logistic的应用
当通过一系列连续型数据或类别性预测变量来预测二值型结果变量时,Logistic是一个非常常用的工具。
模型假设Y服从二项分布,线性模型的拟合形式为

其中, π 为给定一系列X值时Y=1的概率,( π /1- π )为Y=1时的优势比,log( π /1- π )为对数优势比。
我们以AER包中 的数据框为例,通过研究婚外情的数据来阐述Logistic回归过程。本例基于R语言实现,请确保已经下载软件及AER 安装包。
install.packages("AER")
library(AER)
###数据背景
婚外情数据即著名的“Fair’s Affairs",取自1969年《今日心理》所做的一个非常有代表性的调查,该数据从601个参与者身上搜集了9个变量,包括一年来婚外私通频率,参与者性别,年龄,婚龄,是否有小孩,宗教信仰程度(5分制,1分表示反对,5分表示非常信仰
),学历,职业(逆向编号的戈登七种分类),对婚姻的自我评分(5分制,1分表示非常不幸福,5表示非常幸福)
###数据预处理
data(Affairs)
summary(Affairs)
attach(Affairs)#绑定数据集
table(affairs)
affairs
0 1 2 3 7 12
451 34 17 19 42 38
上面给出了婚姻轻率举动的次数,但是我们更感兴趣的是二值型结果(有过婚外情的和没有过的)所以我们需要将affairs转换为二值型因子ynaffair
Affairs$ynaffair[affairs>0]<-1#次数大于0的设为1
Affairs$ynaffair[affairs==0]<-0#次数为0的设为0
Affairs$ynaffair<-factor(Affairs$ynaffair,levels = c(0,1),labels=c("NO","Yes"))#次数为0的设为NO
table(Affairs$ynaffair)
NO Yes
451 150
以上就是我们想要的结果
###建立模型
m1<-glm(ynaffair~.,data=Affairs,family=binomial())
#因变量为ynaffair,自变量为其余变量
Warning messages:
1: glm.fit: algorithm did not converge
2: glm.fit: fitted probabilities numerically 0 or 1 occurred
这里出现了两个错误,让我们看一下这两个错误的意思:
第一个是说算法没有拟合;第二个是说拟合机率算出来是数值零或一
具体解决方法参考下方链接,给出了具体的分析过程
第一个问题的解决方法只需要增加迭代次数即可(默认为25)
第二个问题说明我们选取的变量是完全可分的,不适合用logistic进行拟合,但为了解释一下大致步骤,我们继续往下进行。
下面我们修改模型
m2<-glm(ynaffair~age+yearsmarried+religiousness+rating,data=Affairs,family = binomial())
summary(m2)
Call:
glm(formula = ynaffair ~ age + yearsmarried + religiousness +
rating, family = binomial(), data = Affairs)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.6278 -0.7550 -0.5701 -0.2624 2.3998
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.93083 0.61032 3.164 0.001558 **
age -0.03527 0.01736 -2.032 0.042127 *
yearsmarried 0.10062 0.02921 3.445 0.000571 ***
religiousness -0.32902 0.08945 -3.678 0.000235 ***
rating -0.46136 0.08884 -5.193 2.06e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 675.38 on 600 degrees of freedom
Residual deviance: 615.36 on 596 degrees of freedom
AIC: 625.36
Number of Fisher Scoring iterations: 4
可以看出年龄,婚龄,宗教信仰程度,对婚姻的自我评分对方程的贡献都是显著的(原假设:参数为0;P<0.05,拒绝原假设)
###模型检验
新模型的每个回归系数都非常显著,由于两模型嵌套(m2是m1的一个子集,可以使用anova函数对他们进行比较,对于广义线性模型可以用卡方检验)
anova(m2,m1,test="Chisq")
###解释模型参数
〉coef(m2)
(Intercept) age yearsmarried religiousness
1.93083017 -0.03527112 0.10062274 -0.32902386
rating
-0.46136144
在Logistic中,相应变量是Y=1的对数优势比(log)。回归系数的含义是当其他预测变量不变时,一单位预测变量的变化可引起的响应变量对数优势比的变化。
