FileInputFormat类中split切分算法和host选择算法介绍
1、什么是split?
它是在逻辑上对输入数据进行的分片,并不会在磁盘上将其切分成分片进行存储。每个split都作为一个独立单位分配给一个task去处理(这也是为什么要把输入切分成split的原因)。hadoop中用org.apache.hadoop.mapred.FileSplit类来封装分片,其定义如下(省略了成员方法):
public class FileSplit extends org.apache.hadoop.mapreduce.InputSplit implements InputSplit {
private Path file; //split所在的文件(一个split一定只属于一个文件)
private long start; //split在文件中的起始位置
private long length; //split的长度
private String[] hosts; //split所在的主机名称
......
}
2、输入文件、split、block三者的关系。
我们可以用一张图来说明三者之间的关系,如下图:
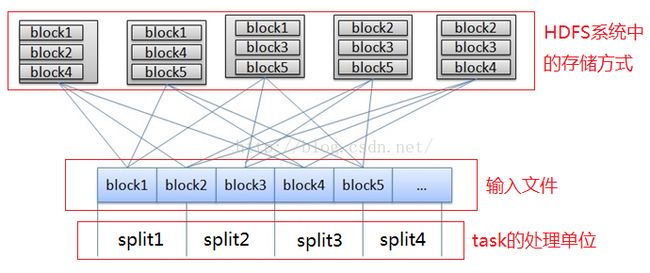
蓝色部分可以看做是一个输入文件,它被划分成多个block,如:block1,block2,block3,block4,block5,等等,存储在HDFS系统上。每个block在HDFS上有三个备份(算上自己,总共三份),每个备份分布在不同的节点(节点可能是主机、机柜、数据中心)上,图中有5个节点,防止因某个节点宕机而丢失数据。同时,一个文件被分成多个split,如:split1,split2,split3,split4等等。
(1)split是文件在逻辑上的划分,是程序中的一个独立处理单位,每一个split分配给一个task去处理。在实际的存储系统中并没有按split去存储。
(2)block是文件在物理上的划分,HDFS系统上就是按照block来存储的。一个block的多个备份存储在不同的节点上。
(3)一个文件可能被划分成多个split,但一个split只可能属于一个文件(稍后代码中将会讲解)。比如:图中的文件至少包含4个split。
(4)一个split可能包含多个block,但一个block不一定只属于一个split。比如:split1完全包含block1,部分包含block2,;block2一部分属于split1,一部分属于split2.
3、split切分算法
这里的文件切分算法指的是将文件切分成split,不是block。文件切分算法主要用来确定 InputSplit的个数 以及 每个InputSplit对应的数据段。对于每个文件,由以下三个属性值确定其对应的InputSplit的个数。
- goalSize :它是根据用户期望的InputSplit数目计算出来的,即totalSize/numSplits。其中,totalSize为输入文件(可能有多个)总大小;numSplits数用户设定的Map Task个数,默认情况下是1.
- minSize :InputSplit的最小值,由配置参数mapred.min.split.size(在/conf/mapred-site.xml文件中配置)确定,默认是1(字节).
- blockSize : 文件在HDFS中存储的block大小(在/conf/hdfs-site.xml文件中配置),不同文件可能不同,默认是64MB。
下面我们来看看源代码。源代码(Hadoop-1.0.0)在org.apache.hadoop.mapred.FileInputFormat的getSplits方法中。
//本文件代码在 org.apache.hadoop.mapred.FileInputFormat 中
private static final double SPLIT_SLOP = 1.1; // 切片系数
private long minSplitSize = 1;//最小split大小为1个字节
/**brief :将输入划分成多个split
*
* @param job : 作业,里面包含了作业运行时的一些信息,比如:输入文件信息
* @param numSplits : 用户给定的划分块数,即希望将文件划分成多少个split
*
* @return : 返回划分好的split数组
*/
public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException {
FileStatus[] files = listStatus(job);//从job中获取输入文件状态信息
job.setLong(NUM_INPUT_FILES, files.length);//将输入文件个数保存到job中
long totalSize = 0;//用于保存所有文件大小的总和
//统计所有文件大小的总和
for (FileStatus file: files) {
if (file.isDir()) {//非法文件
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();//累加
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);//按用户要求划分输入,确定每个split的目标大小goalSize
long minSize = Math.max(job.getLong("mapred.min.split.size", 1),minSplitSize);//minSplitSize是FileInputFormat类的成员,默认值是1(字节)。
//job.getLong("mapred.min.split.size", 1)是获取配置文件中设置的值,若没有设置,则取1.
