
一、项目背景
2017年8月,“李文星遭BOSS直聘求职诈骗误入传销死亡”事件,让网络求职诈骗第一次大规模曝光在大众视野范围内。
此后,网络招聘平台的高薪高待遇诈骗、培训贷诈骗、网络兼职诈骗、先收培训费再编理由辞退,等诸多诈骗形式被频繁曝光。
2018年11月7日、11日,北京市公安局官网两次发布“高薪招聘诈骗”相关信息,提醒求职者在求职时提高防范意识。
诸多诈骗形式中,影响范围最大、规模最广的,当属培训贷诈骗。招聘公司通过高薪职位吸引求职者,误导、欺骗求职者签署“培训费贷款”,而这些贷款多为互联网金融公司的高额贷款,大量刚步入社会的毕业生被骗,诸如58同城、智联招聘、51job等招聘平台上均出现过大量此类“培训贷诈骗”招聘。
除此以外存在虚假招聘公司,目的只为获取应聘者的简历数据贩卖给诈骗者,冒充正规公司,欺骗求职者。
在淘宝上,存在多家店铺可以替企业发布招聘职位。根据上架天数、刷新次数不同收费不同,但均承诺为“企业会员账号代发,重点推荐职位,排名靠前”。而且,购买代发服务“不需要你提供任何企业资质,求职者简历也是直接发到你的邮箱中”。
但是,诸多招聘诈骗并没有随着不断曝光被遏制,反而其诈骗模式在多个地区被复制,成为诈骗高发区。
如何识别招聘平台招聘诈骗黑产,提高审核门槛,进而保护求职者利益,成为传统招聘平台的迫在眉睫需要解决的问题
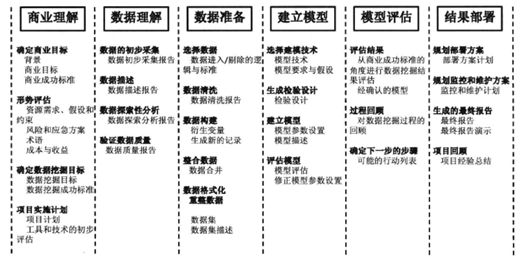
本文将采用CRISP-DM数据挖掘标准流程进行数据挖掘
CRISP-DM,即跨行业数据挖掘标准流程(如下图),是迄今为止最流行的数据挖据流程参考模型。图中所示的各个大小节点之间的关联会有循环和粗略不一,过程并不是重点,关键是数据挖掘的结果最终能嵌入到业务流程,以提升业务效率和效益。
二、商业理解
在CRISP-DM的商业理解阶段,首先对企业进行拥有资源、需求、风险、成本收益的形势评估,以便对数据挖掘目标的进行确定。
碍于本人非招聘行业出生,对招聘行业微薄的理解整理出本次数据挖掘的目标和思路方向如下:
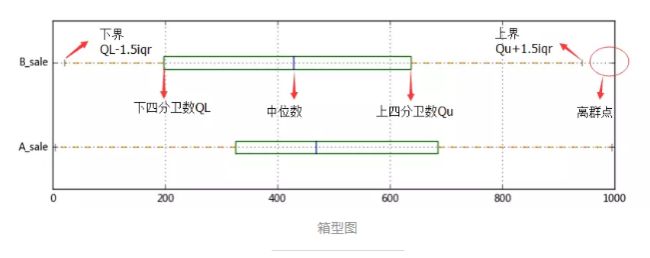
1. 数据异常检测
通过箱型图可以简单识别出异常数据,计算第一和第三四分位数(Ql、Qu),异常值是位于四分位数范围之外的数据点:
如某公司的招聘岗位在同等岗位要求下其薪资水平明显高于其他公司,或者某IP地址具有高频访问量
2. 对招聘企业进行无监督聚类分析,并对聚类结果通过描述性统计或者决策树描述企业信息,形成欺诈企业用户画像
3. 结合外部数据(如公安数据)对已有招聘企业进行有监督分类器构建模型,并对潜在招聘企业进行预测
本文主要以第二点做详细讲解
三、数据理解
3.1 数据初步采集
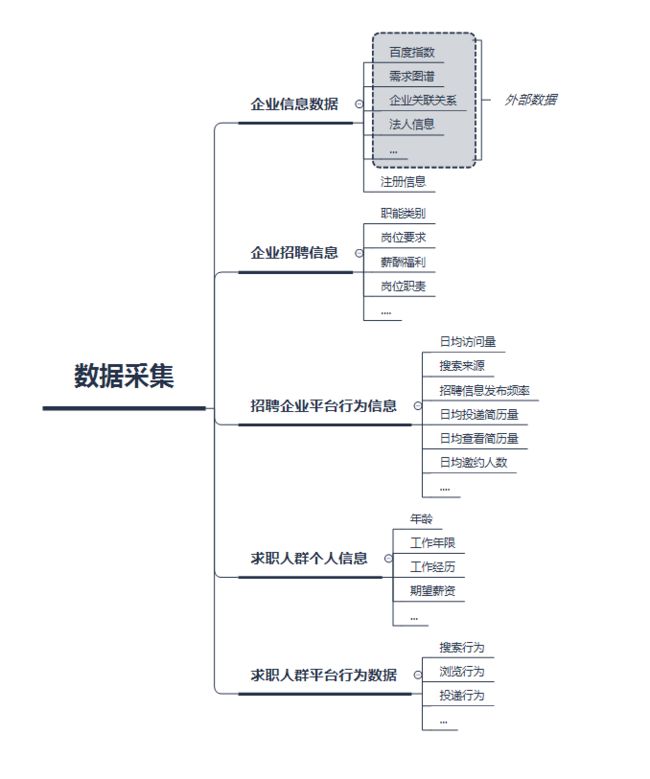
其核心的问题是:识别招聘平台招聘诈骗黑产需要那些数据?
基于业务理解,应该尽可能找出对是否为招聘诈骗黑产有影响的变量,个人理解可以采集的数据可能有如下:
3.2 数据描述
对变量进行解释性介绍,如招聘企业日均访问量,为单日访问招聘平台内该企业职位招聘网页的用户访问量,并对变量进行变量特性(连续,定性,有序,时间序列等)和变量属性(个人信息属性,状态属性,行为属性,需求属性)描述。
3.3 数据探索性分析
一般为分布分析,对异常数据进行解释,如统计方式,数据库扩容导致的缺失数据,及由于统计标准,输入错误导致的某些高频数值的出现不符合样本的实际分布。
可以通过变量的众数与中位数的差值再除以变量上四分卫与下四分位的差值(如果大于0.9)可以初步判断该变量有高频值的出现。
3.4 验证数据质量
根据获取难度(成本),覆盖率(缺失情况),准确率对数据进行可用性评估。
四、数据准备
参与聚类分析的变量应该少而精,参与聚类的指标变量如果太多,会显著增加运算时间,更重要的变量之间的相关性会严重损害聚类的效果,并且太多的变量参与会使随后的聚类群体的业务解释变得更加复杂
4.1 选择数据
基于本次数据挖掘目的和业务需求,选取招聘企业平台行为信息变量
4.2 数据清洗
重复值处理,缺失值处理,
4.3 数据构建
由于某些变量预测价值较小,需结合业务理解创造预测价值较高的新变量,如求职者简历被查看时间和简历有意向时间是时间序列的原始变量,求职者简历被查看时长=简历有意向时间点-被查看时间点,为一级衍生变量,求职者简历被查看时长均值为二级衍生变量,该变量可解释招聘企业为应聘人群简历的考察程度,如果考察程度很低,一定程度上可以说明企业没有对员工进行简历初筛,有可能是招聘诈骗企业。
4.4 数据合并
