机器学习_用SVD奇异值分解给数据降维
本想把PCA和SVD写在一起,可上篇PCA还没写清楚就已经4页word了。再把SVD和特征工程的内容加上,实在是太长了,一下说太多也记不住,于是重开一篇。
SVD用到的原理和 PCA非常相似,就不再此赘述了,如果对特征值、特征向量相关问题不清楚请参见前篇《机器学习_用PCA主成分分析给数据降维》
1. 原理
先回忆一下特征值分解:把向量x往特征向量方向上分解,然后每个方向上做伸缩,最后再把结果加起来即可。也可以理解为将向量x转到正交坐标系,在各个坐标轴的方向上缩放后,再转换回原来的坐标系。只有方阵才能做特征值分解,因此我们在PCA中不是直接对数据做分解,而是对参数的协方差矩阵做分解。
我们知道,任何矩阵都可以分解为三个矩阵的乘积 A=U * Sigma * VT,也就是奇异值分解.其中 U 和VT 均是酉阵(正交阵在复数域的推广),而 Sigma 为增广对角阵。从直观上讲,U 和 VT 可视为旋转操作,Sigma 可视为缩放操作。因此奇异值分解的含义就是说,若将矩阵看做一个变换,那么任何这样的变换可以看做是两个旋转和一个缩放变换的复合,这点和特征值分解基本一样。它也可以通过对Sigma的调整实现降维,通过U和VT在高维和低维间转换。相比特征值分解,奇异值分解可处理的不只是协方差矩阵(方阵),还可以直接处理数据。
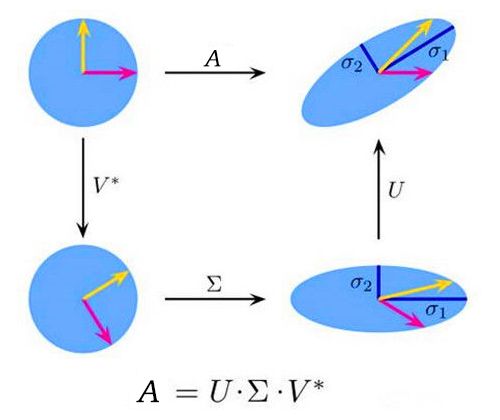
但SVD也有一些问题,比如数据多的时候,奇异值分解的计算量会很大,不像PCA做特征值分解时,矩阵的大小只和属性个数相关。
2. 例程
(1) 功能
对矩阵A做SVD分解;降维;原始数据转到低维度;降维后的数据恢复到原来维度,看数据损失。
(2) 代码
from numpy import linalg
import array
import numpy as np
A=np.mat([[1,2,3],[4,5,6]])
U,Sigma,VT=linalg.svd(A)
print("U",U)
print("Sigma",Sigma)
print("VT",VT)
Sigma[1]=0 # 降维
print("Sigma",Sigma)
S = np.zeros((2,3))
S[:2, :2] = np.diag(Sigma)
print("A conv:", np.dot(np.dot(A.T, U), S)) # 原始数据转到低维
print("A':", np.dot(np.dot(U, S), VT)) # 恢复原始维度(3) 运行结果
('U', matrix([[-0.3863177 , -0.92236578],
[-0.92236578, 0.3863177 ]]))
('Sigma', array([ 9.508032 , 0.77286964]))
('VT', matrix([[-0.42866713, -0.56630692, -0.7039467 ],
[ 0.80596391, 0.11238241, -0.58119908],
[ 0.40824829, -0.81649658, 0.40824829]]))
('Sigma', array([ 9.508032, 0. ]))
('A conv:', matrix([[-38.7526545 , 0. , 0. ],
[-51.19565893, 0. , 0. ],
[-63.63866337, 0. , 0. ]]))
("A':", matrix([[ 1.57454629, 2.08011388, 2.58568148],
[ 3.75936076, 4.96644562, 6.17353048]]))
(4) 分析
SVD分解矩阵A,A是一个2x3(mn,其中m是行数)的矩阵,把它分解成三个矩阵的乘积:A=U * Sigma * VT,其中U的大小是2x2(mm),VT为33(nn),Sigma为min(m,n),从矩阵乘法的角度上看,Sigma的大小应该是m*n,由于它是对角阵,为了简化,这里只取了对角线上元素。
Sigma奇异值为(9.508032,0.77286964),两值差异很大,说明转换后特征主要集中在一个维度上,于是降维,Sigma调整 为(9.508032,0)。将原始矩阵A转置后乘U和调整后的Sigma,实现了对A的降维。最后,将调整后的Sigma与U,VT相乘,映射回原始维度,变为矩阵A’,对比之下,A’与A的也差不太多。不过把两维降成一维还是挺夸张的,在此只为举例,大家领会精神吧。
这里比较重的是:观察Sigma,决定保留前几项?svd()函数对求出的奇异值和奇异向量按大小做了排序,其中值明显大的前N项,说明有N个“综合参数”最重要,因此,可以将数据降成N维。可降维度的多少,主要还是看数据的相关性,相关性越大,越适合降维。
3. 具体应用
(1) 图片压缩
把图片的像素放一个矩阵里,做SVD分解,只保留Sigma中值大的前N项。则存储时只需保存三个矩阵,假设原图大小100x100,N为5,则原图要10000点存储,而拆分后100x5+100x5+5=1005,图像大小变为原来的1/10。
(2) 数据降维
矩阵中记20人试吃这5种套餐的评价(5x20),先对整体数据做SVD分解,假设保留Sigma的前3项,把原矩阵转置并和U,Sigma相乘,矩阵就从520维变成了35维。再套用各种学习算法时,数据就大大缩减了(从高维到低维投影)。不过20个维度变为3个维度后,属性意义也不像之前那么直观了,我们可以使用VT矩阵把数据恢复到原来的维度。
技术文章定时推送
请关注公众号:算法学习分享