Oracle-UNDO表空间解读
UNDO概述
官方文档Managing Undo Tablespaces
UNDO 表空间用于存放UNDO数据,当执行DML操作(INSERT,UPDATE和DELETE)时,oracle会将这些操作的旧数据写入到UNDO段。
在 oracle9i之前,管理UNDO数据时使用(Rollback Segment)完成的.从oracle9i开始,管理UNDO数据不仅可以使用回滚段,还可以使用UNDO表空间。
10g开始貌似已经不在使用Rollback Segment来管理UNDO数据了,统一使用UNDO表空间。
UNDO数据的作用
1,回退事务
当执行DML操作修改数据时,UNDO数据被存放到UNDO段,而新数据则被存放到数据段中,如果事务操作存在问题,旧需要回退事务,以取消事务变化.

比如:
用户A执行了语句UPDATE emp SET sal=9999 WHERE empno=7788后发现,应该修改雇员7963的工资,而不是雇员7788的工资,那么通过执行ROLLBACK语句可以取消事务变化.
>update emp a set a.sal=9999 where a.empno=7788;
>rollback;当执行ROLLBACK命令时,oracle会将UNDO段的UNDO数据800写回的数据段中.
2,读一致性
用户检索数据库数据时,oracle 总是让用户只能看到被提交过的数据(读取提交)或特定时间点的数据(SELECT语句时间点).这样可以确保数据的一致性.
比如:
当用户A执行语句 UPDATE emp SET sal=1000 WHERE empno=7788时,UNDO记录会被存放到回滚段中,而新数据则会存放到EMP段中;假定此时该数据尚未提交,并且用户B执行SELECT sal FROM emp WHERE empno=7788,此时用户B将取得UNDO数据 800,而该数据正是在UNDO记录中取得的.
会话A:
SQL> SELECT sal FROM emp WHERE empno=7369;
SAL
---------
800.00
SQL> UPDATE emp SET sal=1000 WHERE empno=7369;
1 row updated
SQL> 会话B(在这里我们通过新开一个SQL窗口来模拟) ,如果还是继续使用会话A,则查询的仍是1000.
SQL> SELECT sal FROM emp WHERE empno=7369;
SAL
---------
800.003,事务恢复
事务恢复是例程恢复的一部分,它是由oracle server自动完成的.
如果在数据库运行过程中出现例程失败(如断电,内存故障,后台进程故障等),那么当重启oracle server时,后台进程SMON会自动执行例程恢复,执行例程恢复时,oracl会重新做所有未应用的记录.回退未提交事务.
4,闪回查询(FlashBack Query)
倒叙查询用于取得特定时间点的数据库数据, 它是9i新增加的特性,假定当前时间为上午09:00,某用户在上午10:00执行UPDATE emp SET sal= 1000 WHERE empno=7369语句,修改并提交了事务(雇员原工资为800),为了取得10:00之前的雇员工资,用户可以使用倒叙查询特征.
Oracle10g闪回查询特性的增强
Oracle 9i的闪回查询只能提供某个时间点的数据视图,并不能告诉用户这样的数据经过了几个事务、怎样的修改(UPDATE、INSERT、DELETE等),而这些信息在回滚段中是存在的,在Oracle10g中,Oracle进一步加强了闪回查询的特性,提供了以下两种闪回查询:
- 闪回版本查询(Flashback Versions Query)
- 闪回事务查询(Flashback Transaction Query)
闪回版本查询允许使用一个新的VERSIONS子句查询两个时间点或者SCN之间的数据版本。这些版本可以按照事务区分,闪回版本查询只返回提交数据,未提交数据不被显示。
Oracle10g的闪回版本查询通过使用VERSIONS子句和对数据表引入一系列的伪列(version_starttime等),可以获得对数据表的所有事务操作,versions_operation代表不同类型的操作(D-DELETE、I_INSERT、U_UPDATE),VERSIONS_XID是一个重要依据,代表了不同版本的事务ID。
Select versions_starttime,versions_endtime,versions_xid,versions_operation,字段xx
From table_name versions between timestamp minvalue and maxvalue;通过以上查询,根据versions_xid可以清晰地区分不同事务在不同时间对数据所作的更改。
由于这个查询需要从Undo中获取前镜像信息,如果Undo中的信息被覆盖,则以上查询将会失败。
数据恢复栗子
用户更新了或者误删除了一批数据(假设数据量很大),
下面用一条数据做演示:7369工号的原始工资为800 ,更新后工资为1000
UPDATE emp SET sal=1000 WHERE empno=7369;此时用户想恢复,假设删除的时间点是2016-11-13 09:00:00 之后,那么我们找到9点之前的 SCN(System Change Number 系统改变号) .
