大数据开发实战系列之Spark电商平台
源于企业级电商网站的大数据统计分析平台,该平台以 Spark 框架为核心,对电商网站的日志进行离线和实时分析。
该大数据分析平台对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行分析,根据平台统计出来的数据,辅助公司中的
PM(产品经理)、数据分析师以及管理人员分析现有产品的情况,并根据用户行为分析结果持续改进产品的设计,以及调整公司的战略和业务。最终达到用大数据技术来帮助提升公司的业绩、营业额以及市场占有率的目标。
1.2 项目整体框架
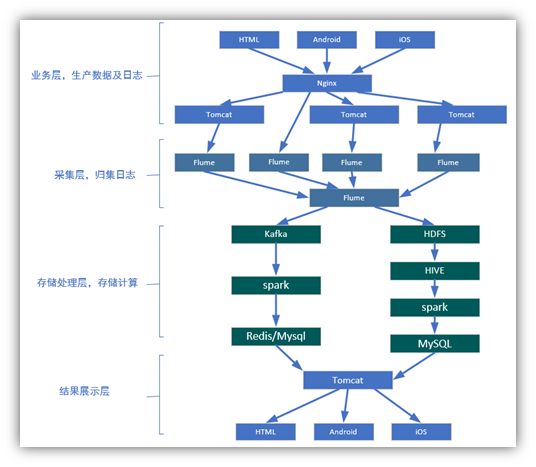
1.3 业务需求分析
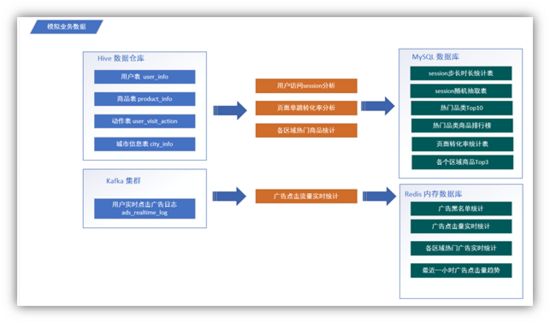
项目分为 离线分析系统 与 实时分析系统 两大模块
在离线分析系统中,我们将模拟业务数据写入 Hive 表中,离线分析系统从 Hive
中获取数据,并根据实际需求(用户访问 Session
分析、页面单跳转化率分析、各区域热门商品统计)对数据进行处理,最终将分析完毕的统计数据存储到
MySQL 的对应表格中。
在实时分析系统中,我们将模拟业务数据写入
Kafka 集群中,实时分析系统从
Kafka broker 中获取数据,通过 Spark Streaming 的流式处理对广告点击流量进行实时分析,最终将统计结果存储到 MySQL
的对应表格中。
1.4 数据源分析
1.4.1 user_visit_action
存放网站或者 APP 每天的点击流数据
| 字段名称 | 说明 |
|---|---|
| date | 日期,代表这个用户点击行为是在哪一天发生的 |
| user_id | 用户 ID,唯一标识某个用户 |
| session_id | Session ID,唯一标识某个用户的一个访问 session |
| page_id | 页面 ID,点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的 id |
| action_time | 动作时间,这个点击行为发生的时间点 |
| search_keyword | 搜索关键词,如果用户执行的是一个搜索行为,比如说在网站/app 中,搜索了某个关键词,然后会跳转到商品列表页面; |
| click_category_id | 点击品类 ID,可能是在网站首页,点击了某个品类(美食、电子设备、电脑) |
| click_product_id | 点击商品 ID,可能是在网站首页,或者是在商品列表页,点击了某个商品(比如呷哺呷哺火锅 XX 路店 3 人套餐、iphone 6s) |
| order_category_ids | 下单品类 ID,代表了可能将某些商品加入了购物车,然后一次性对购物车中的商品下了一个订单,这就代表了某次下单的行为中,有哪些商品品类,可能有 6 个商品,但是就对应了 2 个品类,比如有 3 根火腿肠(食品品类),3 个电池(日用品品类) |
| order_product_ids | 下单商品 ID,某次下单,具体对哪些商品下的订单 |
| pay_category_ids | 付款品类 ID,对某个订单,或者某几个订单,进行了一次支付的行为,对应了哪些品类 |
| pay_product_ids | 付款商品 ID,支付行为下,对应的哪些具体的商品 |
| city_id | 城市 ID,代表该用户行为发生在哪个城市 ,和城市信息表做关联 |
1.4.2 user_info
普通的用户基本信息表;这张表中存放了网站/APP 所有注册用户的基本信息
| 字段名称 | 说明 |
|---|---|
| user_id | 用户 ID,唯一标识某个用户 |
| username | 用户登录名 |
| name | 用户昵称或真实姓名 |
| age | 用户年龄 |
| professional | 用户职业 |
| gender | 用户性别 |
1.4.3 product_info
普通的商品基本信息表;这张表中存放了网站/APP 所有商品的基本信息
| 字段名称 | 说明 |
|---|---|
| proudct_id | 商品 ID,唯一标识某个商品 |
| product_name | 商品名称 |
| extend_info | 额外信息,例如商品为自营商品还是第三方商品 |
1.4.4 city_info
| 字段名称 | 说明 |
|---|---|
