数据挖掘实战系列 之 Kaggle 练习项目快速入门
更多精彩原创文章请访问:https://blog.csdn.net/xudailong_blog
(一)关于Kaggle

作为小白只能这样子解释Kaggle了,不敢高声语。
(二)电影数据分析
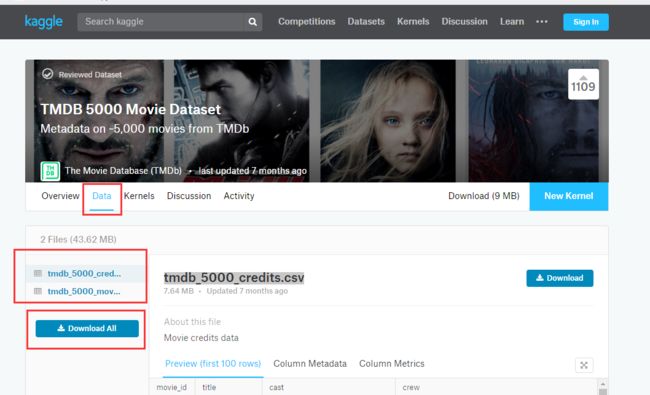
- (一)电影数据下载:
tmdb_5000_movies
这里我们要下载两个文件:
-(二)kaggle的注册:
可能一开始你没有注册kaggle,首先说一下,kaggle用163邮箱是可以注册的,然后校验的时候,你可能需要下个谷歌浏览器助手。
(三)数据分析实战部分(敲黑板)
这里练习用的jupyter notebook工具,python3环境
- (一 ) 导入数据:
# 1 导入数据
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
credits = pd.read_csv("tmdb_5000_credits.csv")
movies = pd.read_csv("tmdb_5000_movies.csv")
- (二 ) 查看数据:
# 2 查看credits的数据
credits.head()
# 2.1 查看数据
movies.head()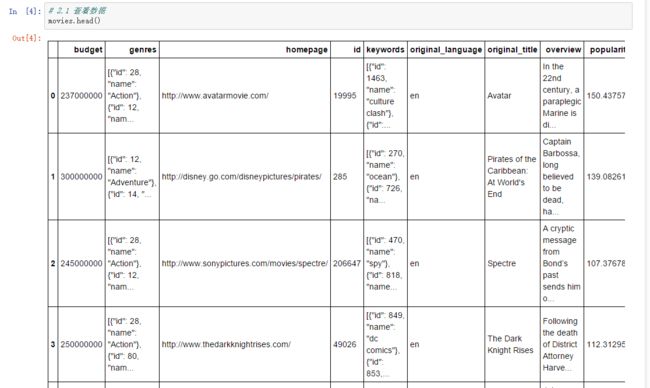
- (三 ) 数据清洗:
(1) 合并数据:
complete = pd.concat([credits,movies],axis=1)
complete.info()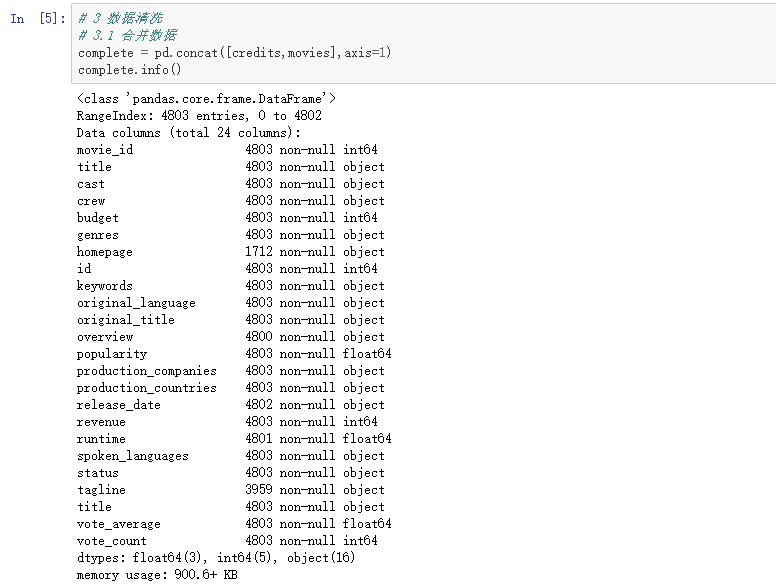
由上图可以可以看到有很多columns,这里我们只需提取出自己所需要的
(2)留下所需要的数据,并添加‘利润’一行
# 4 留下需要的数据,并添加‘利润’一行(收入-支出),这里只李露霞自己所关心的数据
movies = complete[['original_title','crew','release_date','genres',
'keywords','production_companies','production_countries',
'revenue','budget']]
movies['profit']=movies['revenue'] - movies['budget']
movies.info()
这里的报红,请忽略过
pandas知识点:得到一列新数据:movies['profit']=movies['revenue'] - movies['budget']
