《Java并发编程之美》阅读笔记(四)Java并发包中的原子操作类原理解析
JUC包提供了一系列的原子操作类,这些类都是非阻塞算法CAS实现的。相比使用锁实现原子操作这在性能上有很大提高。这一章以AtomicLong类和JDK8中新增的LongAdder类、LongAccumulater类进行实现原理的解析。
——————————————————————————————————————————————————————
JUC包下提供了AtomicLong,AtomicInteger、AtomicBoolean等原子操作类,它们的原理类似。下边以AtomicLong为例进行讲解。AtomicLong类是原子性递增或递减类,其内使用Unsafe来实现。
看以下代码:
public class AtomicLong extends Number implements java.io.Serializable {
private static final long serialVersionUID = 1927816293512124184L;
//(1)获取Unsafe 实例
private static final Unsafe unsafe = Unsafe.getUnsafe () ;
//(2)存放变量value的偏移量
private static final Long valueOffset;
//(3)判断JVM是否支持Long类型无锁CAS
static final boolean VM_SUPPORT_LONG_CAS = VMSupportCS8();
private static native boolean VMSupportCS8();
static{
try{
//(4)获取value的偏移量
valueOffset = unsafe.objectFieldOffset(AtomicLong.class.getDeclaredField("value"));
}catch(Exception e){
throw e;
}
}
//(5)实际变量值
private volatile Long value;
//(6)初始化变量值
public AtomicLong(Long initialValue){
value = initialValue;
}
……… …………
}(1)获得Unsafe实例,因为AtomicLong类本身在jr包下,是被BootStarp类加载器加载的,所以可以使用Unsafe.getUnsafe()直接获取实例.
(5)实际变量值使用volatile修饰,是为了保证多线程下的内存可见性。
(2)(4)获得value值在AtomicLong类下的偏移量。
下边看AtomicLong中的主要函数:
1、递增和递减代码
//调用unsafe方法,原子性设置原始值+1,返回原始值
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
//调用unsafe方法,原子性设置原始值-1,返回原始值
public final long getAndDecrement() {
return unsafe.getAndAddLong(this, valueOffset, -1L);
}
//调用unsafe方法,原子性设置原始值+1,返回递增后的值
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
//调用unsafe方法,原子性设置原始值-1,返回递减后的值
public final long decrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, -1L) - 1L;
}
以上代码的内部都是利用unsafe的原子性函数getAndAddLong方法实现的,第一个参数是AtomicLong实例的引用,第二个参数是原始值的偏移量,第三个参数是要增加或减少的值。
其中JDK8 中 unsafe.getAndAddLong方法的代码如下:

2.boolean compareAndSet(long except,long update)

其内部还是调用了unsafe中的compareAndSwapLong()方法。如果value值与expect值相等,则用update值更新value值,并返回true;否则返回false。
举例:开启两个线程使用atomicLong类统计两个数组中共有多少个数字0。
package com.learnThread.demo.part3;
import java.util.concurrent.atomic.AtomicLong;
/**
* @Author: tongys
* @Date: 2020/1/7
*/
public class TestAtomicLong {
public static void main(String[] args) throws InterruptedException {
int[] arr1= new int[]{1,2,0,5,3,0,5,0,4,8,9,0};//4
int[] arr2 = new int[]{2,5,0,3,0,0,6,0,0,0,8};//6
AtomicLong atomicLong = new AtomicLong();
Thread threadOne = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < arr1.length; i++) {
if (arr1[i] == 0){
atomicLong.incrementAndGet();
}
}
}
});
Thread threadTwo = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < arr2.length; i++) {
if (arr2[i] == 0){
atomicLong.incrementAndGet();
}
}
}
});
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
System.out.println("两个数组中共有"+atomicLong.get()+"个0");
}
}
一般我们在启动两个线程进行统计,并针对同一个变量进行递增操作时需要加锁来保证递增操作的原子性。但是利用CAS阻塞算法,atomicLong类可以不加锁就保证原子性,这相比于锁大大提高了性能。但是在高并发情况下atomicLong仍然存在性能问题,JDK8提供了一个在高并发下性能更好的LongAdder类。
4.2 JDK8提供的LongAdder类
4.2.1 LongAdder的简单介绍
前面学习了AtomicLong类,它采用CAS非阻塞算法实现了变量的原子操作,相对于使用阻塞算法的加锁操作,AtomicLong类的性能已经很好了。但是在大量线程并发执行的情况下,AtomicLong的执行效率仍然不够理想,因为多个线程同时竞争修改同一个原子变量,只有一个线程能够修改成功,其他线程就要重新获取原子变量和竞争修改,大量线程的竞争失败会造成大量自旋尝试CAS的操作,而白白浪费CPU资源。