由于对数优势比的可解释性太差,可以对结果进行指数化
〉exp(coef(m2))
(Intercept) age yearsmarried religiousness
6.8952321 0.9653437 1.1058594 0.7196258
rating
0.6304248
可看到婚龄增加一年,婚外情的优势比将乘以1.106(保持其他变量不变),相反,年龄增加一岁,婚外情的优势比则乘以0.965.因此,随着婚龄的增加和年龄,宗教信仰与婚姻评分的降低,婚外情优势比将上升,因为预测变量不能等于0,截距项在这里没有特定意义。
下面给出了回归系数的置信区间
〉exp(confint(m2))
2.5 % 97.5 %
(Intercept) 2.1255764 23.3506030
age 0.9323342 0.9981470
yearsmarried 1.0448584 1.1718250
religiousness 0.6026782 0.8562807
rating 0.5286586 0.7493370
最后预测变量一单位变化可能并不是我们最想关注的,对于二值型Logistic回归,某预测变量n单位的变化引起较高值上优势比的变化为exp(exp(β_j)n,它反映的信息更加重要。比如保持其他预测变量不变,婚龄增加一年,婚外情的优势比将乘以1.106,而如果婚龄增加10年,优势比将乘以1.10610
-------------------------------------------------------------------------分割线--------------------------------
###预测泰坦尼克号生存人数(kaggle入门级)
###数据描述
泰坦尼克号是一次航船史上的大灾难,因为同名电影而广为人知。而在此次灾难中有多少人死亡,导致死亡的相关因素是什么?我们经过分析探寻结论.
由于灾难发生后场面及其混乱,加之文件管理不当、后世的种种说法又鱼龙混杂的因素,导致泰坦尼克号乘客与死难者的统计数据始终存疑。目前普遍认为罹难者人数可能在1490-1635人之间,其中可信度最高的数据是由英国贸易委员公布的:在灾难发生时,泰坦尼克号共搭载2224人,其中710人生还,1514人不幸罹难。这里我们选用kaggle上的数据,其中共计12个变量,分别是PassengerId,Survived ,Pclass ,Name ,Sex ,Age, SibSp, Parch ,Ticket ,Fare ,Cabin, Embarked。共计1309个观测,将其分为训练集和测试集,
训练集(train.csv)包含891个观测,测试集(test.csv)包含418个观测。
训练集被用来建立模型。对于训练集,提供了每个乘客的结果(也称为“地面实况”)。模型将基于乘客的性别和阶级等“特征”。
使用测试集来检验模型表现如何。对于测试组,不提供每个乘客的基本事实,使用训练的模型来预测他们是否在泰坦尼克号的沉没中幸免于难。
变量解释
Survived 生存 0 =否,1 =是
pclass 票类 1 = 1,2 = 2,3 = 3
sex 性别
age 年龄在几年
sibsp #泰坦尼克号上的兄弟姐妹/配偶
Parch #泰坦尼克号上的父母/孩子
Ticket 票号
Fare 乘客票价
Cabin 客舱号码
Embarked 开始登船港口 C =瑟堡,Q =皇后镇,S =南安普敦
可变注释
pclass:社会经济地位代表(SES)
1 =上
2 =中
3 =下
年龄:如果年龄小于1,年龄是分数。如果估计年龄,是xx.5
sibsp的形式:数据集定义这样的家庭关系…
兄弟姐妹=兄弟,姐妹,同父异母的弟弟,义妹
配偶=丈夫,妻子(包二奶和未婚夫被忽略)
Parch:将数据集定义这样的家庭关系…
父=母亲,父亲
儿童=女儿,儿子,继女,继子
有些孩子只带着保姆旅行,所以parch = 0。
###数据预处理
data.raw <- read.csv('train.csv',header=T,na.strings=c(""))#读取数据集
sapply(data.raw,function(x) sum(is.na(x)))#查看缺失值个数
PassengerId Survived Pclass Name Sex
0 0 0 0 0
Age SibSp Parch Ticket Fare
177 0 0 0 0
Cabin Embarked
687 2
我们可以看出Age一栏又能177个缺失值,Cabin一栏有687个缺失值
这里我们用图表将缺失值画出来,可以更加直观的看出来
install.packages("Amelia")
library(Amelia)
missmap(training.data.raw, main = "Missing values vs observed")
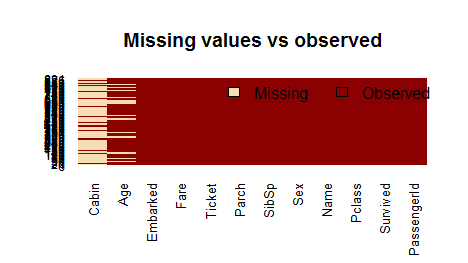
对于缺失值怎么办?我们先判断与因变量无关的变量,也就是可以凭主观判断出来的,比如Name,Parch,Cabin,将其舍弃
data <- subset(data.raw,select=c(2,3,5,6,7,8,10,12))
head(data)
sapply(data,function(x) sum(is.na(x)))
Survived Pclass Sex Age SibSp Parch Fare