(3) 处理缺失值并填充
上面的图片有一个用框勾选出来的,相比于其他数据,明显的少了一个值,这里我们找一下,并为它赋值相近的数
# 4.1 处理缺失值 (release_date)
# 这里通过original_title 搜索出其对应的release_date
null_date = movies['release_date'].isnull()
movies.loc[null_date]
# 4.2 填充缺失值
movies.loc[4553,'release_date']='2014-06-01'
movies.info()
**pandas重点:
判断是否为空,定位,并赋值:**
null_date = movies['release_date'].isnull()
movies.loc[null_date]
# 4.2 填充缺失值
movies.loc[4553,'release_date']='2014-06-01'
(4)数据类型转换
这里我们将genres的字典转为正常格式的字符串类型,并且以空格的形式形式隔开。

# 4.3 数据类型转换(将genres的字典转为正常格式的字符串类型)
movies['genres'] = movies['genres'].apply(json.loads)
def jdecode(column):
z = []
for i in column:
z.append(i['name'])
return ' '.join(z)
movies['genres'] = movies['genres'].apply(jdecode)
movies.head()数据也就成了这样:
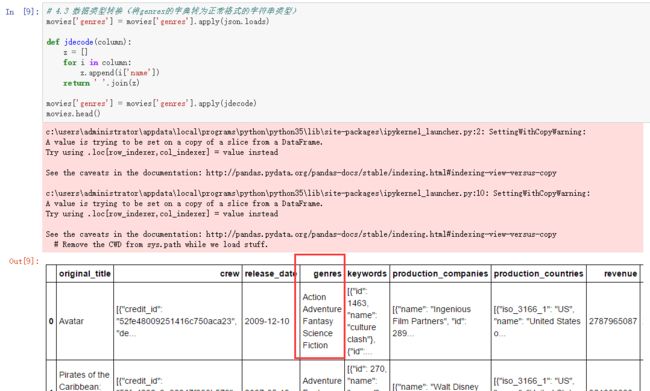
- (四 ) 选出generes_list:
generes_list 主要是作为后期数据分析可视化的一个中间值,这里稍微记一下就好
# 4.4 将genres 列表中所包含的类型存入genres_list中
genres_list = set()
for i in movies['genres'].str.split(' '):
genres_list = set().union(i,genres_list)
genres_list = list(genres_list)
genres_list.remove('')
genres_list

一看图大家都明白了,这个就是电影的分类
(四)数据可视化部分(认真脸)
提出问题:电影的类型会随着时间变化吗?若变化,是如何变化的?
