使用GPU 训练Tensorflow/Keras 的CNN模型
关键词:Kaggle 猫狗大赛,MX510 GPU, 联想潮7000, Win10, NVIDA显卡
之前写了一个猫狗识别的CNN模型,利用笔记本进行训练,每次都需要好久,基本每个epoch要5分钟左右,来来回回改改参数,每次都要等漫长的时间。于是在找怎么利用GPU进行训练。
1. 电脑的显卡是NVIDA MX510, 可以支持CUDA,要使用tensorflow-gpu版本,需要安装CUDA9.0,下载之后直接安装,可能有2个patch可以下载,但是patch 1装不上,patch 2 可以,不影响。
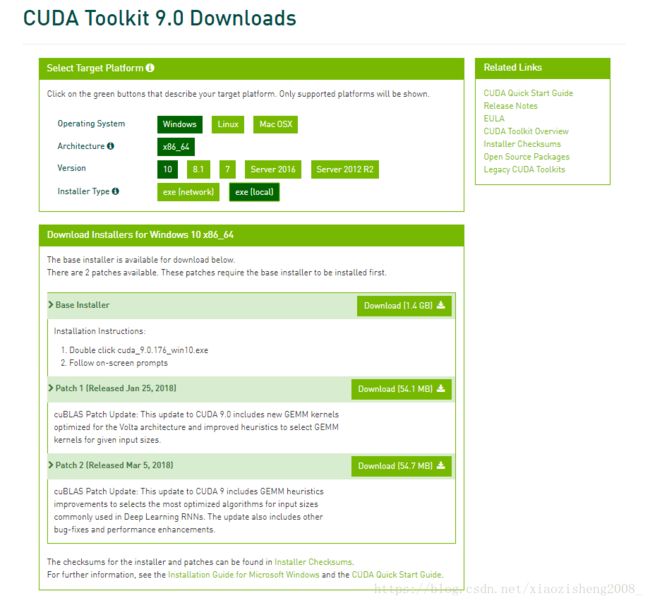
2. 下载cuDNN并安装,需要注册一下,下载后解压,将文件复制到CUDA的安装目录。
这是cuDNN解压后的文件
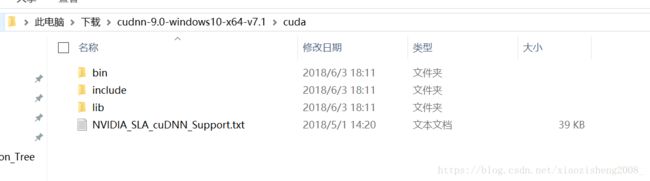
复制到这里
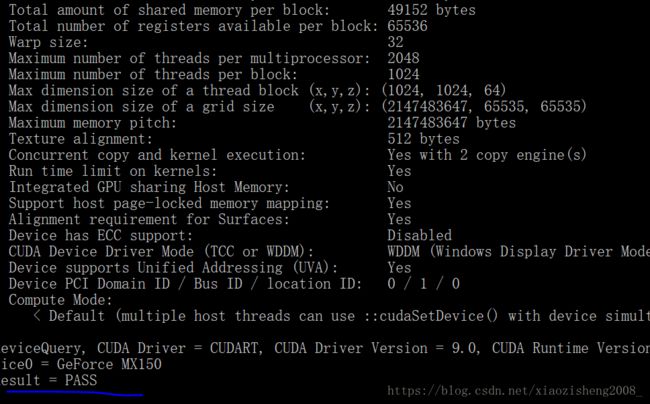
3. 可以测试一下CUDA是否安装成功
进入这个文件夹,运行这两个程序
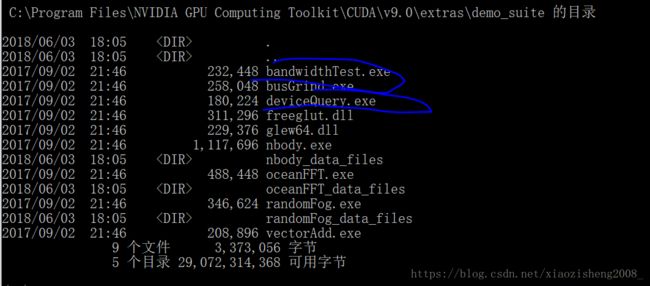
如果结果是pass, 则暗转成功。
4. 安装tensorflow-gpu, 直接使用pip install tensorflow-gpu
5. 安装keras,pip install keras
6. 在开始训练模型时,keras会自动检测是否有可用的GPU
使用如下的脚本来测试一下
import os
#os.environ['CUDA_VISIBLE_DEVICES'] = "0" # 使用第几个GPU, 0是第一个
import tensorflow as tf
import numpy as np
hello=tf.constant('hhh')
sess=tf.Session()
print (sess.run(hello))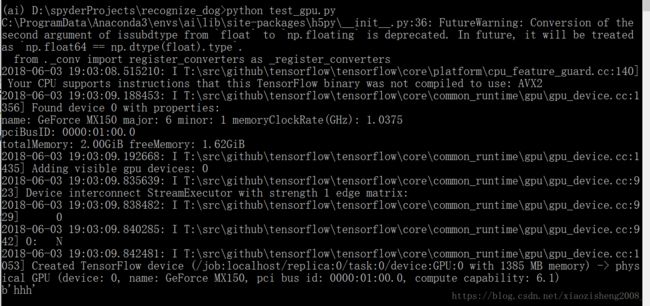
7. 利用kaggle的猫狗图片训练可以识别猫狗的CNN模型
# -*- coding: utf-8 -*-
"""
Created on Thu May 3 22:52:05 2018
@author: xiaozhe
"""
import os
from keras.models import Sequential
from keras.optimizers import Adam, SGD
from keras.layers import Dense, Activation, Flatten, Dropout
from keras.layers import Conv2D, MaxPooling2D
import logging
from resize_pic import generate_data, load_data
from sklearn.model_selection import train_test_split
import numpy as np
from keras.models import model_from_yaml, load_model, model_from_json
from matplotlib import pyplot as plt
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s-%(message)s')
path = os.path.join(os.getcwd(), 'train')
# test_data, test_labels = generate_data(path, 100)
test_data, test_labels = load_data('./train', (128, 128), 100)
test_data /= 255
images, labels = load_data(path, (128, 128), 10000)
images /= 255
x_train, x_test, y_train, y_test = train_test_split(
images, labels, test_size=0.2)
model = Sequential()
# the first convolution layer
model.add(Conv2D(filters=32,
kernel_size=(3, 3),
strides=(1, 1),
activation='relu',
input_shape=(128, 128, 3),
padding='same',
data_format="channels_last"))
#model.add(Conv2D(filters=32,
kernel_size=(3, 3),
strides=(1, 1),
activation='relu',
padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# the second convolution layer
model.add(Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
activation='relu',
padding='same'))
#model.add(Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
activation='relu',
padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# the third convolution layer
model.add(Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
activation='relu',
padding='same'))
#model.add(Conv2D(filters=128,
kernel_size=(3, 3),
strides=(1, 1),
activation='relu',
padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# the output layer
model.add(Flatten())
model.add(Dense(100, activation='relu'))
#model.add(Dense(128, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
sgd = Adam(lr=0.001)
model.compile(loss='binary_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=15, batch_size=100, verbose=1,
validation_data=(x_test, y_test))
predict_value = model.predict(test_data, verbose=1)
animals = np.array(['cat', 'dog'])
accurate = 0
for i in range(len(predict_value)):
predict_temp = 0
if predict_value[i, 0] > 0.5:
predict_temp = 1
if animals[predict_temp] == animals[test_labels[i, 0]]:
accurate += 1
# plt.imshow(test_data[i].astype(int))
print('predict: ', animals[predict_temp],
'actual: ', animals[test_labels[i, 0]], sep=' ')
print('accurate: ', accurate / predict_value.shape[0])
model_json = model.to_json()
with open('./models/model_3.json', 'w') as model_file:
model_file.write(model_json)
model.save_weights('./models/cat_dog_3.h5')
def load_cnnmodel():
with open('models/model_2.json', 'r') as model_js:
model_loaded = model_js.read()
model = model_from_json(model_loaded)
model.load_weights('models/cat_dog_2.h5')
sgd = Adam(lr=0.001)
model.compile(loss='binary_crossentropy',
optimizer=sgd, metrics=['accuracy'])resize_pic.py 中定义了一些图像的预处理函数
# -*- coding: utf-8 -*-
"""
Created on Wed May 2 23:03:57 2018
@author: xiaozhe
"""
import cv2
import os
import numpy as np
import _thread as thread
import logging
import random
from matplotlib import pyplot as plt
from keras.preprocessing import image
from keras.utils import np_utils
logging.basicConfig(level=logging.DEBUG, format='%(message)s')
def resize_pic(path, width, height):
