的属性非常关键。
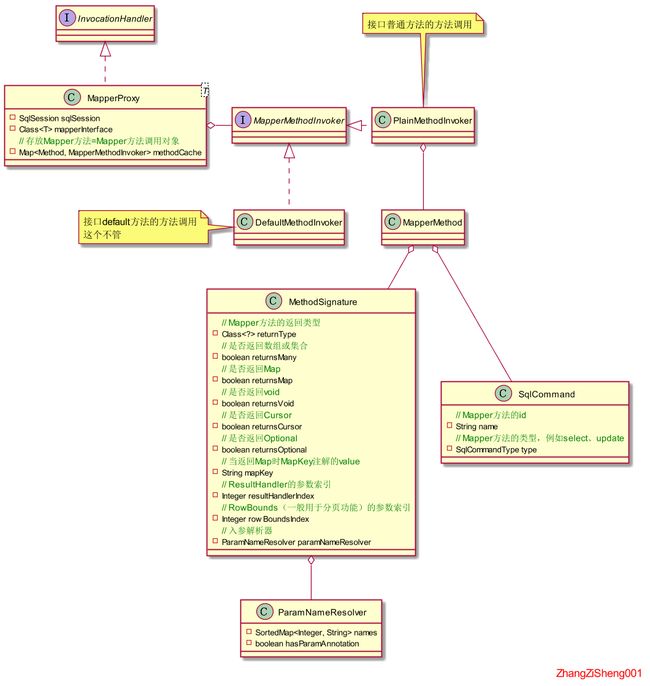
下面开始看源码,进入到MapperProxy.invoke(Object, Method, Object[])。这里的MapperMethodInvoker对象会被缓存起来,因为这个类是无状态的,不需要反复的创建。当缓存中没有对应的MapperMethodInvoker时,方法对应的MapperMethodInvoker实现类将被创建并放入缓存,同时MapperMethod、MethodSignature、sqlCommand等对象都会被创建好。
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 如果是Object类声明的方法,直接调用
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 先从缓存拿到MapperMethodInvoker对象,再调用它的方法
// 因为最终会调用SqlSession的方法,所以这里得传入SqlSession对象
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
// 缓存有就拿,没有需创建并放入缓存
return methodCache.computeIfAbsent(method, m -> {
// 如果是接口中定义的default方法,创建MapperMethodInvoker实现类DefaultMethodInvoker
// 这种情况我们不关注
if (m.isDefault()) {
try {
if (privateLookupInMethod == null) {
return new DefaultMethodInvoker(getMethodHandleJava8(method));
} else {
return new DefaultMethodInvoker(getMethodHandleJava9(method));
}
} catch (IllegalAccessException | InstantiationException | InvocationTargetException
| NoSuchMethodException e) {
throw new RuntimeException(e);
}
} else {
// 如果不是接口中定义的default方法,创建MapperMethodInvoker实现类PlainMethodInvoker,在此之前也会创建MapperMethod
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
});
} catch (RuntimeException re) {
Throwable cause = re.getCause();
throw cause == null ? re : cause;
}
}
由于我们不考虑DefaultMethodInvoker的情况,所以,这里直接进入到MapperProxy.PlainMethodInvoker.invoke(Object, Method, Object[], SqlSession)。
private final MapperMethod mapperMethod;
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
// 直接调用MapperMethod的方法,method和proxy的入参丢弃
return mapperMethod.execute(sqlSession, args);
}
进入到MapperMethod.execute(SqlSession, Object[])方法。前面提到过 Mapper 代理类必须依赖SqlSession对象来进行增删改查,在这个方法就可以看到,方法中会通过方法的类型来决定调用SqlSession的哪个方法。
在进行参数转换时有三种情况:
-
如果参数为空,则 param 为 null;
-
如果参数只有一个且不包含
Param注解,则 param 就是该入参对象; -
如果参数大于一个或包含了
Param注解,则 param 是一个Map,key 为注解Param的值,value 为对应入参对象。
另外,针对 insert|update|delete 方法,Mybatis 支持使用 void、Integer/int、Long/long、Boolean/boolean 的返回类型,而针对 select 方法,支持使用 Collection、Array、void、Map、Cursor、Optional 返回类型,并且支持入参 RowBounds 来进行分页,以及入参 ResultHandler 来处理返回结果。
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 判断属于哪种类型,来决定调用SqlSession的哪个方法
switch (command.getType()) {
// 如果为insert类型方法
case INSERT: {
// 参数转换
Object param = method.convertArgsToSqlCommandParam(args);
// rowCountResult将根据返回类型来处理result,例如,当返回类型为boolean时影响的rowCount是否大于0,当返回类型为int时,直接返回rowCount
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
// 如果为update类型方法
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
// 如果为delete类型方法
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
// 如果为select类型方法
case SELECT:
// 返回void,且入参有ResultHandler
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
// 返回类型为数组或List
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
// 返回类型为Map
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
// 返回类型为Cursor
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
// 这种一般是返回单个实体对象或者Optional对象