| city_id | 城市ID |
| city_name | 城市名称 |
| area | 地区名称,如:华北,华东,西北 |
1.4.5 实时数据
| 字段名称 | 取值范围 |
|---|---|
| timestamp | 当前时间毫秒 类型:数字 |
| userId | 用户id,类型:数字 |
| area | 东北、华北、西南 类型:文本 |
| city | 城市中文名: 北京、上海、青岛等 类型:文本 |
| adid | 点击的广告编号,数字 |
1.5 项目需求
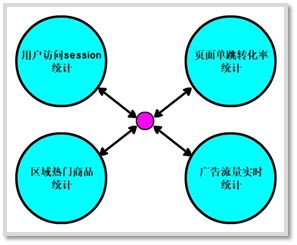
1.5.1 用户访问session统计
对用户访问 session进行统计分析,包括 session 聚合指标计算(求平均每个session步长分布比例,访问时长分布比例)、按时间比例随机抽取 session、获取每天点击、下单和购买排名前 10 的品类、并获取 top10 品类中排名前 10 的 session。该模块可以让产品经理、数据分析师以及企业管理层形象地看到各种条件下的具体用户行为以及统计指标,从而对公司的产品设计以及业务发展战略做出调整。主要使用Spark Core 实现。
1.5.2 页面单跳转化率统计
该模块主要是计算关键页面之间的单步跳转转化率,涉及到页面切片算法以及页面流匹配算法。该模块可以让产品经理、数据分析师以及企业管理层看到各个关键页面之间的转化率,从而对网页布局,进行更好的优化设计。主要使用Spark Core 实现。
1.5.3 区域热门商品统计
该模块主要实现每天统计出各个区域的top3 热门商品。该模块可以让企业管理层看到电商平台在不同区域出售的商品的整体情况,从而对公司的商品相关的战略进行调整。主要使用Spark SQL 实现。
1.5.4 广告流量实时统计
用户每次点击一个广告以后,会产生相应的埋点日志;在大数据实时统计系统中,会通过某些方式将数据写入到分布式消息队列中(Kafka)。
日志发送给后台 web 服务器(nginx),nginx 将日志数据负载均衡到多个 Tomcat 服务器上,Tomcat 服务器会不断将日志数据写入 Tomcat 日志文件中,写入后,就会被日志采集客户端(比如 flume agent)所采集,随后写入到消息队列中(kafka),我们的实时计算程序会从消息队列中(kafka)去实时地拉取数据,然后对数据进行实时的计算和统计。
这个模块的意义在于,让产品经理、高管可以实时地掌握到公司打的各种广告的投放效果。以便于后期持续地对公司的广告投放相关的战略和策略,进行调整和优化;以期望获得最好的广告收益。该模块负责实时统计公司的广告流量,包括广告展现流量和广告点击流量。实现动态黑名单机制,以及黑名单过滤;实现滑动窗口内的各城市的广告展现流量和广告点击流量的统计;实现每个区域每个广告的点击流量实时统计;实现每个区域 top3点击量的广告的统计。主要使用 SparkStreaming 实现。
预备知识
2.1 Spark

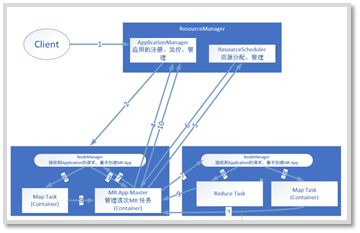
2.2 SparkCore
| 转换算子 | |
|---|---|
| map | 转换集合中的每一个元素 |
| flatMap | 转换集合中的每一个元素,压平集合,把集合打碎,打碎成非集合元素 |
| filter | 过滤元素 |
| reduceByKey | 以key为单位进行聚合 |
| groupByKey | 以key为单位进行聚合(聚在一起,RDD[key,value]=>RDD[key,iterable[value]]) |
| left join | 左外连接,全集在左边 |
| join | 内关联,取左右交集 |
| 行动算子 | |
|---|---|
| collect | 把RDD结果其提取到driver |
| take | 取前n个 |
| countByKey | 每个key的个数 Map[key,count] |
| foreach | 遍历RDD中每个元素 ,一般用于每个元素的输出 |
| foreachPartition | 按分区遍历 |
| 存储 | |
|---|---|
| saveAsTextFile | 存储为文件 |
| toDF.write.saveAsTable | 存储到hive中 |
| toDF.write.format(jdbc).option.save | 存储到mysql |
2.3 Spark RDD持久化