先对数据进行 Z-Score中心标准化,再对变量进行主成分降维,消除共线性,使参与聚类的变量少而精,通过观察变异变量累计贡献率,决定降维后的变量个数
4.5 数据格式化
将特征选择后的变量集合成进入模型的数据集。由于主成分降维后的数据没有可解释性,不需对数据集进行描述
数据准备阶段在数据挖掘工作中占非常大的比重,直接决定了项目的成功与否,到了项目的后期也经常会再回到这个点进行进一步的工作,最好参考行业内现有的成熟解决方案或论文。
四、建立模型
本案例选取K-Means作为聚类模型,其有如下特点:
- 简介高效,其算法的事件复杂度与数据集的大小呈正相关性
- K-Means算法不依赖顺序的算法,给定一个初始类分布,无论样本算法的顺序如何,聚类分类的结果都是一样的
也可使用基于密度的DBSCAN聚类算法
聚类流程如下图
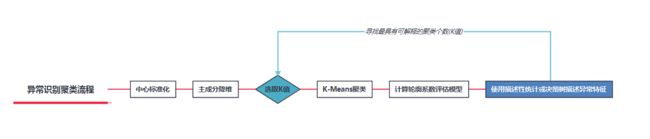
选取K值(聚类个数)一般有三种,异常识别直接取聚类个数2-10,通过K-means分别做多次聚类,然后使用每次聚类得到的标签作为被解释变量,聚类前数据整理后的数据集作为解释变量,使用描述性统计或者构建决策树描述异常特征,寻找业务理解最具可解释的聚类个数,下图为选取某个K值后的描述性统计(模拟数据)
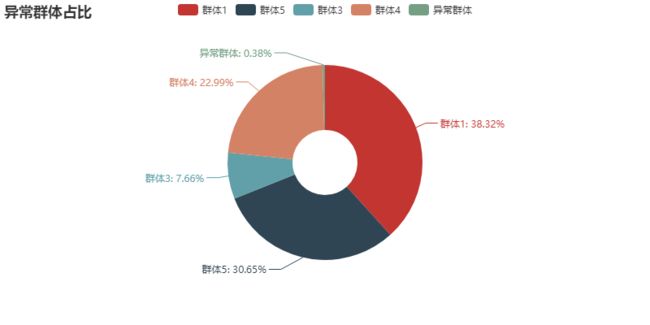
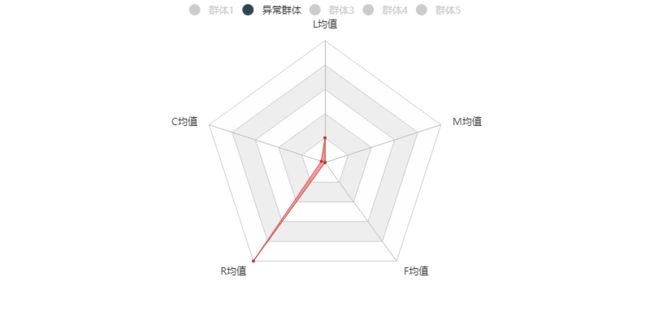
四、模型评估
由于聚类是一种无监督方法,最直接有效的评估方法是通过外部数据去验证聚类效果的好坏
其他主要评判聚类效果指标:
- 一般指标:轮廓系数silhouette(-1,1之间,值越大,聚类效果越好),兰德指数rand;
- 商业上的指标:分群结果的覆盖率;分群结果的稳定性;分群结果是否从商业上易于理解和执行
最后可以通过聚类识别的招聘诈骗黑产作为被解释变量,招聘企业信息作为解释变量,使用描述性统计或者构建决策树模型对招聘诈骗黑产进行用户画像
下图为模拟的用户画像
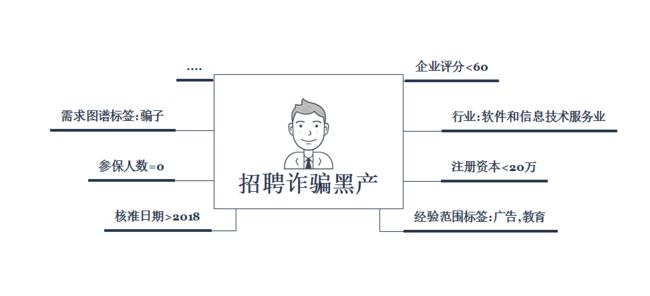
五、案例扩展
通过机器学习识别的招聘诈骗黑产结合外部数据,可对受骗应聘人群进行用户画像,在这些人群浏览或者投递疑似诈骗黑产虚假招聘岗位时,发出友善提醒或警告,对招聘平台也不失为一种有效的防护手段