我们有需要去根据电影的类型(上面的genres_list 与时间)新建一个dataframe
- (一 ) 把release_date的年月日直接转为年:
# 5 数据可视化 (电影的类型会随着时间变化吗?若变化,是如何变化的)
# 5.1 把release_date 列中的时间(年-月-日)转换为年
movies['release_date'] = pd.to_datetime(movies['release_date']).dt.year
columns = {'release_date':'year'}
movies.rename(columns=columns,inplace=True)
movies['year'].apply(int).head()
- (二 ) 向数据集中的列属性中添加所有的电影类别,1为此电影属于此类型,0 则反之:
# 5.2 向数据集中的列属性中添加所有的电影类别,1为此电影属于此类型,0 则反之
for genre in genres_list:
movies[genre] = movies['genres'].str.contains(genre).apply(lambda x:1 if x else 0)
movies.head()
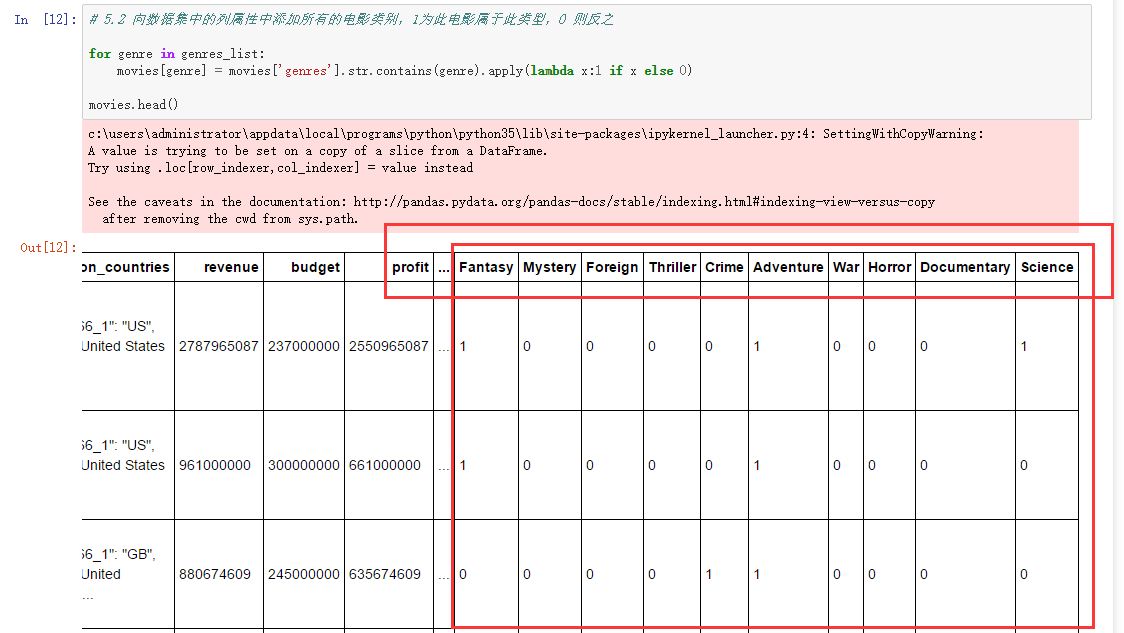
我们可以看见generes_list中也成了dataframe中的一个列
- (三) 创建名为:genre_year的DataFrame
(1)以年份为索引,电影类型为列属性,创建一个名为genre_year 的dataframe,并以年为单位计算出各类别之和;
genre_year = movies.loc[:,genres_list]
genre_year.index=movies['year']
genres = genre_year.groupby('year').sum()
# 最后几行
genres.tail()
(2)降序排列各类别之和,看下数据情况;
# 5.4 降序排列各类别之和
genresSum = genres.sum(axis=0).sort_values(ascending=False)
genresSum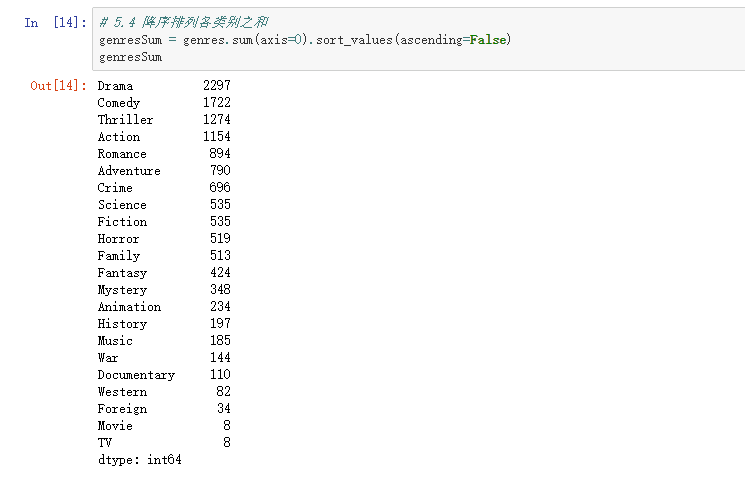
- (四) 作图:电影类型随时间的变化趋势
(1) 电影类型随时间的变化趋势:
# 这两行解决中文显示问题
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
from pylab import rcParams
params = {'legend.fontsize':12,
'legend.handlelength':10}
rcParams.update(params)
plt.figure(figsize=(13,8))
plt.plot(genres)
plt.xticks(range(1910,2021,5))
plt.legend(genres)
