Java集合数据结构
集合类型
Set集合:集合元素是不能重复的。元素是没有顺序的。所以它不能基于位置访问元素。TreeSet和HashSet是它的实现类。
List集合: 集合元素是可以重复的。元素是有顺序的。所以它可以基于位置访问元素。ArrayList和LinkedList是它的实现类。
Map:它包含键值对。Map的键是不能重复的。Map不能保证存储的顺序。HashMap和TreeMap是它的实现类。
怎样来选择?
事实上,选择Set,List或者Map是依赖你的数据结构的。如果你将要存储的数据没有重复且不需要顺序,你可以选择用Set。如果你将要存储的数据需要保证顺序,你可以选择用List。如果你有一个键值对来关联两个不同的对象或者用一个标识符来标识对象,那么你可以选择Map。
举个例子:
颜色的集合最好放入Set中。
球队最好放在List中。因为球队的出场需要顺序。
Web Sessions的集合最好在Map上;唯一的session ID会更好的引用实际对象。
当我们选择用哪个集合的时候,我们主要关心的是集合的速度:
- 访问元素的速度
- 添加一个新元素的速度
- 移除一个元素的速度
- 迭代的速度
此外, 也有一致性的问题。一些实现会保证访问的速度,而一些实现将有个变化的速度。我们关心的这些速度依赖于集合的具体实现。
链表实现
具体的类:LinkedList, LinkedHashSet
内部原理:每个节点中都持有一个元素和下一个元素的指针。如下图:
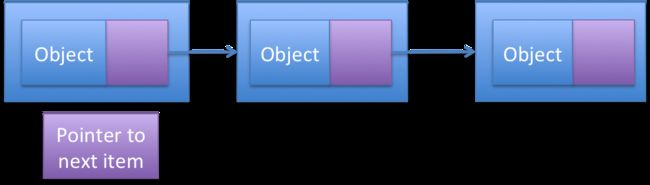
- 如果我们想加入一个元素到上图的第二个位置上,是很简单的。就像下图一样,它只须把原图中的第一个节点中的指针指向新加入的这个元素,把新加入的这个元素的指针指向原图中的第二个节点就可以了。这个速度是非常快的!不需要拷贝,移动和记录原集合中的元素。
- 移除元素也是同理的,只要把原图中第一个节点中的指针指向原图中第二个节点的元素就可以了。
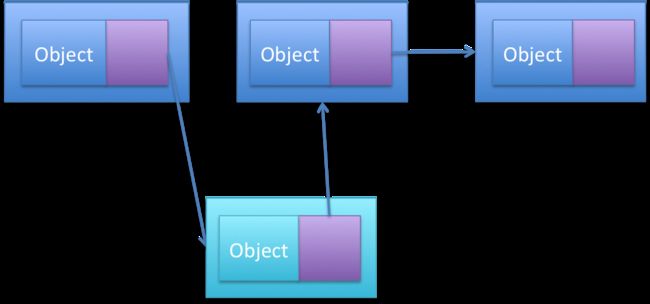
当我们想访问集合中的元素是很慢的。先看看LinkedList的源码:
/**
* 返回指定索引位置的元素
*/
Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} 当我们想获取指定位置的一个元素时,程序会先将集合大小size右移一位(也就是说,把size的大小会减少一半),然后判断索引位置是离第一个节点位置近还是最后一个节点位置近,然后开始遍历,得到指定的节点。
举个例子:如果集合中有50个元素,如果你想获取第20个元素,那么它会从集合中第一个元素开始遍历,直到获取到第20个元素为止;如果你想获取第40个元素,那么它会从集合中最后一个元素开始遍历,直到获取到第40个元素为止。
所以对于链表实现的集合来说,它访问元素的速度很慢。而且访问不同位置的元素,速度还不一致。还有一点我们要深深牢记的是:当我们做添加和移除操作时,都会调用到上面的node方法,从而遍历获取所要操作节点的前一个节点,因此,这会对速度有一定的影响。
因此,当你需要更快的添加/移除,而且并不怎么关心访问时间的时候,像LinkedList这样的链表集合是更合适的。如果你打算在你的集合中有很多的添加/移除元素操作,那么这是个不错的选择。
数组实现
具体的类:ArrayList
ArrayList是集合类中的唯一基于数组实现的。
看下图:在ArrayList中,当我们把一个新元素添加到第四个位置上时,它会把第四个位置(包括第四个位置)以后的每一个位置上的元素都向后挪一位,然后在把新加入的元素插入到第四个位置上。这是很慢的,而且这并不能保证时间,它依赖于有多少的元素需要拷贝。同理,移除一个元素就是把后面的元素全部向前挪一位。