/*************************** 开始划分split ************************/
ArrayList splits = new ArrayList(numSplits);//申请一个初始大小为numSplits的数组,来存放划分结果
NetworkTopology clusterMap = new NetworkTopology();//申请一个网络拓扑,用于划分过程中保存整个网络的拓扑结构
for (FileStatus file: files) {//对于每一个文件
Path path = file.getPath();//获取文件路径
FileSystem fs = path.getFileSystem(job);//获得hdfs文件系统中的路径信息
long length = file.getLen();//文件长度(字节数)
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);//获得此文件每个block所在位置(节点),可能存在于不同的节点上,所以是个数组
if ((length != 0) && isSplitable(fs, path)) {//文件长度不为0,且可分片
long blockSize = file.getBlockSize();//获得此文件在HDFS系统中的block大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);//计算分片的大小
long bytesRemaining = length;//文件剩余字节数
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {//文件剩余大小 大于 切片大小的1.1倍才会继续切片
String[] splitHosts = getSplitHosts(blkLocations, length-bytesRemaining, splitSize, clusterMap);//获得此split所在的主机位置
splits.add(new FileSplit(path, length-bytesRemaining, splitSize, splitHosts));//添加分片到结果集
//表示此文件(path指定)的此分片(length-bytesRemaining和splitSize指定)所在的hosts
bytesRemaining -= splitSize;//剩余大小
}
if (bytesRemaining != 0) {//将文件的最后一部分作为一个split
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkLocations.length-1].getHosts()));//添加split到结果集
}
}
else if (length != 0) {//文件不可分片,则将整个文件作为一个分片
String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap);//获得此文件所在的主机位置
splits.add(new FileSplit(path, 0, length, splitHosts));//添加到结果集
} else {//文件长度为0,则生成一个空分片
splits.add(new FileSplit(path, 0, length, new String[0]));
}
}
LOG.debug("Total # of splits: " + splits.size());//记录调试信息日志
return splits.toArray(new FileSplit[splits.size()]);
}
/**brief :计算split大小
*
* @param goalSize : 用户希望的split大小
* @param minSize : 配置文件中的split最小大小
* @param blockSize : HDFS文件系统中的block大小
*/
protected long computeSplitSize(long goalSize, long minSize, long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}(1)long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); 根据用户的numSplits个数来确定split的目标大小;
(2)方法computeSplitSize就是用来计算split的最终大小的。
(3)下面这段代码意思是将最后不足splitSize的部分也作为一个分片:
if (bytesRemaining != 0) {//将文件的最后一部分作为一个分片
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
(4) for (FileStatus file: files) {....},这个for循环,是对每一个文件进行分片,那么就可以保证一个split只属于一个文件,不会属于多个文件。
(5)NetworkTopology clusterMap = new NetworkTopology(); 不晓得为什么要定义这么一个对象。虽然作为参数传递给getSplitHosts方法,但在getSplits方法中,真没看出来它有什么作用。如果getSplitHosts方法要用的话,完全可以放在getSplitHosts中定义,为什么要放在getSplits方法中定义呢?