plt.title('电影类型随时间的变化趋势',fontsize=15)
plt.xlabel('年份',fontsize=15)
plt.ylabel('数量(部)',fontsize=15)
plt.show()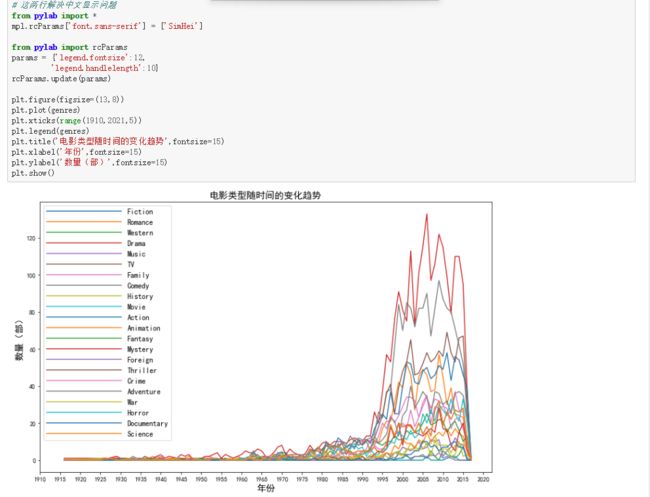
第一次感觉到这个图画得漂亮,虽然,并不漂亮,甚至有些乱糟糟的
(2)电影类型随时间的变化趋势(前5名):
# 5.6 电影类型随时间的变化趋势(前5名)
# 数列转至
tmp = genres.T
tmp = tmp.loc[:,2005].sort_values(ascending=False)
new_columns = tmp.index[:5]
new_columns
tmp_movies = genres[new_columns]
tmp_movies.tail()
from pylab import rcParams
params = {'legend.fontsize':12,
'legend.handlelength':10}
rcParams.update(params)
plt.figure(figsize=(10,4))
plt.plot(tmp_movies)
plt.xticks(range(1910,2021,10))
plt.legend(new_columns)
plt.title('1-5名电影类型随时间的变化趋势',fontsize=15)
plt.xlabel('年份',fontsize=15)
plt.ylabel('数量(部)',fontsize=15)
plt.show()

由两个图标总结:电影类型随着时间的变化而增长,在2005年的时候到了一个顶峰,排在前5名的电影类型有:Drame、Gomedy、Thiller、Romance、Action;更多信息,还请大师指点一波
(3)电影类型数量的种类排名:
fig = plt.figure(figsize=(10,7))
y = genresSum.sort_values(ascending=True)
rects = y.plot(kind='barh',label='genres')
plt.yticks(np.arange(len(y)),y.index,fontsize=15)
plt.rc('font',family='SimHei',size=15) # 中文编码
plt.title('电影类型的数量图')
plt.xlabel('电影数量(部)',fontsize=15)
plt.ylabel('电影类型',fontsize=15)
for i in range(len(y)):
plt.text(50,i,'%s'%(y[i]),fontsize=15,color='black')
plt.show()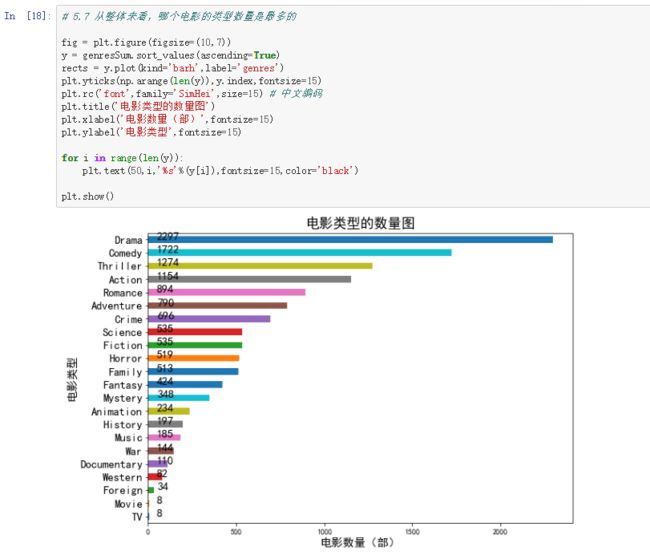
(五)电影类型与利润的牵扯
提出问题:对于不同的电影类型,支出与利润的关系是如何的?