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
// 如果为FLUSH类型方法,这种情况不关注
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
// 当方法返回类型为基本类型,但是result却为空,这种情况会抛出异常
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
增删改的我们不继续看了,至于查的,只看method.returnsMany()的情况。进入到MapperMethod.executeForMany(SqlSession, Object[])。通过这个方法可以知道,当返回多个对象时,Mapper 中我们可以使用List接收,也可以使用数组或者Collection的其他子类来接收,但是处于性能考虑,如果不是必须,建议还是使用List比较好。
将RowBounds作为 Mapper 方法的入参,可以支持自动分页功能,但是,这种方式存在一个很大缺点,就是 Mybatis 会将所有结果查放入本地内存再进行分页,而不是查的时候嵌入分页参数。所以,这个分页入参建议不要单独使用,最好配合插件一起使用。
private Object executeForMany(SqlSession sqlSession, Object[] args) {
List result;
// 转换参数
Object param = method.convertArgsToSqlCommandParam(args);
// 如果入参包含RowBounds对象,这个一般用于分页使用
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.selectList(command.getName(), param, rowBounds);
} else {
// 不用分页的情况
result = sqlSession.selectList(command.getName(), param);
}
// 如果SqlSession方法的返回类型和Mapper方法的返回类型不一致
// 例如,mapper返回类型为数组、Collection的其他子类
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
// 如果mapper方法要求返回数组
if (method.getReturnType().isArray()) {
return convertToArray(result);
} else {
// 如果要求返回Set等Collection子类,这个方法感兴趣的可以研究下,非常值得借鉴学习
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
}
return result;
}
从Mapper进入到SqlSession
接下来就需要进入SqlSession的方法了,这里选用实现类DefaultSqlSession进行分析。SqlSession作为用户入口,代码不会太多,主要工作还是通过执行器来完成。
在调用执行器方法之前,这里会对参数对象再次包装,一般针对入参只有一个参数且不包含Param注解的情况:
- 如果是
Collection子类,将转换为放入"collection"=object键值对的 map,如果它是List的子类,还会再放入"list"=object的键值对 - 如果是数组,将转换为放入
"array"=object键值对的 map
@Override
public List selectList(String statement, Object parameter) {
// 这里还是给它传入了一个分页对象,这个对象默认分页参数为0,Integer.MAX_VALUE
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
// 利用方法id从配置对象中拿到MappedStatement对象
MappedStatement ms = configuration.getMappedStatement(statement);
// 接着执行器开始调度,传入resultHandler为空
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
执行器开始调度
接下来就进入执行器的部分了。注意,由于本文不会涉及到 Mybatis 结果缓存的内容,所以,下面的代码都会删除缓存相关的部分。
那么,还是回到最开始的图,接下来将选择SimpleExecutor进行分析。
进入到BaseExecutor.query(MappedStatement, Object, RowBounds, ResultHandler)。这个方法中会根据入参将动态语句转换为静态语句,并生成对应的ParameterMapping。
例如,
and e.gender = {con.gender}
将被转换为 and e.gender = ?,并且生成
ParameterMapping{property='con.gender', mode=IN, javaType=class java.lang.Object, jdbcType=null, numericScale=null, resultMapId='null', jdbcTypeName='null', expression='null'}
的ParameterMapping。
生成的ParameterMapping将根据?的索引放入集合中待使用。
这部分内容我就不展开了,感兴趣地可以自行研究。
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 将sql语句片段中的动态部分转换为静态,并生成对应的ParameterMapping
BoundSql boundSql = ms.getBoundSql(parameter);
// 生成缓存的key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
接下来一大堆关于结果缓存的代码,前面说过,本文不讲,所以我们直接跳过进入到SimpleExecutor.doQuery(MappedStatement, Object, RowBounds, ResultHandler, BoundSql)。可以看到,接下来的任务都是由StatementHandler来完成,包括了参数设置、语句执行和结果集映射等。
@Override
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 获取StatementHandler对象,在上面的UML中可以看到,它非常重要