4、host选择算法
InputSplit的四个成员
为此,Hadoop将数据本地性按代价划分成三个等级,分别是:node locality(主机本地性)、rack locality(机柜本地性)、data locality(数据中心本地性)。前两个等级在Hadoop都已实现,数据中心本地性暂时还未实现。在任务调度时,会依次考虑3种节点本地性,优先让空闲资源处理本节点上的数据,如果节点上没有可处理的数据,则处理同一个机柜上的数据,最坏的情况是处理其他机柜上的数据(当然必须在同一数据中心)。
虽然InputSplit对应的bloc可能位于多个节点上,但考虑到任务调度的效率,一般不会将所有节点放入InputSplit的hosts列表中,而是选择包含该InputSplit数据量最大的前几个节点(Hadoop限制最多选择10个,多余的会过滤掉),以作为任务调度时判断任务是否具有本地性的主要凭证。一个简单有效的启发式算法(一种可行的算法,并不是最优的)是:首先按照rack包含的数据量对rack进行排序,然后在同一个rack内按node包含的数据量对node排序,最后取前N个node的host作为InputSplit的hosts列表,这里的N为block副本数。这样,当任务调度器调度Task时,只要将Task调度给位于hosts列表中的节点,就认为该Task满足本地性。
我们来看看源代码。源代码(Hadoop-1.0.0)在org.apache.hadoop.mapred.FileInputFormat的getSplitHosts方法中。
//本文件代码在 org.apache.hadoop.mapred.FileInputFormat 中
/**
* This function identifies(识别) and returns the hosts that contribute
* most(最大贡献) for a given split. For calculating the contribution(贡献度), rack
* locality(机柜本地性) is treated on par with(和...一起) host locality(主机本地性), so hosts from racks
* that contribute the most are preferred over hosts on racks that
* contribute less(因此,贡献大的机柜的主机要优先于贡献低的机柜的主机)
*
* @param blkLocations : block位置list
* @param offset : split在文件中的偏移量
* @param splitSize : split大小
* @param clusterMap : 网络拓扑,传递进来的是一个空拓扑,在本方法中会进行填充
*
* @return : 返回对这个split贡献最大的N个主机的集合
*/
protected String[] getSplitHosts(BlockLocation[] blkLocations, long offset, long splitSize, NetworkTopology clusterMap) throws IOException {
int startIndex = getBlockIndex(blkLocations, offset);//此偏移量的split所对应的第一个block的位置
long bytesInThisBlock = blkLocations[startIndex].getOffset() + blkLocations[startIndex].getLength() - offset; //split在第一个block中的数据量(字节个数)
if (bytesInThisBlock >= splitSize) {//如果split的字节全在此block中,则直接返回此block所对应的主机集合
return blkLocations[startIndex].getHosts();
}
long bytesInFirstBlock = bytesInThisBlock;//在第一个block中的字节数
int index = startIndex + 1;//从第二个block开始遍历
splitSize -= bytesInThisBlock;//除了在第一个block中的字节数,剩下还有多少
while (splitSize > 0) {//找到最后那个block
bytesInThisBlock = Math.min(splitSize, blkLocations[index++].getLength());//取 剩余split大小 和 当前block大小 的较小值
splitSize -= bytesInThisBlock;//去除当前block的字节数
}
long bytesInLastBlock = bytesInThisBlock;//在最后那个block中的字节数
int endIndex = index - 1;//最后那个block的索引号
Map hostsMap = new IdentityHashMap();//主机map,用于 主机 到 主机信息 的映射
Map racksMap = new IdentityHashMap();//机柜map,用于 机柜 到 机柜信息 的映射
String [] allTopos = new String[0];//用于存放split的所有block拓扑(拓扑:路径信息)
for (index = startIndex; index <= endIndex; index++) {//遍历split的所有block
/** 确定split在当前block的字节数 **/
if (index == startIndex) {//在首个block中的字节数
bytesInThisBlock = bytesInFirstBlock;
}
else if (index == endIndex) {//在尾个block中的字节数
bytesInThisBlock = bytesInLastBlock;
