广告推荐系统—CTR&LR模型评价
“计算广告学”中重要的一个子集——转化率预估(Conversion Modeling)广告行业内常见的商业模式有四种(图1):1) CPM(xost per mille),按每千次展现付费;2)CPC,按点击付费cost per click;3)CPA,按转化付费;4)CPS,按销售分成。容易理解,广告主最欢迎CPA模式,因为这种模式的广告投放效率最高,广告主不必为无效的展现和点击买单。然而,业内做CPA的广告网络(Ad Network)并不多,主要原因是转化数据难以收集。我们可以获取到电商类广告和应用类广告的转化数据。以数据为基础,再结合大规模机器学习算法,我们就可以实现广告转化率的实时预估(其实就是计算这个PV会进行有效操作的概率)—这对于CPA模式的广告匹配是很重要的,因为它是广告排序和计费的基础。广告平台会按期望收益对广告进行排序,而广告的期望收益等于广告主出价(Bid)和广告
点击率(Click-Through-Rate, CTR)预估点击率 (predict CTR, pCTR) 是指对某个广告将要在某个情形下展现前, 系统预估其可能的点击概率
一般需要大规模机器学习技术了,抽取相应的特征,进行转化率的估计,一般采用LR,这里首先介绍LR的众多评价标准,之后介绍其解法和特征项的选择问题。
评估模型效果的方法有很多,如:
1. AUC,从排序的角度评估模型预估效果;2. MAE(Mean Absolute Error)/MSE(Mean Squared Error),从准确率的角度评估模型预估效果;
3. Loss,从拟合训练数据的角度评估模型预估效果;
在工程中使用A/Btest,随机选取两部分线上同质流量,一部分用基准模型A预估转化率,一部分用实验模型B预估转化率。如果后者对在线业务指标(如转化率、点击率、千次展现收益等)有正向效果,我们就认为是好模型。
ROC
http://alexkong.net/2013/06/introduction-to-auc-and-roc/
对于分类器,或者说分类算法,评价指标主要有precision,recall,F-score
正如我们在这个ROC曲线的示例图中看到的那样,ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。
P(测试出来的正样本) N(测试出来的负样本)
Y TP(true positive) FP(false positive)
N FN(false negative) TN(true negative)
正确率 = 测试出来准确的正样本/所有的正样本 : TP/(TP+FP)
召回率 = 测试出来正确的正样本/测试出来的正本 TP/(FP+FN)
FPR = 将正样本测试成为了负样本/所有测试成为的负样本 FP/(FP+TN) 错误率
TPR = 测试正确的正样本/所有测试成为的正样本 TP/(TP+FN) 正样本测试的正确率
接下来我们考虑ROC曲线图中的四个点和一条线。第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。Wow,这是一个完美的分类器,它将所有的样本都正确分类。第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。类似的,第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
下面考虑ROC曲线图中的虚线y=x上的点。这条对角线上的点其实表示的是一个采用随机猜测策略的分类器的结果,例如(0.5,0.5),表示该分类器随机对于一半的样本猜测其为正样本,另外一半的样本为负样本。
这里需要一个思考的过程:
给一堆训练样本,那么得到一个分类结果,得到FPR,TPR,那么对应的是ROC上的一个点,roc曲线是如何获取的呢?
Wikipedia上对ROC曲线的定义:
In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied.
问题在于“as its discrimination threashold is varied”。如何理解这里的“discrimination threashold”呢?我们忽略了分类器的一个重要功能“概率输出”,即表示分类器认为某个样本具有多大的概率属于正样本(或负样本)。然后这里应该对分类器判断为正样本的概率的阈值进行一定的调整,获得多组坐标点数据,得到ROC曲线。
AUC值的计算
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。而且POC越靠近左上角越好,对应着AUC面积越大越好。
在了解了ROC曲线的构造过程后,编写代码实现并不是一件困难的事情。相比自己编写代码,有时候阅读其他人的代码收获更多,当然过程也更痛苦些。在此推荐scikit-learn中关于计算AUC的代码。
AUC意味着什么
那么AUC值的含义是什么呢?根据(Fawcett, 2006),AUC的值的含义是: > The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
为什么使用ROC曲线
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线5的对比:
在上图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。所以在样本出现不均衡时ROC无法解决。
其余数学方向的评价标准:
MAE(Mean Absolute Error)平均绝对差值
In statistics, the mean absolute error (MAE) is a quantity used to measure how close forecasts or predictions are to the eventual outcomes. The mean absolute error is given by
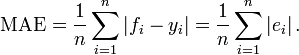
Note that alternative formulations may include relative frequencies as weight factors.
注意:MAE与 MAD(Mean Absolute Difference)等价。此外,MAE很容易跟absolute deviation(绝对偏差)混淆,它们的定义很类似,但使用的场景完全不同;绝对偏差针对的就是一组数据,而MAD针对的两组数据(预测值一组,真实值一组)。
MSE(Mean Square Error)均方误差
If 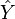 is a vector of n predictions, and
is a vector of n predictions, and 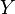 is the vector of the true values, then the (estimated) MSE of the predictor is:
is the vector of the true values, then the (estimated) MSE of the predictor is: 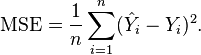
RMSE(Root Mean Square error)均方根误差
RMSE跟RMSD(Root-mean-square deviation)均方根偏差的定义等价,RMSE实际上就是MSE的平方根。
The RMSD of an estimator 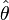 with respect to an estimated parameter
with respect to an estimated parameter 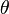 is defined as the square root of the mean square error:
is defined as the square root of the mean square error:

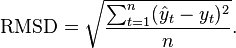
The normalized root-mean-square deviation or error (NRMSD or NRMSE) is the RMSD divided by the range of observed values of a variable being predicted,or:
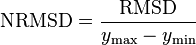
The value is often expressed as a percentage, where lower values indicate less residual variance.
coefficient of variation of the RMSD
The coefficient of variation of the RMSD, CV(RMSD), or more commonly CV(RMSE), is defined as the RMSD normalized to the mean of the observed values:
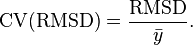
相关表和相关图可反映两个变量之间的相互关系及其相关方向,但无法确切地表明两个变量之间相关的程度。于是,著名统计学家卡尔·皮尔逊设计了统计指标——相关系数(Correlation coefficient)。相关系数是用以反映变量之间相关关系密切程度的统计指标。相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。
依据相关现象之间的不同特征,其统计指标的名称有所不同。如将反映两变量间线性相关关系的统计指标称为相关系数(相关系数的平方称为判定系数);将反映两变量间曲线相关关系的统计指标称为非线性相关系数、非线性判定系数;将反映多元线性相关关系的统计指标称为复相关系数、复判定系数等。
相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量。由于研究对象的不同,相关系数有如下几种定义方式:
6 Pearson's Correlation Coefficient(皮尔逊相关系数)
有的论文里叫COR(相关性)
相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:

公式二:

公式三:

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
注意当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
7 concordance correlation coefficient(一致性相关系数)
In statistics, the concordance correlation coefficient measures the agreement between two variables, e.g., to evaluate reproducibility or for inter-rater reliability.
Definition:
Lawrence Lin has the form of the concordance correlation coefficient 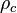 as
as
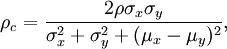
where 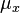 and
and  are the means for the two variables and
are the means for the two variables and  and
and 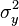 are the corresponding variances.
are the corresponding variances. 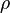 is the correlation coefficient between the two variables.
is the correlation coefficient between the two variables.
This follows from its definition[1] as

When the concordance correlation coefficient is computed on a N-length data set (i.e., two vectors of length N) the form is
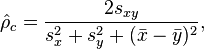
where the mean is computed as

and the variance

and the covariance

参考:
http://alexkong.net/2013/06/introduction-to-auc-and-roc/
http://blog.csdn.net/computerme/article/details/38871467
http://www.flickering.cn/ads/2014/06/%E8%BD%AC%E5%8C%96%E7%8E%87%E9%A2%84%E4%BC%B0%E2%80%94%E2%80%94%E5%BC%95%E8%A8%80/