0 0 0 0 0 0 0
Embarked
2
我们看到Embarked存在两个缺失值,一般对于数值型数据的缺失我们可以取其均值补充或者众数中位数,对于字符型数据取其众数,当然最快的方法是直接删除缺失数据所在的那一行,这只实用与缺失值较少的情况下
data$Age[is.na(data$Age)] <- mean(data$Age,na.rm=T)
data <- data[!is.na(data$Embarked),]#去掉缺失值
sapply(data,function(x) sum(is.na(x)))
dim(data)
查看一下确实删除了2行观测,现在我们有8个变量,889个观测
注意:建立模型是面向数据框进行操作,如果不是数据况,一定要先转换数据结构
下面我们基于训练集进行划分,同样分成两个组,以便于对模型进行检验。其中训练组800个观测,测试组89个观测
train <-data[c(1:800),]
test <- data[c(801:889),]
model <- glm(Survived~Pclass+Sex+Age+SibSp+Parch+Fare+Embarked,
data=train,family=binomial())
summary(model)
Call:
glm(formula = Survived ~ Pclass + Sex + Age + SibSp + Parch +
Fare + Embarked, family = binomial(), data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.6064 -0.5954 -0.4254 0.6220 2.4165
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 5.137627 0.594998 8.635 < 2e-16 ***
Pclass -1.087156 0.151168 -7.192 6.40e-13 ***
Sexmale -2.756819 0.212026 -13.002 < 2e-16 ***
Age -0.037267 0.008195 -4.547 5.43e-06 ***
SibSp -0.292920 0.114642 -2.555 0.0106 *
Parch -0.116576 0.128127 -0.910 0.3629
Fare 0.001528 0.002353 0.649 0.5160
EmbarkedQ -0.002656 0.400882 -0.007 0.9947
EmbarkedS -0.318786 0.252960 -1.260 0.2076
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1065.39 on 799 degrees of freedom
Residual deviance: 709.39 on 791 degrees of freedom
AIC: 727.39
Number of Fisher Scoring iterations: 5
我们看到Pclass,Sex,Age,SibSp这几个变量所对应的P值小于0.05,即其参数显著不为0,由此修改模型
model2 <- glm(Survived~Pclass+Sex+Age+SibSp,
data=train,family=binomial())
summary(model2)
Call:
glm(formula = Survived ~ Pclass + Sex + Age + SibSp, family = binomial(),
data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.6595 -0.6125 -0.4247 0.6149 2.4302
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 5.05604 0.50130 10.086 < 2e-16 ***
Pclass -1.14391 0.12585 -9.089 < 2e-16 ***
Sexmale -2.75564 0.20471 -13.461 < 2e-16 ***
Age -0.03725 0.00812 -4.588 4.48e-06 ***
SibSp -0.33075 0.10892 -3.037 0.00239 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1065.39 on 799 degrees of freedom
Residual deviance: 713.43 on 795 degrees of freedom
AIC: 723.43
Number of Fisher Scoring iterations: 5
这几个变量的参数显著不为0,可以认定我们修改的模型是正确的,下面我们用方差分析进一步验证
anova(model2,model, test="Chisq")
Analysis of Deviance Table
Model 1: Survived ~ Pclass + Sex + Age + SibSp
Model 2: Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 795 713.43