整理出各个电影类型的平均支出,平均利润:
(一)各个电影类型的平均支出:
# 6.0 整理出各个电影类型的平均支出,平均利润
mean_genre_budget = pd.DataFrame(index=genres_list)
# 求出每种电影类型的平均支出
newarray = []
for genre in genres_list:
newarray.append(movies.groupby(genre)['budget'].mean())
newarray2 = []
for i in range(len(genres_list)):
newarray2.append(newarray[i][1])
mean_genre_budget['mean_budget']=newarray2
mean_genre_budget.head()
(二)各个电影类型的平均利润:
mean_genre_profit = pd.DataFrame(index=genres_list)
# 求出每种电影的平均利润
newarray = []
for genre in genres_list:
newarray.append(movies.groupby(genre)['profit'].mean())
newarray2 = []
for i in range(len(genres_list)):
newarray2.append(newarray[i][1])
mean_genre_profit['mean_profit']=newarray2(三)电影类型与支出、利润的关系:
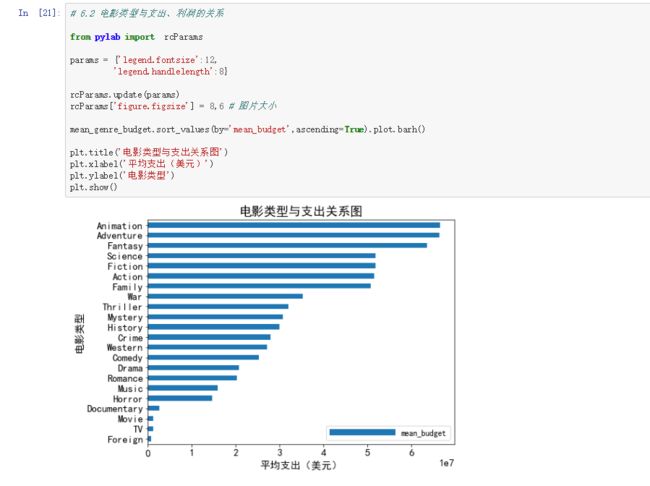
# 6.2 电影类型与支出、利润的关系
from pylab import rcParams
params = {'legend.fontsize':12,
'legend.handlelength':8}
rcParams.update(params)
rcParams['figure.figsize'] = 8,6 # 图片大小
mean_genre_budget.sort_values(by='mean_budget',ascending=True).plot.barh()
plt.title('电影类型与支出关系图')
plt.xlabel('平均支出(美元)')
plt.ylabel('电影类型')
plt.show()
(四) 电影类型与利润关系图:
# 6.3 电影类型与利润关系图
plt.figure(figsize=(12,8))
mean_genre_profit.sort_values(by='mean_profit',ascending=True).plot.barh()
plt.title('电影类型与利润关系图')
plt.xlabel('平均利润(美元)')
plt.ylabel('电影类型')
plt.show()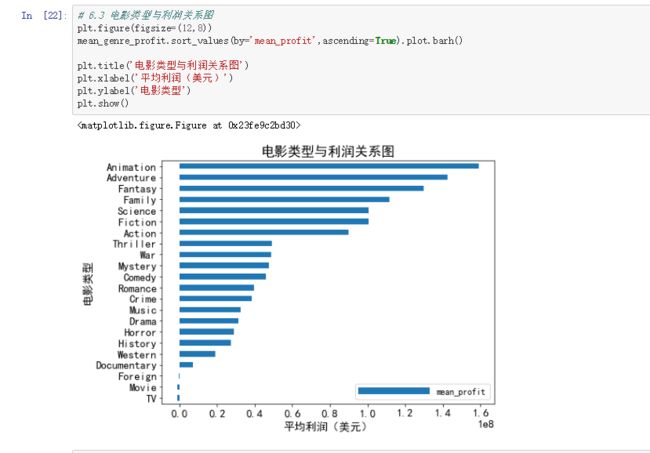
由上面两张图,我们可以得出Family这个电影类型利润还是有的。在支出关系图中排第七,在利润关系图中排第四。emm…………….似乎,家庭剧的成本不是很大,估计也就几个不同的场景吧,其他的电影类型,大家可以自己猜一下
(六)原创与改编电影与利润的牵扯
提问:原创电影与改编电影的对比情况是如何的?