SCN提供了Oracle的内部时钟机制,可被看作逻辑时钟,这对于恢复操作是至关重要的.
1.获得当前SCN
select timestamp_to_scn(to_timestamp('2016-11-13 09:00:00','YYYY-MM-DD HH24:MI:SS')) as scn from dual ;select dbms_flashback.get_system_change_number scn from dual; --查询当前数据库的SCN2.将emp表中的scn点的数据取出
select * from emp AS OF SCN 13267939370491;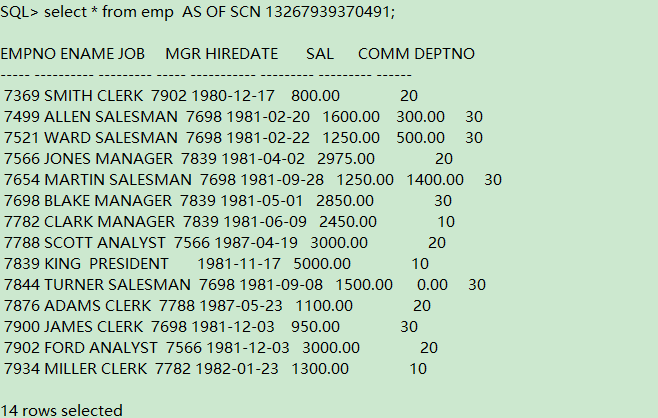
可以看到这个时间点之前的数据 7369是800.
3.然后可以根据这个数据进行还原操作
insert into emp select * from emp AS OF SCN 13267939370491;回滚段著名的ORA-01555问题
从应用角度来看ORA-01555
1.查询执行时间太长。首先是优化查询,然后考虑在数据块不繁忙的时候运行,最后考虑加大回滚段。
2.过渡频繁的提交。把能够成批提交的单条事务改成成批提交
3.exp的时候使用而来consistent = y. 这个参数主要是为了保证在exp的时候使得所有的到处的表在时间点上具有一致性,避免存在主外键关系的表由于不同的时间点的不一致而破坏了数据的完整性。建议该操作在系统空闲的时候进行。
4.由于回滚段回缩导致回滚段还没有循环使用的情况下就出现了回滚段中找不着数据的情况。只能加大回滚段增大optimal设置。
Undo 表空间的两种管理方式
Oracle 的 Undo 有两种方式: 一是使用 undo 表空间,二是使用回滚段.
我们通过 undo_management 参数来控制使用哪种方式,
如果设为 auto, 就使用 UNDO 表空间,这时必须要指定一个 UNDO 表空间。
如果设为 manual,系统启动后使用 rollback segment 方式存储 undo 信息。
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
SQL> Undo配置参数含义
- UNDO_MANAGEMENT undo的管理模式,分自动和手动
- UNDO_TABLESPACE 当前正在被使用的undo表
UNDO_RETENTION 规定多长时间内,数据不能被覆盖。
AUTO 表示undo 为自动管理模式。
900 表示在900秒内,undo上的数据不能被覆盖。
UNDOTBS1 是当前正在使用的undo表空间
如果系统没有指定 undo_management,那么系统默认以 manual 方式启动,即使设置了 auto 方式的参数,这些参数将被忽略。
当实例启动的时候,系统自动选择第一个有效的 undo 表空间或者是 rollback
segment, 如果没有有效的可用的 undo 表空间或者是回滚段,系统使用 system rollback segment。这种情况是不被推荐的,当系统运行在没有 undo 的情况下,系统会在 alert.log 中记录一条警告信息。
使用 rollback segment
当 undo_management 被设置成 MENUAL 时使用系统回滚段, 即将 undo records 记录到 SYSTEM 表空间下的 SYSTEM 段。
select segment_name,tablespace_name,bytes,next_extent from dba_segments where segment_type='ROLLBACK'; 
通过上面的这条语句,我们查到了这个用于 rollback 的 system segment 存在