2 791 709.39 4 4.0446 0.4
我们可以看到其P值大于0.05,不拒绝原假设,即model2与model对预测变量的解释程度一样好。
###模型参数解释
现在,我们可以分析这个拟合的模型model2,对于那些比较重要的变量,其中sex的回归系数最低(绝对值最大),这说明sex与乘客的生存几率的关系是最强的。当其它变量都一样,这个负系数预测变量表明,男乘客生存的机率更低。逻辑模型的因变量是对数机率:ln(odds) = ln(p/(1-p)) = ax1 + bx2 + … + z*xn。male是一个优化变量,男性的生还机率下降2.76个对数机率,而年龄每增大一个单位,生存率则下降0.037个对数机率,等级上升一个单位,生存率下降1.14个对数单位。
接下来我们再检验样本上评估模型的预测能力
###评估模型的预测能力
head(test)
newdata<-subset(test,select=c(2,3,4,5,6,7,8))
m3<- predict(model,newdata,type='response')
#prdict(type="responce")#表示输出结果预测响应变量为1的概率
m3
m3<- ifelse(m3 > 0.5,1,0)
#如果响应量大于0.5,返回值为1否则返回0
Error <- mean(m3 != test$Survived)
#返回值(预测值)与真实值不一致的部分,即误差
print(paste('Accuracy',1-Error))#预测精度
[1] "Accuracy 0.842696629213483"
由上面可以看出model的预测精度为84.27%
newdata<-subset(test,select=c(2,3,4,5))
m4<- predict(model2,newdata,type='response')
m4<- ifelse(m4 > 0.5,1,0)#决策边界为0.5
misClasificError <- mean(m4 != test$Survived)
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.786516853932584"
可以看到model2的精度为78.65%,虽然我们的变量减少了,而且都显著,但是精度也随之降低了。
我们有没有什么修正的方法呢?
newdata<-subset(test,select=c(2,3,4,5))
m4<- predict(model2,newdata,type='response')
m4<- ifelse(m4 > 0.6,1,0)#决策边界为0.6
misClasificError <- mean(m4 != test$Survived)
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.820224719101124"
可以看到精度提升到了82.02%,这又是为什么呢?
首先我们要明白变动了什么,上面我们将决策边界由0.5变为了0.6,
R可以输出形如P(Y=1|X)的概率。如果我们的预测边界就是0.5。如果P(Y=1|X)>0.5,y=1或y=0.上面将0.5变动为0.6,表明只有当预测为1的概率大于0.6时,才能将预测值设为1,由此我们的精度也提高了。那么是不是决策边界越高越好?
newdata<-subset(test,select=c(2,3,4,5))
m4<- predict(model2,newdata,type='response')
m4<- ifelse(m4 > 0.7,1,0)#决策边界为0.7
misClasificError <- mean(m4 != test$Survived)
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.808988764044944"
可以看到在决策边界为0.7的情况下,预测精度反而下降为80.90%,可见并非是决策边界越高预测精度越高。当决策边界过高时,一些预测值也会被误判,所以最优决策边界并不一定是0.5。
一个一个找决策边界太麻烦了,有什么更好的办法吗?当然有,目前最被广泛应用的是K重交叉验证(k-fold CrossValidation)
###更精确的k重交叉验证
####交叉验证(CrossValidation)方法思想
以下简称交叉验证(Cross Validation)为CV.CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标.常见CV的方法如下:
1).Hold-Out Method
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性.
2).K-fold Cross Validation(记为K-CV)
将原始数据分成K组(一般是均分),将其中一个子集数据做为测试集,其余的K-1组子集数据作为训练集;将K个子集轮流作为测试集,重复上述过程,这样得到了K个分类器或模型,并利用测试集得到了K个分类器或模型的分类准确率。用K个分类准确率的平均值作为分类器或模型的性能指标.K一般大于等于2,实际操作时一般从3开始取,常常取10,只有在原始数据集合数据量小的时候才会尝试取2.K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性.
