yolo3制作数据集并训练模型检测路面
1.labeImg制作数据集
摁了w后再用鼠标框选,然后再选择类别,记得保存
a:前一张图片
d:后一张图片
2.代码下载:https://github.com/Gavin-Tao/yolov3
3.在主目录里创建VOCdevkit文件夹,文件夹的具体组成如下图:
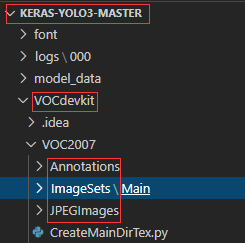
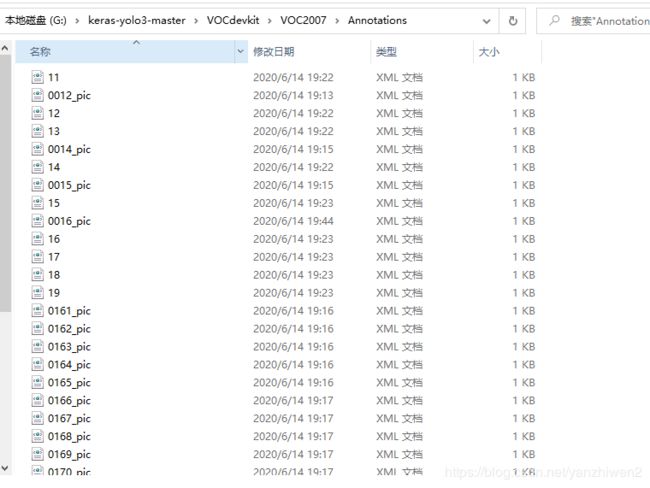
标注好的数据对应存在VOC2007目录Annotations里面(xml文件),标注的图像放在JPEGImages里面(jpg文件)。标注好的数据是一一对应的。
 4.在VOC2007目录下创建一个python代码,我这里命名CreateMainDirTex.py
4.在VOC2007目录下创建一个python代码,我这里命名CreateMainDirTex.py
CreateMainDirTex.py的代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = r'G:\keras-yolo3-master\VOCdevkit\VOC2007\Annotations'
txtsavepath = r'G:\keras-yolo3-master\VOCdevkit\VOC2007\ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(os.path.join(txtsavepath,'trainval.txt'), 'w')
ftest = open(os.path.join(txtsavepath,'test.txt'), 'w')
ftrain = open(os.path.join(txtsavepath,'train.txt'), 'w')
fval = open(os.path.join(txtsavepath,'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
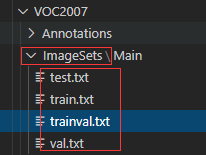
运行,结果在Main下创建了四个txt文件。
5.下载权重:将下载后的文件放在主目录中:
https://pjreddie.com/media/files/yolov3.weights
6.修改voc_annotation.py分类,更改的代码,有两个位置,一个是数据格式,一个是标注的标签名。classes对应修改为自己的类别。
执行之后,将会得到2007_train.txt、2007_test.txt、2007_val.txt,文本内容是: img_path、box位置(top left bottom right)、类别索引(0 1 2 …)
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
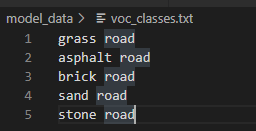
classes = ["grass road","asphalt road","stone road","sand road","brick road"]
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
遇到’NoneType’ object has no attribute 'text’是因为xml中没有difficult这个属性内容,最后导致difficult = obj.find(‘difficult’).text没起作用
因此解决办法就是看自己的xml文件中是否存在这一个属性,没有的话直接把含有difficult的语句注释掉即可,当然也有的是xml中含有Difficult,其中D是大写,只要把程序中含有difficult的句子中的difficult变为Difficult即可。
7.打开yolov3.cfg文件,Ctrl+f查找yolo(共出现了三次),每次都按下图修改
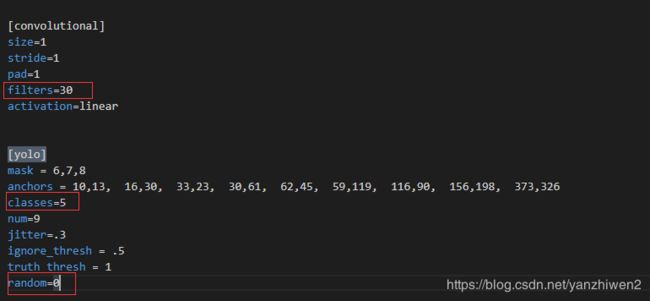
filter:3*(5+len(classes))
classes:你要训练的类别数(我这里是5类)
random:原来的是1,显存小改为0
8.修改model_data下的voc_classes.txt文件,放入你的类别。
9.修改train.py代码(用下面代码直接替换原来的代码)
"""
Retrain the YOLO model for your own dataset.
