自然语言处理:wordcloud+snownlp《西虹市首富》影评情感分析
前言
最近看了沈腾主演的电影《西虹市首富》,心想怎么没有十个亿砸我头上,我保证比王多鱼还败家,但是细细一想,要是真的砸脑袋上,估计就随给王多鱼他二爷去了。
闲话少说,言归正传,电影上映一段时间,王多鱼花光的十个亿早就又赚回来了,不过这个不是咱们关注的重点,今天咱们就来看看用户对这部电影的评价,并且借助机器学习来简单分析下,看看这里有什么好玩的东西。
分析工具:
分析之前先介绍下数据来源和工具:
数据来源:豆瓣影评(471条《西虹市首富》评论数据)
训练数据:好评数据(豆瓣四星以上评论28000+),差评数据(豆瓣两星以下数据13000+),训练数据不多,三星的评论数据暂时没用,为了爬取这些数据可费了不少事(水平有限),账号和IP被豆瓣封禁多次,不过可以理解,尊重人家的劳动成果。
语言:python
分词工具:jieba分词
词云:wordcloud
情感分析:snownlp
正文
先看下目前豆瓣上对这部电影的评价:

整体评分不怎么高,看看实际的评论内容,确实是有不少批评。
要想看看观众的评论里都有什么内容,这里用wordcloud制作了一个词语图(这里只采用了词频为2以上的词语并且去掉了单个字,后面会贴出代码),在这里可以看到一些关键点:

最明显的词就是麻花和喜剧了,毕竟是开心麻花团队的喜剧作品,其中有一个词也比较明显,夏洛特,看来观众喜欢把《首富》和《夏洛特》放在一起对比,后者可是沈腾的代表作,多数用户也认为认为《夏洛特》更好看。
观众虽然对该电影给出了星级评价,但是评价里的感情色彩是怎样的,下面咱就看看通过情感分析你能看到什么。
先看看观众的评分情况:
5星:10.8%
4星:32.0%
3星:41.3%
2星:11.9%
1星:3.9%
在进行情感分析时,训练数据采用的是豆瓣影评数据,其中好评数据(豆瓣四星以上评论)28000+条,差评数据(豆瓣两星以下数据)13000+条,三星的评论数据暂时没用,所以对结果还是有影响,这里我们就是简单分析,不做过多地细节处理。并且这里我们只把评论分为两类:好评、差评。
来看看情感分析的看结果:
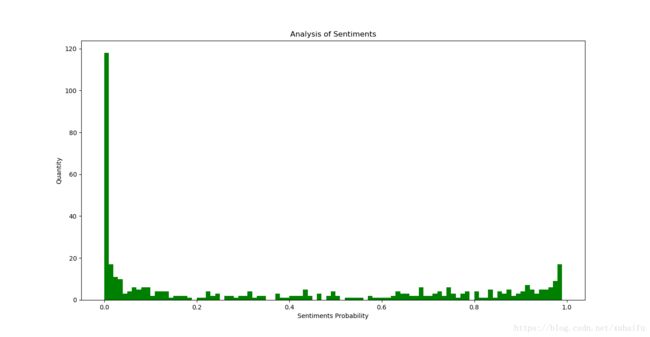
(注:数值越接近0表明情感上评价越低,越接近1情感上评价越高)
好评:207条(43.9%)
差评:264条(56.1%)
从数据分布图中看,竟然有一百多观众对这部电影是如此的不满,
看来观众给出的星级评分还是有所保守,也并那么可靠。多数观众在情感上表现的十分不满,毕竟语言是真实的。
对这部电影来说,观众言辞犀利的批评也许是件好事,帮助国产电影更进一步,而不是只为圈钱而生。
这部电影影评简单分析完了,分析的内容也许不准确,但是比单看评分有趣多了。下面就把代码一起分享出来,代码分为两部分,一部分是爬虫代码,一部分是制作图云和情感分析,代码比较简单,也有注释,就不在详解了。训练数据如有需要在评论区留下邮箱,看到定会分享。
以上内容属平时练习所做,记录学习过程,方法简单,有很多不足,欢迎大佬指正,以后分享出更有水平的文章。
爬虫代码
爬虫代码根据自己需求写的,若有需要自行修改
# -*-coding: utf-8 -*-
'''
Created on 2018-8-9
@author: xubaifu
'''
from urllib import request
from bs4 import BeautifulSoup #Beautiful Soup是一个可以从HTML或XML文件中提取结构化数据的Python库
from sqlalchemy.sql.expression import except_
import requests
import re
import random
import time
import unicodedata
import emoji
import sys
#使用session来保存登陆信息
s = requests.session()
#获取动态ip,防止ip被封
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#随机从动态ip链表中选择一条ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
print(proxies)
return proxies
#实现模拟登陆
def Login(headers,loginUrl,formData):
r = s.post(loginUrl, data=formData, headers=headers)
print( r.url)
print( formData["redir"])
if r.url == formData["redir"]:
print( "登陆成功")
else:
print( "第一次登陆失败")
page = r.text
soup = BeautifulSoup(page, "html.parser")
captchaAddr = soup.find('img', id='captcha_image')['src']
print( captchaAddr)
reCaptchaID = r'
captchaID = re.findall(reCaptchaID, page)
# captcha = raw_input('输入验证码:')
captcha = input('输入验证码:')
formData['captcha-solution'] = captcha
formData['captcha-id'] = captchaID
r = s.post(loginUrl, data=formData, headers=headers)
print (r.status_code)
return r.cookies
#获取评论内容和下一页链接
def get_data(html):
soup = BeautifulSoup(html,"lxml")
comment_list = soup.select('.comment > p')
next_page = soup.select('.next')[0].get('href')
return comment_list,next_page
if __name__ =="__main__":
absolute = 'https://movie.douban.com/subject/27605698/comments'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'}
loginUrl = 'https://www.douban.com/accounts/login?source=movie'
formData = {
"redir":"https://movie.douban.com/subject/27605698/comments?start=0&limit=20&sort=new_score&status=P",
"form_email":"**********",
"form_password":"**********",
"login":u'登录'
}
#获取动态ip
url = 'http://www.xicidaili.com/nn/'
cookies = Login(headers,loginUrl,formData)
ip_list = get_ip_list(url, headers=headers)
proxies = get_random_ip(ip_list)
current_page = absolute
next_page = ""
comment_list = []
temp_list = []
num = 0
with open('movie.txt','r', encoding='UTF-8') as fileId:
for movie_id in fileId:
movie_id = movie_id.strip()
#根据豆瓣网的地址链接规则生成start值
page_num = [20 * (x - 1) for x in range(1,11)]#默认值抓取前二十页评论(质量较高)
for start in page_num:
request_url = 'https://movie.douban.com/subject/%s/comments?start=%d&limit=20&sort=new_score&status=P&percent_type=h' %(movie_id, start)
print(request_url)
html = s.get(request_url, cookies=cookies, headers=headers, proxies=proxies).content
#temp_list,next_page = get_data(html)
soup = BeautifulSoup(html,"lxml")
comment_list = soup.select('.comment > p')
#next_page = soup.select('.next')[0].get('href')
comment_list = comment_list + temp_list
time.sleep(float(random.randint(1, 10)) / 10)
num = num + 1
#每20次更新一次ip
if num % 20 == 0:
proxies = get_random_ip(ip_list)
with open("C:\\Users\\xubaifu\\Desktop\\h.txt", 'a')as f:
for node in comment_list:
comment = node.get_text().strip().replace("\n", "")
# 中文标点转英文标点
# comment = unicodedata.normalize('NFKC', comment)
# 去除emoji表情
emoji.demojize(comment)
try:
f.write(comment + "\n")
except:
print("写入文件出错")
f.close()
fileId.close()词云与情感分析
词云和情感分析皆使用的第三方库,原理需要自己理解。由于snownlp 在做情感分析的时候使用的是网购商品评论数据,我这里使用的豆瓣影评数据,需要自己训练。
# -*-coding: utf-8 -*-
'''
Created on 2018-8-9
@author: xubaifu
'''
import codecs
import jieba.posseg as pseg
from scipy.misc import imread
from wordcloud import ImageColorGenerator
# from os import path
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import numpy as np
from snownlp import SnowNLP
from snownlp import sentiment
# 构建停用词表
stop_words = 'stopWords.txt'
stopwords = codecs.open(stop_words,'r',encoding='utf8').readlines()
stopwords = [ w.strip() for w in stopwords ]
# 结巴分词后的停用词性 [标点符号、连词、助词、副词、介词、时语素、‘的’、数词、方位词、代词]
stop_flag = ['x', 'c', 'u','d', 'p', 't', 'uj', 'm', 'f', 'r', 'ul']
class File_Review:
#自定义停用词
def load_stopwords(self, path='stopwords.txt'): #文件必须utf-8编码.encode('utf-8')
#加载停用词
with open(path,'r', encoding='UTF-8') as f:
stopwords = filter(lambda x: x, map(lambda x: x.strip(), f.readlines()))
# stopwords.extend([' ', '\t', '\n'])
return frozenset(stopwords)
# 对一篇文章分词、去停用词
def cut_words(self, filename):
result = []
with open(filename, 'r', encoding='UTF-8') as f:
text = f.read()
words = pseg.cut(text)
for word, flag in words:
if flag not in stop_flag and word not in stopwords and len(word) > 1:
result.append(word)
return result #返回数组
# return ' '.join(result) #返回字符串
#统计词频
def all_list(self, arr):
result = {}
for i in set(arr):
result[i] = arr.count(i)
return result
# 构建词云图
def draw_wordcloud(self, txt):
#读入背景图片
#bj_pic=imread('C:\\Users\\xubaifu\\Desktop\\dcd0005479.jpg')
wc1 = WordCloud(
#mask=bj_pic,
background_color="white",
width=1000,
height=860,
font_path="C:\\Windows\\Fonts\\STFANGSO.ttf",#不加这一句显示口字形乱码
margin=2)
# wc2 = wc1.generate(txt) #我们观察到generate()接受一个Unicode的对象,所以之前要把文本处理成unicode类型
wc2 = wc1.fit_words(txt) # 根据词频生成词云
#image_colors=ImageColorGenerator(bj_pic)
plt.imshow(wc2)
plt.axis("off")
plt.show()
# 情感分析
def sentiments_analyze(self):
f = open('articles.txt', 'r', encoding='UTF-8')
connects = f.readlines()
sentimentslist = []
#使用SnowNLP的sentiment模块训练数据
#sentiment.train('l.txt', 'g.txt')
#保存模型
#sentiment.save('sentiment.marshal')
#加载模型
sentiment.load('sentiment.marshal')
sum = 0
for i in connects:
s = SnowNLP(i)
# print s.sentiments
sentimentslist.append(s.sentiments)
if s.sentiments > 0.5:
sum+= 1
print(sum)
print(len(sentimentslist))
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor='g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()
if __name__ == '__main__':
file_review = File_Review()
result = file_review.cut_words('articles.txt')
# 统计词频
word_count = file_review.all_list(result)
# 筛选出词频大于2的数据
word_count={k:v for k,v in word_count.items() if v>=2}
# 制作词云
file_review.draw_wordcloud(word_count)
#情感分析
file_review.sentiments_analyze()