目标跟踪数据集整理(三)----GOT-10k
文章目录
- Introduction
- Related Work
- construction of GOT-10k
GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild 2018
官网页面 可以下载paper、toolkits、数据集
官网里面有很直观的介绍,还有一段视频
它总共66G,比LaSOT小,比TrackingNet更小。但
目标类别很多,有额外的标注信息(bounding box / visible ratios等),丰富的运动轨迹信息。
train: 10000个视频序列,563个目标类别,87种运动模式(e.g. 跑,游泳,滑雪,爬行,骑车,跳水,骑马,冲浪)
test: 180个视频序列,84个目标类别,32种运动模式
训练集和测试集zero-overlapped(
one-shot learning训练和测试的目标类别不会重复,however the person class is treated as an exception)
视频是从哪里来的呢?从Youtube搜索的吗?No ,雇佣了一个高质量的数据公司来进行视频的收集。那怎么标注的呢?当然也是数据公司喽,然后本文作者随机检查。
**motivation: ** By publishing GOT-10k,we hope to encourage the development of generic purposed trackers that work for a wide range of
moving objects and under diverse real-world scenarios.
**conclusion:**评测结果表明在真实世界没有约束的视频中的跟踪远远没有解决,最好的跟踪器仅仅成功跟上40%的帧
GOT-10k is backboned by the semantic hierarchy of WordNet。这句话怎么理解呢?百度一下WordNet也许就清楚了,它是按照语义层次来构建的,论文也作了详解

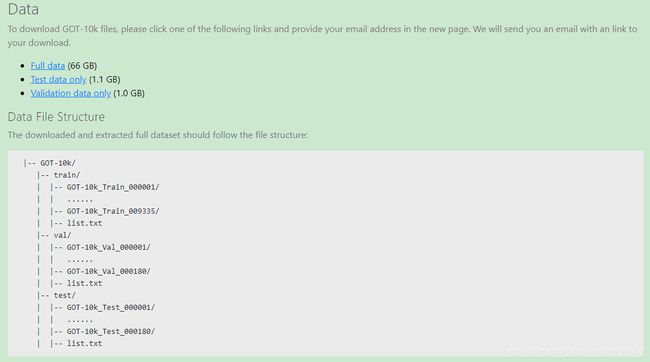

其中,meta_info信息如下:

Introduction
tracking:
Generic object tracking refers to the task of sequentially locating a moving object in a given video,without accessing to the prior knowledge(e.g.,the object class) about the object as well as its surrounding enviroment.
指出现有的跟踪数据集,在许多情况下,训练和测试序列的目标类是重合的
two purposes:
(1)想要提供一个有原则性实验设置的统一的平台来使得深度跟踪器进行实际的评估和公平的比较。
(2)想更通用“generic”,从而更好的推广到有挑战的真实世界的场景下。
这是一些截屏例子,每个视频都有两个语义标签:目标和运动类

这里是和其他数据集的比较,这里说了虽然TrackingNet 和LaSOT在视频规模上相当,但是他们的目标类别少,分别只有21、70类,这对于通用的目标跟踪器的训练和测试时不足够的,并且训练和验证的目标类别完全重复,使得验证结果偏向于特定的目标类别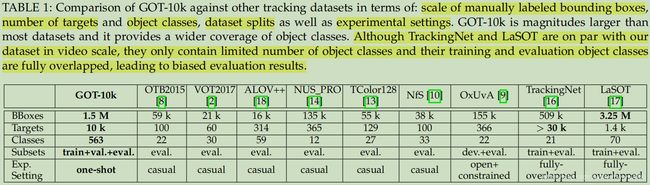
这幅图也有目标类别数目的比较,重要的是右边的表格,它表明了563种目标类别被展开为5个子树。

Related Work
**CF:**discriminative approaches,the key idea behind the correlation filters is to approximate dense image sampling by circulant shift on a single centered image patch.This approximation allows both training and inference to be fast implemented in the Fourier domain.
In generic object tracking ,traditional approaches still play an important role and some of them can achieve a performance on par with deep models using only hand-craft features
the ImageNet Video Image Detection (ImageNet-VID)(5000 videos,30 classes) and YouTube Bounding boxes(YouTube-BB)(380000 videos,23 classes are the two datasets that are most related to the tracking community.Moreover ,the video image detection datasets contain noisy segments such as short trajectories,incomplete objects and shot changes,while GOT-10k always provides clean and continuous long trajectories.
construction of GOT-10k
这幅图和其他数据集进行了 关于可见率的 对比,也就是遮挡情况。

测试集的筛选:首先和训练集的目标类别不重复,除了person;第二,将测试集作为一个随机数,在一千左右的视频中随机挑选,然后在每个筛选的样本中运行跟踪实验,评估其性能。最后分析了每个影响因素(video number,object classes,motion classes,repetition time)。
下面是最后训练、测试、验证集分布图:
评估的 标准:AO(average overlap,is an approximation of EAO) SR(success rate),并对一些属性进行了indicators defined.most challenging attribute is aspect ratio variation,deformation,rotation,fast motion.
we note that the highest AO score on GOT-10k only reaches 37.4%, compared to 74.0% on OTB2015. The SR scores also indicate that the best tracker only successfully tracks 40.4% of frames, suggesting that tracking in real-world unconstrained videos is difficult and still far from being solved.

总结就不写了,放松放松
LaSOT
TrackingNet