AtomicLong类的在多线程下的性能问题是由于线程有多个,而原子变量只有一个导致的。那么LongAdder类的实现思路就是把一个变量分解成多个变量,多个线程对应多个变量。
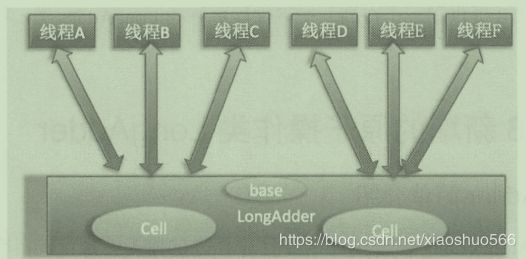
如上图,LongAdder类里维护多个Cell变量,每个Cell里边有一个初始值为0的long型变量。这样在相同并发量的情况下,争夺同一个变量的线程数会变小。并且如果线程竞争一个cell失败后会尝试去竞争其他cell,而不是永远自旋尝试同一个cell进行CAS操作,这增加了竞争成功的可能性。最后,在获取并返回LongAdder的当前值时,返回的是base和所有cell求和的结果。
LongAdder维护了一个延迟初始化的原子性更新数组(默认cell数组是null)和一个基值变量base。由于Cell数组占用的内存空间较大,所以在用到的时候再创建,也就是惰性加载。
当一开始判断cell数组为空并且线程数较少的情况下,所有线程的累加操作都是针对base进行的。保持cell数组的大小为2的N次方,所以第一次初始化时cell数组的大小为2,数组里的变量实体时cell类型,为了避免伪共享问题,再cell类上使用@sun.misc.Conteded注解防止多个原子性数组元素进入同一缓存行,这在性能上也是一个提升。
4.2.2 LongAdder代码分析
上边说到针对AtomicLong只有一个原子性变量的问题,LongAdder采用维护多个cell变量的形式进行了改进,降低了多线程下竞争原子性变量的性能开销。
下边围绕以下问题,分析LongAdder的实现:(1)LongAdder的结构是怎样的?(2)当前线程应该访问Cell数组里的哪一个cell变量?(3)如何初始化cell数组?(4)cell数组的扩容方式?(5)线程访问分配的cell变量有冲突怎么解决?(6)如何保证线程操作被分配的cell变量的原子性?
首先看类图如下:

由图可知,LongAdder继承Striped64类,其内部维护三个变量。LongAdder的真实值是base与Cell数组里所有cell变量值的累加。base是基础值,默认为0。cellsBusy是个自旋锁,状态只有0和1,当创建cell元素,初始化或扩容cell数组时,使用CAS操作保证以上三个操作同一时间内只能被一个线程完成。
看Cell源码:
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);//比较value与cmp是否一致,是则将其更新为val
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value")); //获取value的偏移量
} catch (Exception e) {
throw new Error(e);
}
}
}可以看到Cell类内部很简单。首先为了保证内存可见性使用volatile修饰value,然后利用Unsafe类提供的方法保证了操作的原子性。
还可以注意到使用了@sun.misc.Contended注解修饰类,避免伪共享问题。
- long sum():返回当前值。返回的值是base与Cell数组中所有元素值的累加。这个值不能保证是准确的,因为在累加计算总值时,没有对Cell数组进行加锁操作,计算的同时Cell数组可能在扩容、数组内元素可能正在被修改。

- void reset():重置base和Cell数组内所有元素值为0。

- long sumThenReset():计算并返回当前值,然后重置base和Cell数组内所有元素值为0。注意,当一个线程调用该方法后,另一个线程再调用获得的返回值就是0了。

- long longValue():等价于sum()。
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) {
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
//比较元素个数与cpu个数
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
//是否有冲突
else if (!collide)
collide = true;
//(1)如果当前数组元素个数小于cpu数,并且发生冲突则扩容
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
//(2)初始化cell数组,初始大小为2
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}初始化发生在(2),扩容发生在(1).
初始化数组大小为2,此时两个元素都为null。
扩容会创建新数组大小=原数组的大小*2,然后将原数组内的元素复制进新数组。除了复制进来的元素之外,新数组内其他元素为null。
其中cellsBusy是一个标识,如果为0表示cells数组没有在被扩容或初始化。此时可以进行扩容或初始化。该标识的修改是CAS操作,同一时间只有一个线程能修改它。
如有兴趣,更多cell数组的相关内容请自行了解。
4.2.3 小结
学习了JDk 8中新增的LongAdder类,内部通过维护一个可保存多个cell元素的Cells数组分担了高并发下对同一个原子变量竞争的压力,让多个线程可以同时修改多个cell变量。另外,cell类使用@sun.misc.Contended修饰,避免多个cell元素被保存到同一个缓存行中,也就是避免了伪共享,提高执行效率。
4.3 LongAccumulator类
LongAdder是LongAccumulator类的一个特例。LongAccumulator比LongAdder功能更强大。
1、LongAccumulator可以为累加器提供非0的初始值,而LongAdder只能提供默认为0的初始值。
2、LongAccumulator可以指定自定义的计算规则(在参数中提供fn函数),比如可以不进行累加而进行相乘。LongAdder默认只能进行累加操作。
4.4 第四章总结
本章学习了并发包中的原子操作类,他们都是使用CAS非阻塞算法实现的,相比于利用锁实现原子操作性能更好。先学习了最简单的AtomicLong类,由于该类在高并发下存在性能问题,又介绍了高并发下性能更好的LongAdder类。最后说了一下LongAccumulator类,LongAdder是一个只能进行初始值为0累加操作的特例。