Spark 非常重要的一个功能特性就是可以将 RDD 持久化在内存中,当对 RDD 执行持久化操作时,每个节点都会将自己操作的 RDD 的 partition 持久化到内存中,并且在之后对该RDD 的反复使用中,直接使用内存partition。这样的话, 对于针对一个 RDD 反复执行多个操作的场景,就只要对RDD 计算一次即可,后面直接使用该 RDD,而不需要反复计算多次该 RDD
要持久化一个 RDD,只要调用其 cache()或者 persist()方法即可。
cache()和 persist()的区别在于,cache()是
persist()的一种简化方式,cache()的底层就是调用的 persist()的无参版本,同时就是d调用persist(MEMORY_ONLY),将输入持久化到内存中。
如果需要从内存中清除缓存,那么可以使用 unpersist()方法。
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的 Java 对象的方式持久化在 JVM 内存中。如果内存无法完全存储 RDD 所有的 partition,那么那些没有持久化的 partition 就会在下一次需要使用它们的时候,重新被计算 |
| MEMORY_AND_DISK | 同上,但是当某些 partition 无法存储在内存中时,会持久化到磁盘中。下次需要使用这些 partition |
| 时,需要从磁盘上读取 | |
| MEMORY_ONLY_SER | 同 MEMORY_ONLY,但是会使用 Java 序列化方式,将 Java 对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大 CPU 开销 |
| MEMORY_AND_DISK_SER | 同 MEMORY_AND_DISK,但是使用序列化方式持久化 Java 对象 |
| DISK_ONLY | 使用非序列化 Java 对象的方式持久化,完全存储到磁盘上 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 | 如果是尾部加了 2 的持久化级别,表示将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
2.4 Spark共享变量
Spark 一个非常重要的特性就是共享变量。
默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个 task 中,此时每个 task 只能操作自己的那份变量副本。如果多个 task 想要共享某个变量,那么这种方式是做不到的。
Spark 为此提供了两种共享变量,一种是 Broadcast Variable(广播变量),另一种是 Accumulator(累加变量)。Broadcast Variable 会将用到的变量,仅仅为每个Executor节点拷贝一份,更大的用途是优化性能,减少网络传输以及内存损耗。Accumulator 则可以让多个 task 共同操作一份变量,主要可以进行累加操作。Broadcast Variable 是共享读变量,task 不能去修改它,而 Accumulator 可以让多个 task 操作一个变量。
2.4.1 广播变量
2.4.2 累加器
累加器(accumulator):Accumulator 是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。它们可用于实现计数器(如 MapReduce)或总和计数。
Accumulator 是存在于 Driver 端的,从Executor节点不断把值发到 Driver 端,在 Driver 端计数(Spark UI 在 SparkContext 创建时被创建,即在 Driver 端被创建,因此它可以读取 Accumulator 的数值),存在于 Driver 端的一个值,从节点是读取不到的。
Spark 提供的 Accumulator 主要用于多个节点对一个变量进行共享性的操作。 Accumulator 只提供了累加的功能,但是却给我们提供了多个 task 对于同一个变量并行操作的功能,但是 task 只能对 Accumulator 进行累加操作,不能读取它的值,只有 Driver 程序可以读取 Accumulator 的值。
// 累加器的案例程序
class VisitSessionAccumulator extends AccumulatorV2[String, mutable.HashMap[String,Long]]{