"""
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
def _main():
annotation_path = '2007_train.txt'
log_dir = 'logs/000/'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/yolo_anchors.txt'
class_names = get_classes(classes_path)
anchors = get_anchors(anchors_path)
input_shape = (416,416) # multiple of 32, hw
model = create_model(input_shape, anchors, len(class_names) )
train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'):
model.compile(optimizer='adam', loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5",
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
batch_size = 10
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.shuffle(lines)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=500,
initial_epoch=0)
model.save_weights(log_dir + 'trained_weights.h5')
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False,
weights_path='model_data/yolo_weights.h5'):
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body:
# Do not freeze 3 output layers.
num = len(model_body.layers)-7
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
np.random.shuffle(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
i %= n
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i += 1
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
if n==0 or batch_size<=0: return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == '__main__':
_main()
替换完成后,千万千万值得注意的是,因为程序中有logs/000/目录,你需要创建这样一个目录,这个目录的作用就是存放自己的数据集训练得到的模型。不然程序运行到最后会因为找不到该路径而发生错误。生成的模型trained_weights.h5如下:

10.利用自己训练好的模型进行预测
修改yolo.py文件,如下将self这三行修改为各自对应的路径。
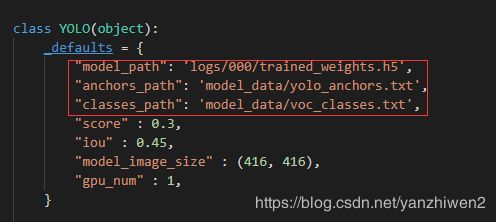
完整的yolo.py如下:
# -*- coding: utf-8 -*-
"""
Class definition of YOLO_v3 style detection model on image and video
"""
import colorsys
import os
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
class YOLO(object):
_defaults = {
"model_path": 'logs/000/trained_weights.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/voc_classes.txt',
"score" : 0.12,
"iou" : 0.3,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC))
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(frame)
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
11.在终端输入python yolo_video.py --image
 再输入要检测的图片名字
再输入要检测的图片名字
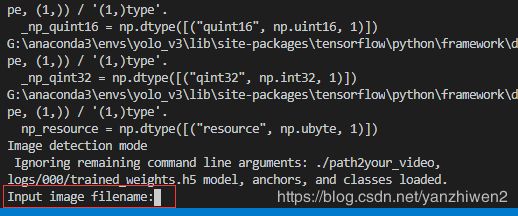
如果出现AttributeError: module 'keras.backend' has no attribute 'get_session'只需要在yolo_video.py中添加
import os
os.environ['KERAS_BACKEND']='tensorflow'
完整的yolo_video.py如下:
import sys
import argparse
import os
os.environ['KERAS_BACKEND']='tensorflow'
from yolo import YOLO, detect_video
from PIL import Image
def detect_img(yolo):
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = yolo.detect_image(image)
r_image.show()
yolo.close_session()
FLAGS = None
if __name__ == '__main__':
# class YOLO defines the default value, so suppress any default here
parser = argparse.ArgumentParser(argument_default=argparse.SUPPRESS)
'''
Command line options
'''
parser.add_argument(
'--model', type=str,
help='path to model weight file, default ' + YOLO.get_defaults("model_path")
)
parser.add_argument(
'--anchors', type=str,
help='path to anchor definitions, default ' + YOLO.get_defaults("anchors_path")
)
parser.add_argument(
'--classes', type=str,
help='path to class definitions, default ' + YOLO.get_defaults("classes_path")
)
parser.add_argument(
'--gpu_num', type=int,
help='Number of GPU to use, default ' + str(YOLO.get_defaults("gpu_num"))
)
parser.add_argument(
'--image', default=False, action="store_true",
help='Image detection mode, will ignore all positional arguments'
)
'''
Command line positional arguments -- for video detection mode
'''
parser.add_argument(
"--input", nargs='?', type=str,required=False,default='./path2your_video',
help = "Video input path"
)
parser.add_argument(
"--output", nargs='?', type=str, default="",
help = "[Optional] Video output path"
)
FLAGS = parser.parse_args()
if FLAGS.image:
"""
Image detection mode, disregard any remaining command line arguments
"""
print("Image detection mode")
if "input" in FLAGS:
print(" Ignoring remaining command line arguments: " + FLAGS.input + "," + FLAGS.output)
detect_img(YOLO(**vars(FLAGS)))
elif "input" in FLAGS:
detect_video(YOLO(**vars(FLAGS)), FLAGS.input, FLAGS.output)
else:
print("Must specify at least video_input_path. See usage with --help.")