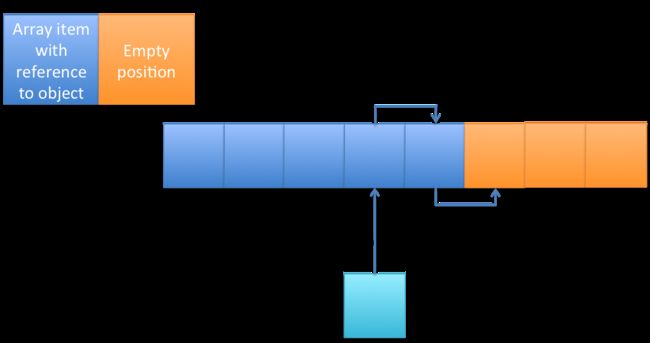
还有一种更糟糕的情况。当我们创建ArrayList对象的时候,它的数组长度是固定的(这个长度可以在构造函数中设置,如果不设置默认为10)。当我们操作集合的时候,如果它的容量超过这个固定长度的话,就不得不创建一个更大容量的数组,然后把当前集合中的所有元素拷贝到新创建的这个集合当中。这是非常非常慢的。
然而,ArrayList访问元素的速度是很快的。对于数组来说,它在内存空间中的位置是连续的,所以我们不需要遍历整个集合就可以准确的算出元素引用在内存中的位置。并且,耗费的时间也是一致的。
因此,如果你有一些并不怎么修改,而且需要快速访问的元素,那么ArrayList是一个很好的选择。
Hash实现
具体的类:HashSet, HashMap
HashSet是基于HashMap实现的,所以这里我就只解释HashMap了。
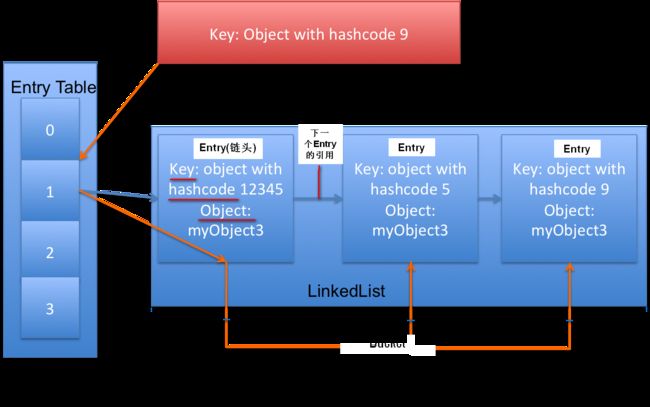
HashMap的工作原理:HashMap底层就是一个数组结构(叫做Entry Table),数组中的每一项又是一个链表(叫做Bucket)。当新建一个HashMap的时候,就会初始化一个数组。
public V put(K key, V value) {
......
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
......
addEntry(hash, key, value, i);
return null;
} 上面是HashMap中put方法的部分代码(JDK7)。当我们向HashMap中put元素的时候,先根据key重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),再通过这个下标访问到Bucket的链头并开始遍历整个Bucket(也就是整个链表),如果Bucket中已经存在新添加的key的值,则将原有的值设置成新添加的值,并返回旧值。否则,新加入的元素放在链头,最先加入的放在链尾。
总的来说,程序首先根据准备放入的元素的key(通过hash算法)决定该Entry在Entry Table中的存储位置。如果新加入的这个Entry 的key与原有Entry的Key通过equals比较返回 true,那么新添加 Entry的value将覆盖集合中原有Entry的value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部(也就是Bucket的链头)。
同理,从HashMap中get元素时,首先通过key计算出的Hash值来确定Entry在Entry Table中的存储位置,然后通过key的equals方法在对应位置的链表中找到需要的元素。
总结:HashMap 底层采用一个 Entry[] 数组来保存所有的Entry对象(里面包含hash值、key-value对、下一个Entry的指针),当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
HashMap的rehashing
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容。数组容量将会自动扩大两倍,在数组扩容时,所有原存在的Entry会重新计算索引值,并且Entry链的顺序也会发生颠倒(如果还在同一个链中的话),而该新添加的Entry的索引值也会重新计算,这是最消耗性能的,这个过程就是rehashing。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组小loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。