与 system 表空间。 默认情况下,只有一个 segment,并且它还比较小, 所以,如果使用 system 段来存储 undo records,肯定会影响数据库的性能。 所以 Oracle是建议使用 Undo tablespace 来管理 undo records。
使用 Undo 表空间
当 undo_management 设置成 AUTO 时使用 UNDO tablespace 来管理回滚段这个时候,我们将有多个 undo segment,并且这些 segment 是存放在 UNDO 表空间里的, 这样对 DB 的性能就会提高。
select segment_name,tablespace_name,bytes,next_extent from dba_segments where segment_type='TYPE2 UNDO';
目前我们的这个数据库已经有58个undo segment了。默认的好像是10个。
除了通过dba_segment 表查看的结果, 也可以通过 v rollstat和v r o l l s t a t 和 v rollname 两个视图来查看信息, 这 2 个视图会显示所有 rollback 段的信息,包括 system 段和 undo 段。
select s.usn,n.name,s.extents,s.hwmsize,s.status from v$rollstat s, v$rollname n where s.usn=n.usn;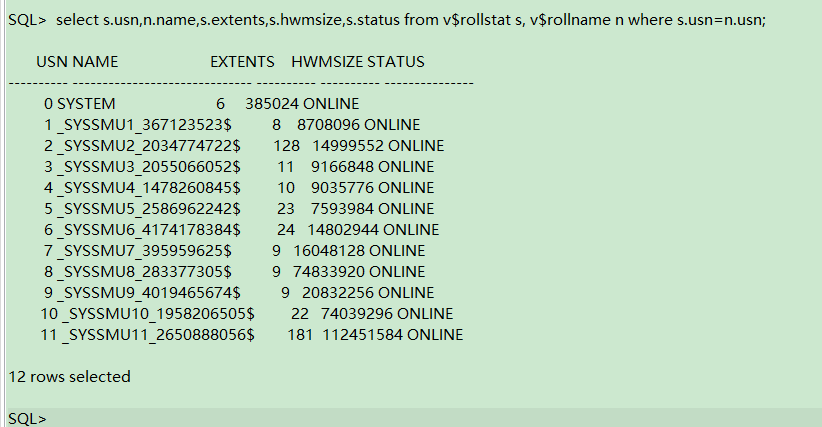
undo_retention 和 retention guarantee 参数
使用如下SQL 来查看 undo 表空间里空闲和非空闲比例:
SELECT tablespace_name, status, SUM (bytes) / 1024 / 1024 "Bytes(M)"
FROM dba_undo_extents
GROUP BY tablespace_name, status;
UNEXPIRED 和 EXPIRED 是已使用的 undo 表空间,
其中 expired 说明是已经过期的数据,也就是 15 分钟(默认情况)以外的数据,已经被覆盖, 可以认为是空闲的。
在这里就关系到一个参数: UNDO_RETENTION, 该参数用来指定 undo 记录保存的最长时间,以秒为单位,是个动态参数,完全可以在实例运行时随时修改,通常默认是 900 秒,也就是 15 分钟。
如下所示:
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
SQL> undo_retention 只是指定 undo 数据的过期时间,并不是说, undo 中的数据一定会在 undo 表空间中保存 15 分钟,比如说刚一个新事务开始的时候,如果undo 表空间已经被写满, 则新事务的数据会自动覆盖已提交事务的数据,而不管这些数据是否已过期,
因此呢,这就又关联回了第一点,当你创建一个自动管理的 undo 表空间时,还要注意其空间大小,要尽可能保证 undo 表空间有足够的存储空间。
undo_retention 中指定的时间一过,已经提交事务中的数据就立刻无法访问,它只是失效,只要不被别的事务覆盖,它会仍然存在,并可随时被 flashback 特性引用。
如果你的 undo 表空间足够大,而数据库又不是那么繁忙,那么其实undo_retention 参数的值并不会影响到你,哪怕你设置成 1,只要没有事务去覆盖 undo 数据,它就会持续有效。 总之, 要注意 undo 表空间的大小,保证其有足够的存储空间。
只有在一种情况下, undo 表空间能够确保 undo 中的数据在undo_retention指定时间过期前一定有效,就是为 undo 表空间指定 Retention Guarantee,指定之后, oracle 对于 undo 表空间中未过期的 undo 数据不会覆盖.
