Deep Image Retrieval: Learning global representations for image search. In ECCV, 2016.
Deep Image Retrieval: Learning global representations for image search. In ECCV, 2016.
论文地址:https://arxiv.org/abs/1604.01325
extended version:end to end learning of deep visual representations for image retrieval, in arxiv, 16.10.
=====
看图说话:
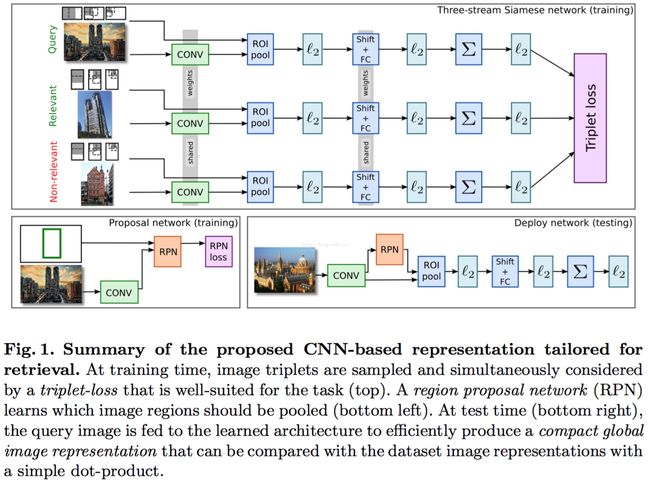
从图上可以看出该论文的整体框架:
1 基于pre-trained model on Imagenet(如VGG16)
2 从Landmarks dataset[17],中挖掘出一个full或者clean的数据集(包括类别标签 Full Datset和bounding box Clean Dataset)
3 用数据集Full Daset来进行finetune,其loss是一般的分类的loss;用Clean Dataset来进行finetune,其loss为triplet loss
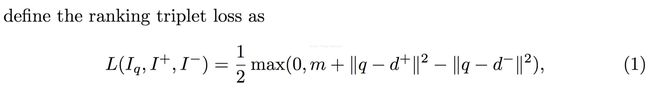
4 用训练好的模型对公开数据集进行feature extraction,similarity measure采用欧式距离(dot product)
论文中也采用了query expansion的方式来boost performance。
=====
下面重点讲下上面的1和3.
(对于数据集这个的获取,其实笔者没有怎么看懂,只明白需要提供一个clean的数据集就好)
1 pre-trained model以及该论文的framework。
这里可以采用AlexNet,VGGNet,Resnet等,取决与你想要的效果(performance和speed)
对于VGGNet(如VGG16),摘掉全连接层,取而代之的是RPN + RoI Pooling +shift + fc + L2等。
为什么要用RPN,这里为了取代rigid grid的做法(仅在test的时候取代,而finetune时,proposals就是rigid grid,具体看论文中的引用论文)。