var aggrMap=new mutable.HashMap[String,Long]()
//判断是否为空
override def isZero: Boolean = {
aggrMap.isEmpty
}
//复制累加器
override def copy(): AccumulatorV2[String, mutable.HashMap[String,Long]] = {
val accumulator = new VisitSessionAccumulator()
accumulator.aggrMap++=aggrMap
accumulator
}
//重置累加器
override def reset(): Unit = {
aggrMap=new mutable.HashMap[String,Long]()
}
//向累加器添加一个值
override def add(key: String): Unit ={
val newCount = this.aggrMap.getOrElse(key,0L)+1L
this.aggrMap(key)=newCount
}
// 两个分区的数据合并
override def merge(other: AccumulatorV2[String, mutable.HashMap[String,Long]]): Unit = {
other match {
case visitSessionAcc: VisitSessionAccumulator=> visitSessionAcc.aggrMap.foldLeft(this.aggrMap){case (aggrMap,(key,count))=>
aggrMap(key)=aggrMap.getOrElse(key,0L)+count
aggrMap
}
}
}
//获取累加器中的值
override def value: mutable.HashMap[String,Long] = {
this.aggrMap
}
}
2.5 SparkSQL
2.5.1 RDD 、 DataFrame 、DataSet
RDD
RDD,全称为 Resilient Distributed Datasets,即分布式数据集,是 Spark中最基本的数据抽象,它代表一个不可变、 可分区、里面的元素可以并行计算的集合。
DataFrame
DataFrame 是一个分布式数据容器。相比于RDD,DataFrame 更像传统数据库中的二维表格,除了数据之外,还记录数据的结构信息,即schema。同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct,array 和 map)。
DataSet
搭建过程
sparkmall
离线-需求
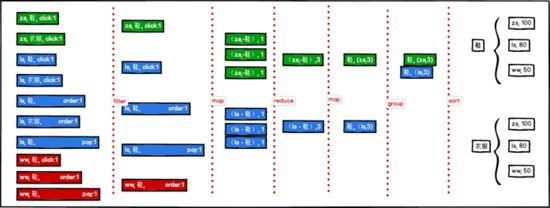
1.获取点击、下单和支付数量排名前 10 的品类
简介
在符合条件的 session中,获取点击、下单和支付数量排名前 10的品类。数据中的每个 session可能都会对一些品类的商品进行点击、下单和支付等等行为,那么现在就需要获取这些session 点击、下单和支付数量排名前10 的最热门的品类。
CREATE TABLE `category_top10` ( `taskId` text, `category_id` text, `click_count` bigint(20) DEFAULT NULL, `order_count` bigint(20) DEFAULT NULL, `pay_count` bigint(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8
思路
- 从Hive表中获取用户行为数据
- 使用累加器将不同的品类的不同指标数据聚合在一起:(K-V)-> (category-指标, SumCount)
- 将聚合后的结果转化结构:(category-指标, SumCount) -> (category,(指标,SumCount))
- 将转换结构后的相同品类的数据分组在一起
- 根据品类的不同指标进行排序(降序)
- 获取排序后的前10名
- 将结果保存到数据库中
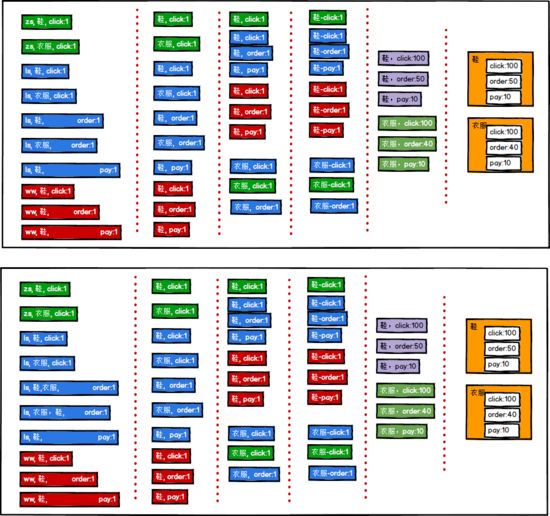
2.Top10热门品类中Top10活跃Session统计
简介