例如:
SQL> Alter tablespace undotbs1 retention guarantee;禁止 undo 表空间 retention guarantee
总结:
UNDO 表空间是会被重用的,只有当事务没结束,或开了 retention guarantee, 或在 undo_retention时间内不能被重用。
在 undo_retention 规定的时间内,数据都是有效的,过期后都会设为无效, 状态被改为 Expired,这些回滚段将会被看作Free Space。但是只要数据没有被覆盖就可以使用。
如果空间已满,新事务的数据会自动覆盖掉已经提交的事务数据,即使在 undo_retention 的时间内。除非指定 Retention
Guarantee 模式,才能保证在 undo_retention 内不被覆盖。
调优原则
关于oracle UNDO表空间自动管理自动调优的原则介绍,在Oracle 10gr2后面的版本中添加了UNDO信息最短保留时间段自动调优的特性,不再仅仅依据参数UNDO_RETENTION的设定,其调优原则如下:
1 当UNDO TABLESPACE为 fixed-size,Oracle将根据表空间的大小和历史使用情况,自动调整undo信息保存时间,同时忽略 undo_retention的值除非 undo_retention的guarantee 特性被启用。
2 当UNDO TABLESPACE为AUM时,Oracle将动态调整撤销信息最短保留时间为该时段最长查询时间(MAXQUERYLEN)加上300秒或参数UNDO_RETENTION间的较大者,即MAX((MAXQUERYLEN+300),UNDO_RENTION);
在自动调整启用的情况下,实际的撤销信息最短保留时间可以通过查询VUNDOSTAT视图上的TUNEDUNDORETENTION列获得。往往最短保存时间远远大于设定的UNDORETENTION。在无法就UNDOTABLESPACE做相应修改的情况,可以通过修改隐式参数”UNDOAUTOTUNE”为FALSE关闭该自动调优特性。以上设定生效后,VUNDOSTAT视图上TUNED_UNDORETENTION列不再更新,且撤销信息最短保留时间固定为参数UNDO_RETENTION的设定值。该参数可以不用重启数据库而动态设置生效。
undo 表空间满时的处理方法
默认情况下的 Undo_retention 只有 15 分钟,这个默认值,一般都无法满足
系统的需求。 一般建议是改成 3 个小时, 这样给万一的情况,多争取一些时间。
SQL> alter system set undo_retention=10800; -- 3 个小时
系统已更改。当然, undo_retention 设置的越大,所需要的 undo tablespace 也就越大。 这个需要结合自己的系统来设置这个参数。
模拟 UNDO 表空间满的情况
SQL> create undo tablespace undo datafile '/oradata/undo.dbf' size 1m;
表空间已创建。
SQL> alter tablespace undo retention guarantee;
表空间已更改。
SQL> alter system set undo_tablespace=undo;
系统已更改。
SQL> create table DBA(id number);
表已创建。
SQL> begin
2 for i in 1 .. 100000 loop
3 insert into dba values(i);
4 commit;
5 end loop;
6 end;
7 /
begin
* 第
1 行出现错误:
ORA-30036: 无法按 8 扩展段 (在还原表空间 'UNDO' 中)
ORA-06512: 在 line 3解决办法
处理方法有两种,
- 一是添加 undo 表空间的数据文件,
- 二是切换 UNDO tablespace. 这种情况下多用在 undo 表空间已经非常大的情况。
增加数据文件
SQL> ALTER TABLESPACE undo ADD DATAFILE '/oradata/undo2.dbf' size 100M reuse;
表空间已更改。
SQL> begin
2 for i in 1..100000 loop
3 insert into dba values(1);
4 commit;
5 end loop;
6 end;
7 /
PL/SQL 过程已成功完成。切换 UNDO 表空间
1、 建立新的表空间 UNDOTBS2
SQL> CREATE UNDO TABLESPACE UNDOTBS2 DATAFILE
'/oradata/und3.dbf' size 100M reuse;
表空间已创建。2、 切换到新建的 UNOD 表空间上来,操作如下
SQL> alter system set undo_tablespace=UNDOTBS2 scope=both;
系统已更改。3、将原来的 UNDO 表空间,置为脱机:
SQL> alter tablespace UNDO offline;
表空间已更改。4、删除原来的 UNDO 表空间:
SQL> drop tablespace UNDO including contents AND DATAFILES CASCADE CONSTRAINTS ;