也可以看extended version的论文,将RPN彻底取代rigid grid,形成end2end的framework。
至于shift + fc的作用就是取代一般pipeline中的PCA Whitten。
这里的L2和后续的求和(所有regions的feature对应求和得到最后global compact的image representation)和L2,仿效一般pipepline的做法。
(具体可以参考
因为以上的操作都是可导的,这样就可以将它们嵌入到一个模型中,进行forward和backward地训练模型,而再也不是一个pipeline的做法。
2 MAC feature的简单介绍:(pooling可以用sum也可以用max,或者其他的)

R-MAC:一般的MAC是针对whole image的feaute map,而R-MAC的做法就是参考RoI Pooling的做法,将bounding box 投影到feature map上,然后仅在投影在feature map上的区域进行pooling。
3 RPN
这个没有什么好说的,请参考faster rcnn。
具体是将RPN这个sub-network放到上面framework上,数据采用Clean Dataset。
4 训练
先用rigid grid的方式产生region,用于训练siamese的triplet loss或者简单的classification,对应的数据集为Clean Dataset和Full Dataset。
然后用Clean Dataset来训练RPN
最后测试的时候,用RPN产生的proposals替代rigid grid。
(不过论文中提到用Full Dataset训练的classification的模型来初始化triplet loss的模型,效果更佳)
至于具体的网络参数,请参考论文。
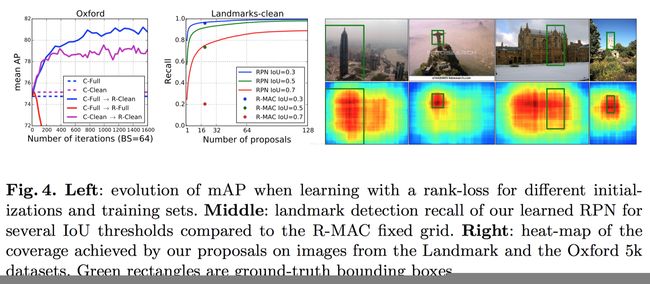
5 数据的产生
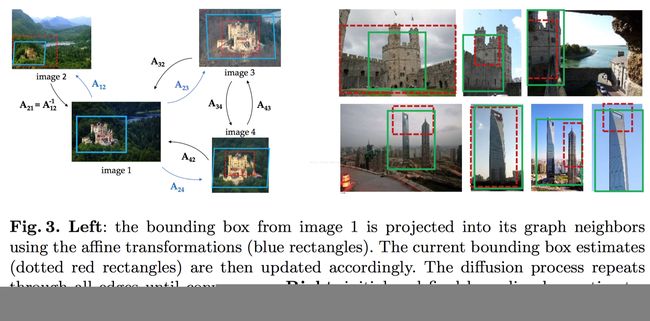
最后上效果图:
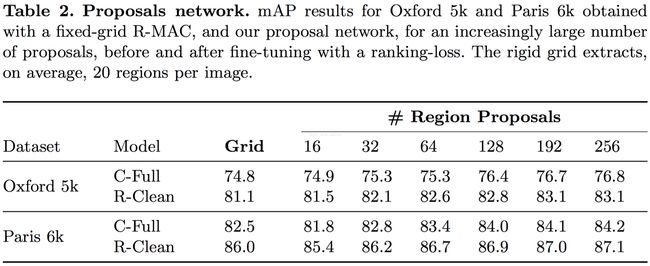
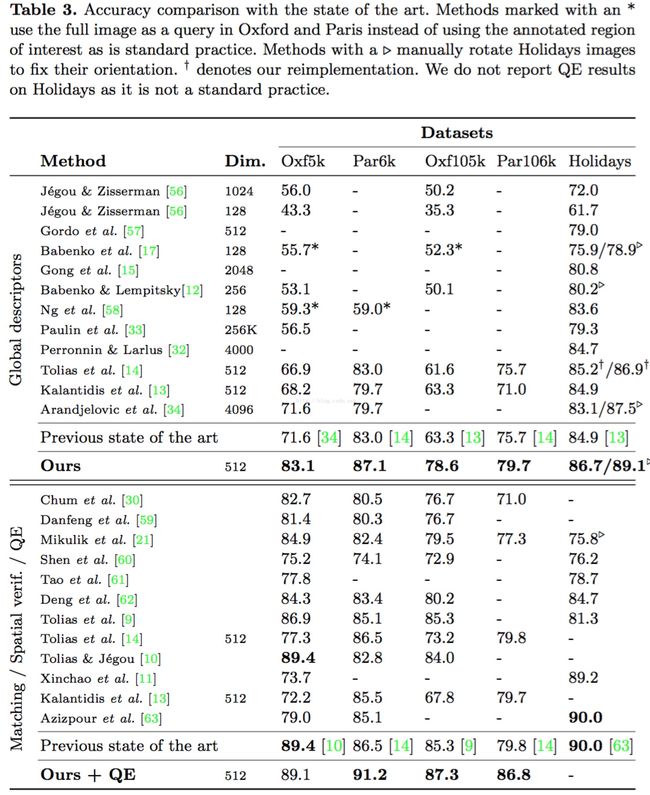
=====
如果这篇博文对你有帮助,可否赏笔者喝杯奶茶?