##如果没有检测出框,主要是修改score和iou两个量,score代表的是置信度,大于这个值的框才会显示。而iou是表示预测的矩形框和真实目标的交集与并集之比,没有框的话可以适当减小。##
批量检测文件夹(TextImages)中的路面照片(jpg)
代码一:
import sys
import argparse
import os
os.environ['KERAS_BACKEND']='tensorflow'
import cv2
import numpy as np
import matplotlib.pyplot as plt
from yolo import YOLO
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
from keras.utils import multi_gpu_model
yolo=YOLO()
# if __name__ == '__main__':
# yolo = YOLO()
# for filename in os.listdir(path):
# image_path = path+'/'+filename
# image = Image.open(image_path)
# r_image = yolo.detect_image(image)
# r_image.show()
# yolo.close_session()
def road_surface_detect(dictionary_name):
for filename in os.listdir(r'./'+dictionary_name):
image_path=r'./'+dictionary_name+'/'+filename
image=Image.open(image_path)
r_image = yolo.detect_image(image)
r_image.show()
yolo.close_session()
road_surface_detect('TextImages')
代码二:
# -*- coding: utf-8 -*-
import colorsys
import os
from timeit import default_timer as timer
import time
os.environ['KERAS_BACKEND']='tensorflow'
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
from keras.utils import multi_gpu_model
path = './TextImages/' #待检测图片的位置
# 创建创建一个存储检测结果的dir
result_path = './result'
if not os.path.exists(result_path):
os.makedirs(result_path)
# result如果之前存放的有文件,全部清除
for i in os.listdir(result_path):
path_file = os.path.join(result_path,i)
if os.path.isfile(path_file):
os.remove(path_file)
#创建一个记录检测结果的文件
txt_path =result_path + '/result.txt'
file = open(txt_path,'w')
class YOLO(object):
_defaults = {
"model_path": 'logs/000/trained_weights.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/voc_classes.txt',
"score" : 0.01,
"iou" : 0.1,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer() # 开始计时
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape) #打印图片的尺寸
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img')) # 提示用于找到几个bbox
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(2e-2 * image.size[1] + 0.2).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 500
# 保存框检测出的框的个数
file.write('find '+str(len(out_boxes))+' target(s) \n')
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
# 写入检测位置
file.write(predicted_class+' score: '+str(score)+' \nlocation: top: '+str(top)+'、 bottom: '+str(bottom)+'、 left: '+str(left)+'、 right: '+str(right)+'\n')
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print('time consume:%.3f s '%(end - start))
return image
def close_session(self):
self.sess.close()
# 图片检测
if __name__ == '__main__':
t1 = time.time()
yolo = YOLO()
for filename in os.listdir(path):
image_path = path+'/'+filename
portion = os.path.split(image_path)
file.write(portion[1]+' detect_result:\n')
image = Image.open(image_path)
r_image = yolo.detect_image(image)
file.write('\n')
#r_image.show() 显示检测结果
image_save_path = './result/result_'+portion[1]
print('detect result save to....:'+image_save_path)
r_image.save(image_save_path)
time_sum = time.time() - t1
file.write('time sum: '+str(time_sum)+'s')
print('time sum:',time_sum)
file.close()
yolo.close_session()
迁移学习
1.yolo_weights.h5 预训练模型(用作迁移)
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5 #此时在model_data目录下生成yolo_weights.h5
darknet53.weights (用作重新训练)
wget https://pjreddie.com/media/files/darknet53.conv.74
yolo.h5 (yolov3-VOC训练模型,可以直接用来做预测 )
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
convert.py如下:
#! /usr/bin/env python
"""
Reads Darknet config and weights and creates Keras model with TF backend.