// 创建StatementHandler对象时,会根据StatementType自行判断选择SimpleStatementHandler、PreparedStatementHandler还是CallableStatementHandler实现类
// 另外,还会给它安装执行器的所有插件
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 获取Statement对象,并设置参数
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行语句,并映射结果集
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
本文将对以下两行代码分别展开分析。其中,关于参数设置的内容不会细讲,更多地精力会放在结果集映射上面。
// 获取Statement对象,并设置参数
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行语句,并映射结果集
return handler.query(stmt, resultHandler);
语句处理器开始处理语句
在创建StatementHandler时,会通过MappedStatement.getStatementType()自动选择使用哪种语句处理器,有以下情况:
- 如果是 STATEMENT,则选择
SimpleStatementHandler; - 如果是 PREPARED,则选择
PreparedStatementHandler; - 如果是 CALLABLE,则选择
CallableStatementHandler; - 其他情况抛出异常。
本文将选用PreparedStatementHandler进行分析。
获取语句对象和设置参数
进入到SimpleExecutor.prepareStatement(StatementHandler, Log)。这个方法将会获取当前语句的PreparedStatement对象,并给它设置参数。
protected Transaction transaction;
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取连接对象,通过Transaction获取
Connection connection = getConnection(statementLog);
// 获取Statement对象,由于分析的是PreparedStatementHandler,所以会返回实现类PreparedStatement
stmt = handler.prepare(connection, transaction.getTimeout());
// 设置参数
handler.parameterize(stmt);
return stmt;
}
进入到PreparedStatementHandler.parameterize(Statement)。正如 UML 图中说到的,这里实际上是调用ParameterHandler来设置参数。
protected final ParameterHandler parameterHandler;
@Override
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
进入到DefaultParameterHandler.setParameters(PreparedStatement)。前面讲过,在将动态语句转出静态语句时,生成了语句每个?对应的ParameterMapping,并且这些ParameterMapping会按照语句中对应的索引被放入集合中。在以下方法中,就是遍历这个集合,将参数设置到PreparedStatement中去。
private final TypeHandlerRegistry typeHandlerRegistry;
private final MappedStatement mappedStatement;
private final Object parameterObject;
private final BoundSql boundSql;
private final Configuration configuration;
@Override
public void setParameters(PreparedStatement ps) {
// 获得当前语句对应的ParameterMapping
List parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
// 遍历ParameterMapping
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 一般情况mode都是IN,至于OUT的情况,用于结果映射到入参,比较少用
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;// 用于设置到ps中的?的参数
// 这个propertyName对应mapper中#{value}的名字
String propertyName = parameterMapping.getProperty();
// 判断additionalParameters是否有这个propertyName,这种情况暂时不清楚
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
// 如果入参为空
} else if (parameterObject == null) {
value = null;
// 如果有当前入参的类型处理器
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
// 如果没有当前入参的类型处理器,这种一般是传入实体对象或传入Map的情况
} else {
// 这个原理和前面说过的MetaClass差不多
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
// 如果未指定jdbcType,且入参为空,没有在setting中配置jdbcTypeForNull的话,默认为OTHER
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 利用类型处理器给ps设置参数
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
使用ParameterHandler设置参数的内容就不再多讲,接下来分析语句执行和结果集映射的代码。
语句执行和结果集映射
进入到PreparedStatementHandler.query(Statement, ResultHandler)方法。语句执行就是普通的 JDBC,没必要多讲,重点看看如何使用ResultSetHandler完成结果集的映射。