}
else {
bytesInThisBlock = blkLocations[index].getLength();//等于当前block的大小
}
allTopos = blkLocations[index].getTopologyPaths();//当前block在网络中的拓扑(因为一个block存在多个备份,可能存在不同的位置上,所以返回的是一个数组)
if (allTopos.length == 0) {//如果没有拓扑信息可以利用,则默认生成一个虚拟拓扑
allTopos = fakeRacks(blkLocations, index);
}
for (String topo: allTopos) {//遍历每一个拓扑,计算每个主机、每个机柜上的含有此split的字节数量
Node node, parentNode;//一个Node可能是一个数据中心、机架、机器,见Node.java文件。这里,node为主机,parentNode为机架
NodeInfo nodeInfo, parentNodeInfo;//节点对应的信息
node = clusterMap.getNode(topo); //按照拓扑(如/dog/orange/hostname:port,其中dog为数据中心,orange为机架,hostname为主机名,port为端口号)得到相应的节点
if (node == null) {//如果node为空,则按照默认拓扑生成一个节点
node = new NodeBase(topo);//创建默认拓扑
clusterMap.add(node);//加入网络拓扑中
}
nodeInfo = hostsMap.get(node);//第一次get时都是null,因为hostsMap为空
if (nodeInfo == null) {
nodeInfo = new NodeInfo(node);//生成一个默认的节点信息
hostsMap.put(node,nodeInfo);//加入到map中
parentNode = node.getParent();//获得此节点的父节点
parentNodeInfo = racksMap.get(parentNode);
if (parentNodeInfo == null) {
parentNodeInfo = new NodeInfo(parentNode);//生成默认节点信息
racksMap.put(parentNode,parentNodeInfo);//加入到map中
}
parentNodeInfo.addLeaf(nodeInfo);//node为parentNode的一个叶子
}
else {//不是第一次get时
nodeInfo = hostsMap.get(node);
parentNode = node.getParent();
parentNodeInfo = racksMap.get(parentNode);
}
nodeInfo.addValue(index, bytesInThisBlock);//同一个主机上相同block,addValue只会累加一次,见188行
parentNodeInfo.addValue(index, bytesInThisBlock);//同一个机架上相同block,addValue只会累加一次,见188行
} // for all topos
} // for all indices
return identifyHosts(allTopos.length, racksMap);
}
/**brief :找出此offset从哪个block开始的
*
* @param blkLocations : 文件的block数组,即文件的所有block都存在这个数组中
* @param offset : split在文件中的偏移量
*
* @return : split在blkLocations中的起始索引号。如果未找到,抛出异常。
*/
protected int getBlockIndex(BlockLocation[] blkLocations, long offset) {
for (int i = 0 ; i < blkLocations.length; i++) {
//offset大于等于当前block的起点,且小于当前block起点+当前block长度,那么此split就是从当前block开始的
if ((blkLocations[i].getOffset() <= offset) && (offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){
return i;
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset + " is outside of file (0.." + fileLength + ")");//抛出异常
}
/**brief : 生成虚拟拓扑,即在主机前面加上默认的机柜名称
*
* @param blkLocations : 存放文件所有block的数组
* @param index : 相应的block索引号
*
* @return :虚拟拓扑
*/
private String[] fakeRacks(BlockLocation[] blkLocations, int index) throws IOException {
String[] allHosts = blkLocations[index].getHosts();//获得此block所在的主机
String[] allTopos = new String[allHosts.length];
for (int i = 0; i < allHosts.length; i++) {
allTopos[i] = NetworkTopology.DEFAULT_RACK + "/" + allHosts[i]; //DEFAULT_RACK = "/default-rack";
}
return allTopos;
}