对于排名前 10的品类, 分别 获取其 点击次数 排名前 10的 sessionId。
思路
- 根据需求1中的结果对原始数据进行过滤
- 将过滤后的数据进行结构的转换:( category-sessionid, 1 )
- 将转化结构后的数据进行聚合:( category-sessionid, sum)
- 将聚合后的数据进行结构转换:( category-sessionid, sum)->( category,(sessionid, sum))
- 将转换结构的数据进行分组:(category,Iterator[(sessionid, sum) ])
- 对分组后的数据进行排序,取前10名
- 将结果保存到Mysql中
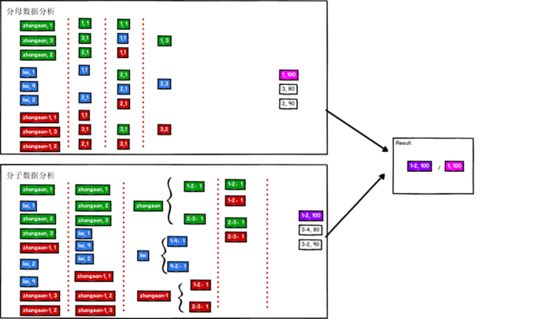
3.页面单跳转化率统计
简介
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次Session 过程中访问的页面路径3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率,比如:计算 3-5的单跳转化率,先获取符合条件的 Session对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session中访问了页面 3又紧接着访问了页面 5的次数为 B,那么 B/A就是 3-5的页面单跳转化率

页面的访问时有先后的,要做好排序
思路
- 从行为表中获取数据(pageid)
- 对数据进行筛选过滤,保留需要统计的页面数据
- 将页面数据进行结构的转换(pageid, 1)
- 将转换后的数据进行聚合统计(pageid, sum)(分母)
- 从行为表中获取数据,使用session进行分组(sessionid, Iterator[ (pageid , action_time) ])
- 对分组后的数据进行时间排序(升序)
- 将排序后的页面ID,两两结合:(1-2,2-3,3-4)
- 对数据进行筛选过滤(1-2,2-3,3-4,4-5,5-6,6-7)
- 对过滤后的数据进行结构的转换:(pageid1-pageid2, 1)
- 对转换结构后的数据进行聚合统计:(pageid1-pageid2, sum1)(分子)
- 查询对应的分母数据 (pageid1, sum2)
- 计算转化率 : sum1 / sum2
实时-需求
Kafka创建主题
bin/kafka-topics.sh --zookeeper hadoop104:2181 --create --replication-factor 3 --partitions 3 --topic ads_log
Kafka生产者
bin/kafka-console-producer.sh --broker-list hadoop104:9092,hadoop104:9092,hadoop106:9092 --topic ads_log
Kafka消费者
bin/kafka-console-consumer.sh --bootstrap-server hadoop104:9092,hadoop104:9092,hadoop106:9092 --topic ads_log --from-beginning
1.广告黑名单实时统计
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。 黑名单保存到redis中, 已加入黑名单的用户不再进行检查。
思路
1.对原始数据进行筛选(黑名单数据过滤) 2.将数据进行结构的转换 :(date-adv-user, 1) 3.将转换结构后的数据进行聚合:(date-adv-user, sum) 4.对聚合的结果进行阈值的判断 5.如果超过阈值,那么需要拉入黑名单(redis)
在程序中会遇到三个问题以及解决
问题1:task中使用的第三方对象没有序列化(连接对象)
在Executor节点创建连接
问题2:黑名单的数据只取了一次
希望获取数据的操作可以周期的执行(transform)
问题3:java序列化会出现无法反序列化(transient)的问题
采用广播变量来传递序列化数据
2.实时数据分析: 广告点击量实时统计
每天各地区各城市各广告的点击流量实时统计。
3.实时数据分析: 每天各地区 top3 热门广告
每天各地区 top3 热门广告
增加部分
1. 统计一分钟的广告点击率(实时)

2. 统计每个页面平均停留时间