# path = '.\\pics_dog'
# width = 300
# height = 200
for num, pic in enumerate(os.listdir(path), 1):
logging.debug(pic) if num % 100 == 0 else None
pic = os.path.join(path, pic)
img = cv2.imread(pic, cv2.IMREAD_UNCHANGED)
try:
img = cv2.resize(img, (width, height))
cv2.imwrite(pic, img)
except Exception as e:
logging.debug(e)
os.remove(pic)
def generate_data(path, samples_num):
logging.debug('Prepare data')
# path = '.\\pics_dog'
# samples_num = 1000
data = np.empty((samples_num, 200, 300, 3))
labels = np.empty((samples_num,))
path_list = os.listdir(path)
random.shuffle(path_list)
# ii, jj = 0, 0
for i, pic in enumerate(path_list):
if i >= samples_num:
break
pic = os.path.join(path, pic)
img = cv2.imread(pic, cv2.IMREAD_UNCHANGED)
if os.path.split(pic)[-1].split('.')[0] == 'dog':
labels[i] = 1
data[i] = img
# print(labels[i])
# ii += 1
elif os.path.split(pic)[-1].split('.')[0] == 'cat':
labels[i] = 0
data[i] = img
# print(labels[i])
# jj += 1
print(i, pic, labels[i])
labels = np_utils.to_categorical(labels, 2)
return data, labels
def load_data(path, image_size, sample_num):
# path = './data/train/'
files = os.listdir(path)
random.shuffle(files)
files = files[:sample_num]
images = []
labels = []
for i, f in enumerate(files, 1):
img_path = os.path.join(path, f)
img = image.load_img(img_path, target_size=image_size)
img_array = image.img_to_array(img)
images.append(img_array)
if 'cat' in f:
labels.append(0)
else:
labels.append(1)
logging.debug(str(i) + ' ' + f + ': ' +
str(labels[-1])) if i % 500 == 0 else None
data = np.array(images)
labels = np.array(labels).reshape(len(labels), 1)
#
# labels = np_utils.to_categorical(labels, 2)
return data, labels
if __name__ == '__main__':
path_dog = os.path.join(os.getcwd(), 'train')
path_cat = os.path.join(os.getcwd(), 'test1')
thread.start_new_thread(resize_pic, (path_cat, 128, 128,))
thread.start_new_thread(resize_pic, (path_dog, 128, 128,))
# resize_pic(path_cat, 224, 224)
# resize_pic(path_dog, 224, 224)
print('Finished')需要用到opencv库,直接使用pip install opencv-python 安装
训练这个模型,使用CPU的时候一个epoch需要5分钟左右,使用GPU只需要30多秒左右,速度提高了5倍。实际训练出来的模型大概有80%左右的精度。
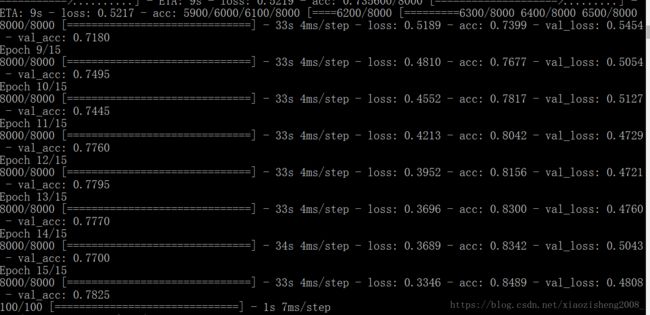
8. 基于上面的模型可以进一步调参数优化。主要掌握用GPU训练模型的方法。