/**brief :此方法在org.apache.hadoop.mapred.FileInputFormat.NodeInfo类中,是FileInputFormat的一个内部类。方法的作用是累加block的字节数
*
* @param blockIndex : block的索引号
* @param value : split在此block的字节数
*
*/
void addValue(int blockIndex, long value) {
if (blockIds.add(blockIndex) == true) {//根据返回值判断是否要累加value。当blockIndex不存在的时候,会返回true;
this.value += value; //若已存在blockIndex,则返回false。也就是说,同一个拓扑中的相同block,只会累加一次。
}
}
/**brief : 机架优先、节点次之的顺序,按数据量(字节数)从大到小 对拓扑排序。找出要求数目的主机
*
* @param replicationFactor : 规定数目的主机数
* @param racksMap : 一个map,存放着 机柜节点 到 节点信息 的映射
*
* @return : 按贡献值(字节数)从多到少排序后,返回所要找的replicationFactor个主机名
*/
private String[] identifyHosts(int replicationFactor, Map racksMap) {
String [] retVal = new String[replicationFactor];//用于存放结果的数组
List rackList = new LinkedList(); //申请一个list,用于排序
rackList.addAll(racksMap.values());//将map的值放入list中,便于排序。 racksMap中存放的是机架上关于split的存储量
sortInDescendingOrder(rackList);//对机架排序,按照它们对split的字节数从多到少排序
boolean done = false;//标识变量,标识整个过程是否结束
int index = 0;//retVal数组的索引号
for (NodeInfo ni: rackList) {
Set hostSet = ni.getLeaves();//机架的叶子,其实就是主机,即获得此机架上的所有主机(存储着split的主机)
List hostList = new LinkedList();//用于排序
hostList.addAll(hostSet);//将所有主机添加到list中,便于排序
sortInDescendingOrder(hostList);//对本机架上的主机排序,按照它们的字节数从多到少排序
for (NodeInfo host: hostList) {
retVal[index++] = host.node.getName().split(":")[0];//从主机名中分离主机名,去除端口
if (index == replicationFactor) {//已找到足够多的主机
done = true;//标识任务完成
break;
}
}
if (done == true) {
break;
}
}
return retVal;
}
/**brief : 用于降序排序
*
* @param mylist : 需要排序的list
*/
private void sortInDescendingOrder(List mylist) {//降序排序
Collections.sort(mylist, new Comparator () {
public int compare(NodeInfo obj1, NodeInfo obj2) {
if (obj1 == null || obj2 == null)
return -1;
if (obj1.getValue() == obj2.getValue()) {
return 0;
}
else {
return ((obj1.getValue() < obj2.getValue()) ? 1 : -1);
}
}
}
);
}代码中注释已经很详细了,下面简单说明几点:
(1)getBlockIndex(BlockLocation[] blkLocations, long offset)方法,这是获取split所在block的索引号。比如说:在第2节的图中,blkLocations={block1, block2, block3, block4, block5, ...},split2从block2的中间部位开始,所以返回的索引为1,即block2在blkLocations中的下标。
(2)hostsMap用来记录主机的一些信息,比如包含split的字节数;racksMap用来记录机柜的一些信息。在遍历完相应的block之后,hostsMap记录下了包含split数据的主机信息,racksMap记录下了包含split数据的机柜信息,那么这些信息(主要是包含split的字节数)就可以用于之后的排序。
(3)org.apache.hadoop.mapred.FileInputFormat.NodeInfo类(是个内部类)的addValue(...)方法,保证了同一个拓扑中的相同block,只会累加一次包含split的字节数。拓扑可以看做是一个绝对路径,比如:/dog/orange/hostname:port,其中dog为数据中心,orange为机架,hostname为主机名,port为端口号。 对于文件的一个block,可能多个主机上都存储着,因为不同的主机就是不同的拓扑,所以不同主机上的相同block都会参与排序,以选出距离本地最近的一个主机。
(4)identifyHosts(...)方法中,首先按机柜上的字节数(split在此机柜上的数据量)从多到少排序,然后在同一机柜的多个主机上按字节数(split在此主机上的数据量)从多到少排序,依次选出要求个数的主机。标识符done的作用是一旦找到要求个数的主机,立即退出循环。