CSDN机器学习笔记三 决策树、随机森林
一、决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目迎合,判断其可行性的决策分析方法,是直观运行概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的树干,故称决策树。
在机器学习 ,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的混乱程度,使用算法ID3,C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
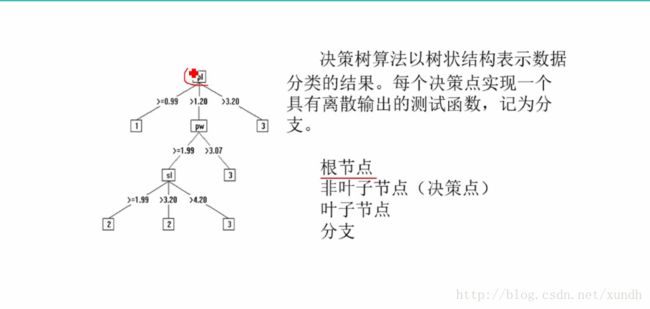
决策树是一种树形结果,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法,它是一种监督学习。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常和圆圈来表示
- 终结束:通常用三角形来表示
1.示例
1家五口人,要决策一个人喜不喜欢电子游戏。
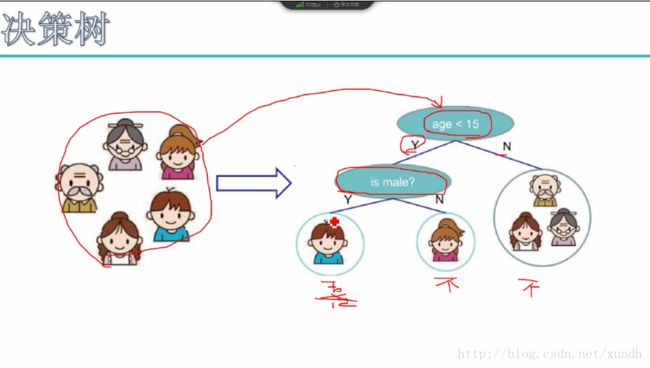
数据丢进去,数据通过节点一步步走,最终会到一个叶子节点,没有一个数据是在中间的。
2.决策树构建的基本步骤
决策树构建的基本步骤如下:
- 开始,所有记录看作一个节点
- 遍历每个变量的每一种分割方式,找到最好的分割点
- 分割成两个节点N1和N2
- 对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止。
决策树的变量可以有两种:
- 数字型(Numeric)
名称型(Nominal)
创建分支的伪代码函数createBranch()如下所示:
检测数据集中的每个子项是否属于同一分类:
if so return 类标签
else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBrandch并增加返回结果到分支节点中
return 分支节点 3.如何评估分割点的好坏?
如果一个分割点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分割点。构建决策树采用贪心算法,只考虑当前纯度差最大的情况作为分割点。
4.量化纯度
这里介绍三种纯度计算方法:
(1) Gini impurity Gini不纯度
(2) 熵(Entropy)
(3) 错误率
以上三个公式均是值越大,表示越“不纯”。实践证明三种公式的选择对最终分类准确率影响不大。三种公式只需要取一种即可,一般使用熵公式。
纯度差,也称为信息增溢(Information Gain),公式:
其中I代表不纯度,K代表分割的节点数,一般K=2。
vj表示子节点中的记录数目。上面公式实际上就是当前节点的不纯度减去子节点不纯度的加权平均数,权重由子节点记录数与当前节点记录数的比例决定。
(4) 计算熵的示例
一批数据,明天去不去打球:

首先选根节点,
构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,这样我们有望得到一棵高度最矮的决策树。
在没有给定任何天气信息时,根据历史数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为0.940:
属性有4个:outlook,temperature,humidity,windy。我们首先要决定哪个属性作为根节点。
对每项指标分别统计:在不同的取值下打球和不打球的次数。
outlook=sunny时,2/5的概率打球,3/5的概率不打球,entropy=0.971
outlook=overcast时,entropy=0
outlook=rainy时,entropy=0.971
而根据历史编译数据,outlook取值为sunny,overcast,rainy的概率分别是5/14,4/14,5/14,所以当已知变量outlook的值时,信息熵为:5/14*0.971+4/14*0+5/14*0.971=0.693
这样的话系统熵就从0.940下降到了0.693,信息增溢gain(outlook)为0.940-0.693=0.247
同样可以计算出gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048。
gain(outlook)最大(即outlook在第一步使系统的信息熵下降得最快),所以决策树的根节点就取outlook。