protected final ResultSetHandler resultSetHandler;
@Override
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 直接执行
ps.execute();
// 映射结果集
return resultSetHandler.handleResultSets(ps);
}
为了满足多种需求,Mybatis 在处理结果集映射的逻辑非常复杂,这里先简单说下。
一般我们的 resultMap 是这样配置的:
然而,Mybatis 竟然也支持多 resultSet 映射的情况,这里拿到的第二个结果集将使用resultSet="authors"的resultMap 进行映射,并将得到的Author设置进Blog的属性。
还有一种更加奇葩的,多 resultSet、多 resultMap,如下。这种我暂时也不清楚怎么用。
接下来只考虑第一种情况。另外两种感兴趣的自己研究吧。
进入到DefaultResultSetHandler.handleResultSets(Statement)方法。
@Override
public List进入DefaultResultSetHandler.handleResultSet(ResultSetWrapper, ResultMap, List。这里的入参 parentMapping 一般为空,除非在语句中设置了多个 resultSet;
属性 resultHandler 一般为空,除非在 Mapper 方法的入参中传入,这个对象可以由用户自己实现,通过它我们可以对结果进行操作。在实际项目中,我们往往是拿到实体对象后才到 Web 层完成 VO 对象的转换,通过ResultHandler ,我们在 DAO 层就能完成 VO 对象的转换,相比传统方式,这里可以减少一次集合遍历,而且,因为可以直接传入ResultHandler ,而不是具体实现,所以转换过程不会渗透到 DAO层。注意,采用这种方式时,Mapper 的返回类型必须为 void。
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List进入到DefaultResultSetHandler.handleRowValues(ResultSetWrapper, ResultMap, ResultHandler, RowBounds, ResultMapping)。这里会根据是否包含嵌套结果映射来判断调用哪个方法,如果是嵌套结果映射,需要判断是否允许分页,以及是否允许使用自定义ResultHandler。
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
// 如果resultMap存在嵌套结果映射
if (resultMap.hasNestedResultMaps()) {
// 如果设置了safeRowBoundsEnabled=true,需校验在嵌套语句中使用分页时抛出异常
ensureNoRowBounds();
// 如果设置了safeResultHandlerEnabled=false,需校验在嵌套语句中使用自定义结果处理器时抛出异常
checkResultHandler();
// 映射结果集
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
// 如果resultMap不存在嵌套结果映射
} else {
// 映射结果集
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
这里我就不搞那么复杂了,就只看非嵌套结果的情况。进入DefaultResultSetHandler.handleRowValuesForSimpleResultMap(ResultSetWrapper, ResultMap, ResultHandler, RowBounds, ResultMapping)。 在这个方法中可以看到,使用RowBounds进行分页时,Mybatis 会查出所有数据到内存中,然后再分页,所以,不建议单独使用。
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
// 创建DefaultResultContext对象,这个用来做标志判断使用,还可以作为ResultHandler处理结果的入参
DefaultResultContext进入DefaultResultSetHandler.getRowValue(ResultSetWrapper, ResultMap, String)方法。这个方法将创建对象,并完成结果集的映射。点到为止,有空再做补充了。
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建实体对象,这里会完成构造方法中参数的映射,以及完成懒加载的代理
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
// MetaObject可以方便完成实体对象的获取和设置属性
final MetaObject metaObject = configuration.newMetaObject(rowValue);
// foundValues用于标识当前对象是否还有未映射完的属性
boolean foundValues = this.useConstructorMappings;
// 映射列名和属性名一致的属性,如果设置了驼峰规则,那么这部分也会映射
if (shouldApplyAutomaticMappings(resultMap, false)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 映射property的RsultMapping
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
// 返回映射好的对象
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
以上,基本讲完 Mapper 的获取及方法执行相关源码的分析。
通过分析 Mybatis 的源码,希望读者能够更了解 Mybatis,从而在实际工作和学习中更好地使用,以及避免“被坑”。针对结果缓存、参数设置以及其他细节问题,本文没有继续展开,后续有空再补充吧。
参考资料
Mybatis官方中文文档
相关源码请移步:mybatis-demo
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/12761376.html