"""
import argparse
import configparser
import io
import os
from collections import defaultdict
import numpy as np
from keras import backend as K
from keras.layers import (Conv2D, Input, ZeroPadding2D, Add,
UpSampling2D, MaxPooling2D, Concatenate)
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from keras.utils.vis_utils import plot_model as plot
parser = argparse.ArgumentParser(description='Darknet To Keras Converter.')
parser.add_argument('config_path', help='Path to Darknet cfg file.')
parser.add_argument('weights_path', help='Path to Darknet weights file.')
parser.add_argument('output_path', help='Path to output Keras model file.')
parser.add_argument(
'-p',
'--plot_model',
help='Plot generated Keras model and save as image.',
action='store_true')
parser.add_argument(
'-w',
'--weights_only',
help='Save as Keras weights file instead of model file.',
action='store_true')
def unique_config_sections(config_file):
"""Convert all config sections to have unique names.
Adds unique suffixes to config sections for compability with configparser.
"""
section_counters = defaultdict(int)
output_stream = io.StringIO()
with open(config_file) as fin:
for line in fin:
if line.startswith('['):
section = line.strip().strip('[]')
_section = section + '_' + str(section_counters[section])
section_counters[section] += 1
line = line.replace(section, _section)
output_stream.write(line)
output_stream.seek(0)
return output_stream
# %%
def _main(args):
config_path = os.path.expanduser(args.config_path)
weights_path = os.path.expanduser(args.weights_path)
assert config_path.endswith('.cfg'), '{} is not a .cfg file'.format(
config_path)
assert weights_path.endswith(
'.weights'), '{} is not a .weights file'.format(weights_path)
output_path = os.path.expanduser(args.output_path)
assert output_path.endswith(
'.h5'), 'output path {} is not a .h5 file'.format(output_path)
output_root = os.path.splitext(output_path)[0]
# Load weights and config.
print('Loading weights.')
weights_file = open(weights_path, 'rb')
major, minor, revision = np.ndarray(
shape=(3, ), dtype='int32', buffer=weights_file.read(12))
if (major*10+minor)>=2 and major<1000 and minor<1000:
seen = np.ndarray(shape=(1,), dtype='int64', buffer=weights_file.read(8))
else:
seen = np.ndarray(shape=(1,), dtype='int32', buffer=weights_file.read(4))
print('Weights Header: ', major, minor, revision, seen)
print('Parsing Darknet config.')
unique_config_file = unique_config_sections(config_path)
cfg_parser = configparser.ConfigParser()
cfg_parser.read_file(unique_config_file)
print('Creating Keras model.')
input_layer = Input(shape=(None, None, 3))
prev_layer = input_layer
all_layers = []
weight_decay = float(cfg_parser['net_0']['decay']
) if 'net_0' in cfg_parser.sections() else 5e-4
count = 0
out_index = []
for section in cfg_parser.sections():
print('Parsing section {}'.format(section))
if section.startswith('convolutional'):
filters = int(cfg_parser[section]['filters'])
size = int(cfg_parser[section]['size'])
stride = int(cfg_parser[section]['stride'])
pad = int(cfg_parser[section]['pad'])
activation = cfg_parser[section]['activation']
batch_normalize = 'batch_normalize' in cfg_parser[section]
padding = 'same' if pad == 1 and stride == 1 else 'valid'
# Setting weights.
# Darknet serializes convolutional weights as:
# [bias/beta, [gamma, mean, variance], conv_weights]
prev_layer_shape = K.int_shape(prev_layer)
weights_shape = (size, size, prev_layer_shape[-1], filters)
darknet_w_shape = (filters, weights_shape[2], size, size)
weights_size = np.product(weights_shape)
print('conv2d', 'bn'
if batch_normalize else ' ', activation, weights_shape)
conv_bias = np.ndarray(
shape=(filters, ),
dtype='float32',
buffer=weights_file.read(filters * 4))
count += filters
if batch_normalize:
bn_weights = np.ndarray(
shape=(3, filters),
dtype='float32',
buffer=weights_file.read(filters * 12))
count += 3 * filters
bn_weight_list = [
bn_weights[0], # scale gamma
conv_bias, # shift beta
bn_weights[1], # running mean
bn_weights[2] # running var
]
conv_weights = np.ndarray(
shape=darknet_w_shape,
dtype='float32',
buffer=weights_file.read(weights_size * 4))
count += weights_size
# DarkNet conv_weights are serialized Caffe-style:
# (out_dim, in_dim, height, width)
# We would like to set these to Tensorflow order:
# (height, width, in_dim, out_dim)
conv_weights = np.transpose(conv_weights, [2, 3, 1, 0])
conv_weights = [conv_weights] if batch_normalize else [
conv_weights, conv_bias
]
# Handle activation.
act_fn = None
if activation == 'leaky':
pass # Add advanced activation later.