然后同样的计算第二个节点。
如果加一个ID数据列,作为根节点的话。计算的熵值为0。其特征是属性非常多,每个分类的数据非常少。这样的数据我们最终希望把它剔除。
评价函数:建立完决策树,要评介它好不好。
t是叶子节点,N t代表一共的样本树。
(5) 计算给定数据集的香农熵
from math import log
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #为所有可能分类创建字典
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers']
return dataSet,labels
myDat,labels = createDataSet()
print (myDat)
print (calcShannonEnt(myDat))
myDat[0][-1]='maybe'
print (calcShannonEnt(myDat))运行结果:
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
0.9709505944546686
1.3709505944546687
熵越高,则混合的数据也越多。
5.停止条件
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是每个节点点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
6.过度拟合
采用上面算法生成的决策树在事件中往往会导致过度拟合,也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过渡拟合的原因有以下几点:
- 噪音数据
- 缺少代表性数据
- 多重比较
7.决策树的一般流程
- 收集数据
- 准备数据
- 分析数据
- 训练算法
- 测试算法
- 使用算法
1.训练阶段
从给定的训练数据集DB,构造出一棵决策树
class=DecisionTree(DB)2.分类阶段
从根开始,按照决策树的分类属性逐层往下划分,直到叶节点,获得概念(决策、分类)结果。
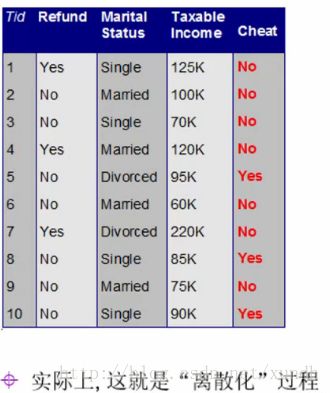
y=DecisionTree(x)对于连续值怎么处理(先要离散化)
选取(连续值的)哪个分界点?
(贪婪算法,不记得讲的是什么了。)
排序一组数据:
60 70 75,85 90 95 100 120 125 220
若进行“二分”,则可能有9个分界点。
例子:
60 70 75,85 90 95 100 120 125 220
60 70 75 85 90 95,100 120 125 220
分割成TaxIn<=97.5和Taxln>97.5
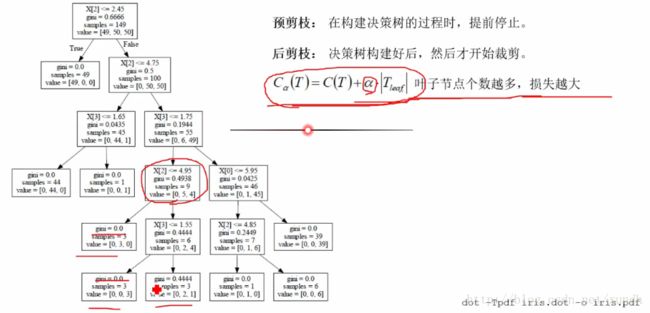
- 预剪树:数据太大了,在构建决策树的过程时,提前停止。
- 后剪树:决策树构建好后,然后才开始裁剪。实际用的少。
Cα(T)=C(T)+α*|Tleaf|
α就是个系数。
叶子节点个数越多,损失越大。
二 、随机森林
Bootstraping:有放回采样
Bagging:有放回采样n个样本一共建立分类器
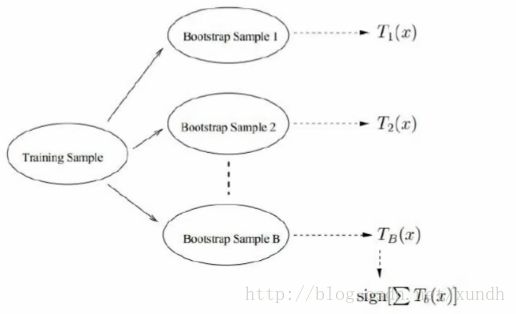
Forest:决策树是很多的,每个都要训练出来。
Rand:随机,如现在有10个数据,这10个数据当中,有些在数据采集中出现了一些问题,如9号数据是错误数据,这些数据会使决策树看起来比较奇怪。
随机森林进行了这样的假设:
- 第一重随机性,选择数据的时候随机选择其中6个,有放回的数据采样。每个树都是随机取了其中6个。不一定每棵树都会取到那个错误的数据。
- 第二重随机性,数据是由特征组成的,如一个数据有6个特征。每一个棵都随机从其中选4个特征。每个树评估标准、数据都是不一样的。
这样每个树就有了差异性,这样才能让结果更准。
三、sklearn
- splitter best or random 随机选择
- max_features 最多选多少个特征 特征小于50的时候一般使用所有的
- mx_depth,
- min_samples_split 对于某个叶子节点来说,指定小于10时不再划分
- min_samples_leaf
- min_weight_fraction_leaf 了样本权重
- min_weight_fraction_leaf
- max_leaf_nodes
- class_weight 样本各类别的权重
- min_impurity_split 这个值限制了决策树的增长