3).Leave-One-Out Cross Validation(记为LOO-CV)
如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为测试集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标.相比于前面的K-CV,LOO-CV有两个明显的优点:
①每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
②实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间.
其中,拟合不同的模型需要进行不同的交叉验证,也就需要根据自己的需要来编写相应函数,这里给出广义线性模型的交叉验证方法
install.packages("boot")
library(boot)
model <- glm(Survived~Pclass+Sex+Age+SibSp+Parch+Fare+Embarked,
data=data,family=binomial())
a<-cv.glm(data,model,K=10)#广义线性回归的10重交叉验证
a
$call
cv.glm(data = data, glmfit = model, K = 10)
$K
[1] 10
$delta
[1] 0.1433601 0.1431568
$delta
长度为2的一个矢量值。第一部分是交叉验证的预计误差,第二部分是调整的交叉验证估差,调整值是用于填补通过弃一法交叉验证引入的偏差。
可见由model的调整后的预计误差为14.32%
model2 <- glm(Survived~Pclass+Sex+Age+SibSp,
+ data=data,family=binomial())
a<-cv.glm(data,model2,K=10)
a
$call
cv.glm(data = data, glmfit = model2, K = 10)
$K
[1] 10
$delta
[1] 0.1429763 0.1428592
可见由model2交叉验证的调整后的预计误差为14.29%
作为最后一步,我们会做ROC曲线并计算AUC(曲线下的面积),它常用于预测二元分类器的模型表现。
####ROC AUC
ROC曲线是一种曲线,它可以通过设定各种极值来让正例律(TPR)来抵消反正例律(FPR),它就在ROC曲线之下。通常来说,一个预测能力强的模型应当能让ROC接近1(1是理想的)而不是0.5。
install.packages("ROCR")
library(ROCR)
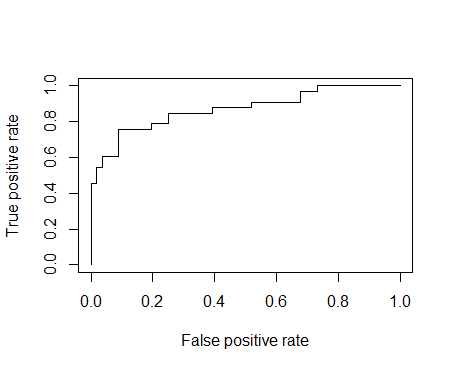
p <-predict(model,newdata=subset(test,select=c(2,3,4,5,6,7,8)), type="response")
pr <- prediction(p, test$Survived)
prf <- performance(pr, measure = "tpr", x.measure = "fpr")
plot(prf)
auc <- performance(pr, measure = "auc")
auc <- [email protected][[1]]
auc
[1] 0.870671
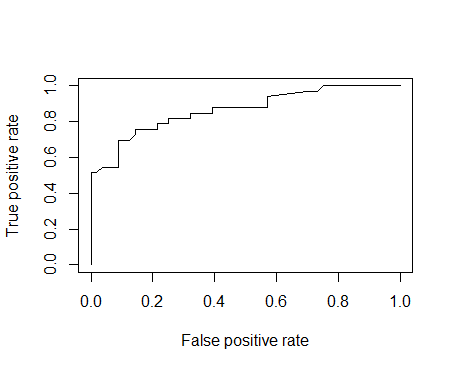
p <- predict(model2, newdata=subset(test,select=c(2,3,4,5)), type="response")
pr <- prediction(p, test$Survived)
prf <- performance(pr, measure = "tpr", x.measure = "fpr")
plot(prf)
auc <- performance(pr, measure = "auc")
auc <- [email protected][[1]]
auc
[1] 0.8652597
参考资料:
logistic回归报错问题
如何在R语言中使用Logistic回归模型
R语言逻辑回归、ROC曲线和十折交叉验证
《R语言实战》
扫码关注更多的分享内容,祝好呀~~