(一)原创与改编数据处理:
# 7 keywords 的‘based on novel ’可以帮助我们取到需要的信息,这里也涉及到了json
# 7.0 keywords 列数据格式化
movies['keywords'] = movies['keywords'].apply(json.loads)
# 调用自定义函数decode 处理keywords列数据
movies['keywords'] = movies['keywords'].apply(jdecode)
# 查看后几行数据
movies['keywords'].tail()
# 7.1
a = 'based on novel'
movies['if_original'] = movies['keywords'].str.contains(a).apply(lambda x:'no original' if x else 'original')
movies['if_original'].value_counts()
(二)用饼状图 描述改编与原创不可描述的关系:
# 7.2 绘图,原创电影与改编电影
lable = '原创电影','改编电影'
fras = [4606,197]
plt.axes(aspect=1) # 让饼状图画出来是圆形
plt.pie(x=fras,labels=lable,autopct='%.2f%%',shadow=True,
startangle=120)
plt.rc('font',family='SimHei',size=15)# 中文编码
plt.title('原创电影与改编电影所占比例')
plt.rc('font',size=16)
plt.rc('axes',titlesize=25)
plt.show()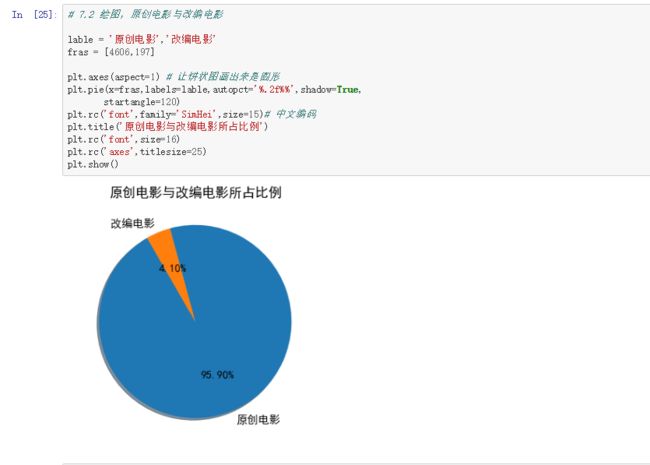
(三)原创与改编电影的支出、收入和利润:
# 7.3 整理原创与改编电影的支出、收入和利润
original_profit = movies[['if_original','budget','revenue','profit']]
original_profit=original_profit.groupby(by='if_original').mean()
original_profit.T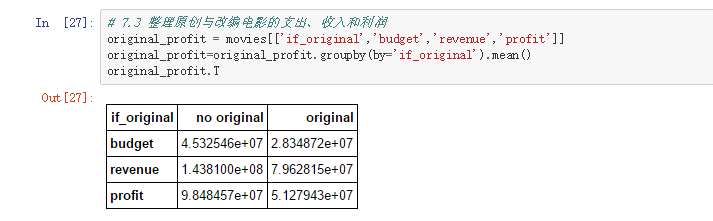
通过数据发现,改编电影的成本还是比较大的,其中的道理的话:可能改编的没有原版的好,可能改编的电影与小说的还原型相差大。
——————- 以上是学习数据挖掘,使用Kaggle练习项目所得 ———————
更多精彩原创文章请访问:https://blog.csdn.net/xudailong_blog
谢谢大家,欢迎批评指正
喜欢的不如给个关注,点个赞,搜藏一波(不要脸系列之更不要脸.GIF)