表空间已删除。如果只是 drop tablespace UNDO ,则只会在删除控制文件里的记录,并不会物理删除文件。
Drop undo 表空间的时候必须是在未使用的情况下才能进行。如果 undo 表空间正在使用(例如事务失败,但是还没有恢复成功),那么 drop 表空间命令将失败。在 drop 表空间的时候可以使用 including contents。
undo 表空间损坏的处理方法
出现 undo 损坏的情况, 大多数是因为异常宕机,在启动的时候报的错误,DB 不能启动。
比如: ORA-00600: internal error code, arguments: [4194]
当 alert log 里出现 ORA-600 + [4194] 时,基本就可以断定,是 undo 表空间出现了损坏。 对于 Undo 损坏的情况,能用备份恢复最好,如果不能,就只能通过一些特殊的方法来恢复。
方法一: 使用 system segment
当我们使用 undo 表空间出现损坏时,可以先用 system segment 启动 DB,
启动之后,在重新创建 UNDO 表空间,在用 undo 来启动。 步骤如下:
( 1) 用 spfile 创建 pfile,然后修改参数:
#*.undo_tablespace='UNDOTBS1'
#*.undo_management='AUTO'
#*.undo_tablespace
#*.undo_retention
undo_management='MANUAL'
rollback_segments='SYSTEM'如何通过SPFILE创建PFILE?
SQL> shutdown immediate 数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> create pfile from spfile;
文件已创建。
pfile文件-linux等平台在$ORACLE_HOME/dbs下,
Oralce在启动实例的时读取$ORACLE_HOME/dbs下面的初始化文件。
( 2)用修改之后的 pfile,重启 DB
SQL> STARTUP MOUNT pfile='F:\initorcl.ora' ;( 3)删除原来的表空间,创建新的 UNDO 表空间
SQL> drop tablespace undotbs;
SQL> create undo tablespace undotbs1 datafile '/u01/oradata/undotbs1.dbf' size 10M;( 4)关闭数据库,修改 pfile 参数,然后用新的 pfile 创建 spfile,在正常启动数据库。
*.undo_tablespace='UNDOTBS1'
*.undo_management='AUTO'
#undo_management='MANUAL'
#rollback_segments='SYSTEM'创建SPFILE
SQL> CREATE SPFILE=$ORACLE_HOME/dbs/spfileSID.ora FROM PFILE $ORACLE_HOME/dbs/initSID.ora若都使用默认的,则可简写为:
SQL> CREATE SPFILE FROM PFILE;SQL> show parameter spfile
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
spfile string /oracle/product/112/dbs/spfile
cc.ora方法二: 跳过损坏的 segment
在方法一里面,我们使用了 system segment。 通过前面的说明, 我们了解到,undo segment 有多个,我们可以通过 alert log 来查看正在使用的是哪些 segment,这些段有可能损坏了。 我们只需要把这些损坏的 segment 跳过,先正常启动 DB,在创建新的 UNDO 表空间,在切换一下。
( 1)修改 pfile,添加参数:
*._corrupted_rollback_segments='_SYSSMU11$','_SYSSMU12$','_SYSSMU13$'这些字段的值, 我们通过 alert log 查看。 也可以通过如下命令查看:
#strings system01.dbf | grep _SYSSMU | cut -d $ -f 1 | sort -u( 2)用修改之后的 pfile 启动 DB
因为跳过了哪些损坏的 segment,所以 DB 可以正常启动。
( 3)创建新的 UNDO 表空间,并切换过来
SQL> create undo tablespace undotbs1 datafile '/u01/oradata/undotbs1.dbf' size 10M;
SQL> alter system set undo_tablespace=undotbs1;
SQL> drop tablespace undotbs;( 4)修改 pfile,创建 spfile,并正常启动
删除:
*._corrupted_rollback_segments='_SYSSMU11$','_SYSSMU12$','_SYSSMU13$'