elif activation != 'linear':
raise ValueError(
'Unknown activation function `{}` in section {}'.format(
activation, section))
# Create Conv2D layer
if stride>1:
# Darknet uses left and top padding instead of 'same' mode
prev_layer = ZeroPadding2D(((1,0),(1,0)))(prev_layer)
conv_layer = (Conv2D(
filters, (size, size),
strides=(stride, stride),
kernel_regularizer=l2(weight_decay),
use_bias=not batch_normalize,
weights=conv_weights,
activation=act_fn,
padding=padding))(prev_layer)
if batch_normalize:
conv_layer = (BatchNormalization(
weights=bn_weight_list))(conv_layer)
prev_layer = conv_layer
if activation == 'linear':
all_layers.append(prev_layer)
elif activation == 'leaky':
act_layer = LeakyReLU(alpha=0.1)(prev_layer)
prev_layer = act_layer
all_layers.append(act_layer)
elif section.startswith('route'):
ids = [int(i) for i in cfg_parser[section]['layers'].split(',')]
layers = [all_layers[i] for i in ids]
if len(layers) > 1:
print('Concatenating route layers:', layers)
concatenate_layer = Concatenate()(layers)
all_layers.append(concatenate_layer)
prev_layer = concatenate_layer
else:
skip_layer = layers[0] # only one layer to route
all_layers.append(skip_layer)
prev_layer = skip_layer
elif section.startswith('maxpool'):
size = int(cfg_parser[section]['size'])
stride = int(cfg_parser[section]['stride'])
all_layers.append(
MaxPooling2D(
pool_size=(size, size),
strides=(stride, stride),
padding='same')(prev_layer))
prev_layer = all_layers[-1]
elif section.startswith('shortcut'):
index = int(cfg_parser[section]['from'])
activation = cfg_parser[section]['activation']
assert activation == 'linear', 'Only linear activation supported.'
all_layers.append(Add()([all_layers[index], prev_layer]))
prev_layer = all_layers[-1]
elif section.startswith('upsample'):
stride = int(cfg_parser[section]['stride'])
assert stride == 2, 'Only stride=2 supported.'
all_layers.append(UpSampling2D(stride)(prev_layer))
prev_layer = all_layers[-1]
elif section.startswith('yolo'):
out_index.append(len(all_layers)-1)
all_layers.append(None)
prev_layer = all_layers[-1]
elif section.startswith('net'):
pass
else:
raise ValueError(
'Unsupported section header type: {}'.format(section))
# Create and save model.
if len(out_index)==0: out_index.append(len(all_layers)-1)
model = Model(inputs=input_layer, outputs=[all_layers[i] for i in out_index])
print(model.summary())
if args.weights_only:
model.save_weights('{}'.format(output_path))
print('Saved Keras weights to {}'.format(output_path))
else:
model.save('{}'.format(output_path))
print('Saved Keras model to {}'.format(output_path))
# Check to see if all weights have been read.
remaining_weights = len(weights_file.read()) / 4
weights_file.close()
print('Read {} of {} from Darknet weights.'.format(count, count +
remaining_weights))
if remaining_weights > 0:
print('Warning: {} unused weights'.format(remaining_weights))
if args.plot_model:
plot(model, to_file='{}.png'.format(output_root), show_shapes=True)
print('Saved model plot to {}.png'.format(output_root))
if __name__ == '__main__':
_main(parser.parse_args())
2.重新运行train.py训练
通过更改冻结层来进行迁移学习:
load_pretrained=True, freeze_body=True
num = len(model_body.layers)-3 #只用后面三层进行训练
def create_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=True,
weights_path='model_data/yolo_weights.h5'):
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body:
# Do not freeze 3 output layers.
num = len(model_body.layers)-3
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
##当仓库更换路径时,要重新运行voc_annotation.py使生成的2007_text.txt 2007_train.txt 2007_val.txt里生成的路径与真实路径对应起来。##