NLP系列(6)_从NLP反作弊技术看马蜂窝注水事件
作者: 龙心尘
时间:2018年11月
出处:https://blog.csdn.net/longxinchen_ml/article/details/84205459,https://blog.csdn.net/han_xiaoyang/article/details/84205701
按:本文基于网易云课堂公开课分享内容整理补充完成。感谢志愿者july同学的贡献。
10月21日,朋友圈被一篇名为《估值175亿的旅游独角兽,是一座僵尸和水军构成的鬼城?》的文章刷屏。文章作者小声比比指控在线旅游网站马蜂窝存在点评大量造假的情况,包括从其他网站如大众点评、携程等抓取相关点评,及通过水军撰写虚拟点评。
文章吸引了包括本人在内的大量吃瓜群众的眼球。毕竟一家估值175亿的互联网公司被这么多实锤猛捶,十分罕见。
关于此事件相关的分析文章已经不少,但是从技术本身来分析的文章却不多。作为一个技术宅,我还是想从自己的老本行NLP上探讨一下马蜂窝事件中反作弊方与作弊方的技术实现方案。
分析思路
其实在AI码农看来,马蜂窝事件可以简化为作弊与反作弊的问题。该事件中至少存在三方:马蜂窝平台、抄袭水军、小声比比指控方。我们可以先假设马蜂窝与小声比比双方均没有主观恶意,当然抄袭水军是恶意作弊的。而主要问题就是如何通过人工智能技术找到作弊的点评、账号、评论和攻略。
当然如果想系统地处理反作弊问题,需要探讨的人工智能技术比较多样,包括NLP、时间序列分析、用户画像、数据挖掘与分析等。
而为了简化讨论、抓住重点,我们主要关注其中的NLP技术,毕竟本事件处理的主要内容都是文本。
简单梳理一下几个争论的焦点,大致包括:
- 马蜂窝是否有大量抄袭点评
- 马蜂窝是否有大量抄袭账号
- 马蜂窝是否有大量水军评论
- 马蜂窝是否有大量洗稿攻略
我们接下来就一个一个探讨。
查找水军:文本挖掘堪称“烘干神器”
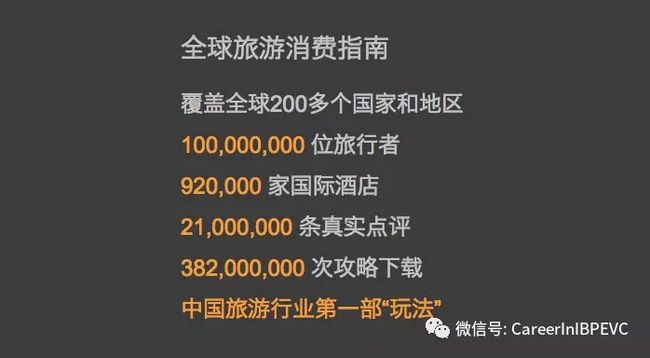
根据马蜂窝官网提供的数据,马蜂窝全站拥有超过2100万条点评,是马蜂窝对外展示的核心竞争力之一。小声比比声称:2100万条真实点评有1800万条是从大众点评和携程里抄袭过来。而且他们的判断标准十分严苛:一字不差才算抄袭,十句话有一句不同就不算抄袭。
我们可以试想一下,如果让你实现一个程序,判断两个文本存在抄袭,你会怎么办?
从一道面试题说起
不知各位程序员在刷面试的时候有没有遇到求 “最长公共子串” 的算法题?
已知子串是在原字符串中是连续不间断的字符串,输入两个字符串X、Y,求X、Y的最长公共子串。
这个面试题其实就适合我们判断抄袭的业务场景——如果最长公共子串超过一定长度,就认为X、Y之间存在抄袭。
比如设计公式:
字 符 串 X 、 Y 之 间 的 相 似 度 = 两 最 长 公 共 子 串 的 长 度 X 与 Y 长 度 的 最 大 值 字符串X、Y之间的相似度 = \frac{两最长公共子串的长度} {X与Y长度的最大值} 字符串X、Y之间的相似度=X与Y长度的最大值两最长公共子串的长度
当相似度大于阈值的时候认为文本之间存在抄袭。
这个面试题的标准答案是动态规划,其时间复杂度是O(n2)。它的优点很明显:子串的判断是完全匹配的,绝对属于实锤,判断抄袭文本的准确率是非常高的。
然而理想很丰满,现实很骨感。在实际应用中,我们会发现它不太好用。
首先是该算法不够灵活,召回率低。
TIPS:召回率率与准确率的区别:
1.召回率,所有抄袭文本中被判断为抄袭的文本所占的比例。
2.准确率,所有被判断为抄袭的文本中真是抄袭文本所占的比例。
3.准确率与召回率往往是一对矛盾,难以同时兼顾。
所以,如果作弊者在文字中添加一些无损原意的信息或者替换一些同义词,该算法就无法查出。如对于句子 :
“我们这些路痴好不容易找到了饭店的西门”。
我们把 “饭店” 变为 “餐馆”,把 “我们” 变为 “俺们”,或者加入一些马蜂窝的网址,就使得新生成的句子与原句子不完全相同。这样就难以相互抄袭了。
幸好马蜂窝的抄袭水军技术不行,直接大量硬抄,被这么轻易抓住也是活该。但如果他们稍微聪明一点做一些文本处理呢?
而且,该算法的另一个缺点更为致命:速度慢。对于2100万条真实点评,只有O(n2)的时间复杂度,处理起来还是挺辛苦的。
那怎么改进呢?NLP的工程师们早就想到这个问题,并且为此专门衍生出了NLP中一个非常核心的领域——文本表示。至于什么是文本表示,简单的说就是不将文本视为字符串,而视为在数学上处理起来更为方便的向量。而怎么把字符串变为向量,就是文本表示的核心问题。
最简单的文本表示:词袋子模型
词袋子模型是一种非常经典的文本表示。顾名思义,它就是将字符串视为一个 “装满字符(词)的袋子” ,袋子里的 词语是随便摆放的。而两个词袋子的相似程度就以它们重合的词及其相关分布进行判断。

举个例子,对于句子:
“我们这些路痴好不容易找到了饭店的西门”。
我们先进行分词,将所有出现的词储存为一个词表。然后依据 “词语是否出现在词表中” 可以将这句话变为这样的向量:
[1,0,1,1,1,0,0,1,…]
其中向量的每个维度唯一对应着词表中的一个词。可见这个向量的大部分位置是0值,这种情况叫作**“稀疏”**。为了减少存储空间,我们也可以只储存非零值的位置。
表示成向量的方法有个非常大的好处是判断 相似度速度非常快,只要计算两个向量的余弦值(cos)就够了。这只要O(n)的时间复杂度,比之前的方法快了整整一个数量级!
在实际应用中,这种方法非常常用。而且对于中等篇幅的文本词袋子模型的效果还不错。召回率比较高。
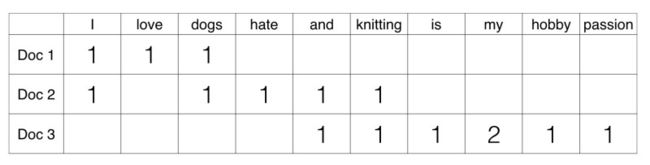
下图是演示两个英文文本通过词袋子模型判断相似度的例子。

但词袋子模型的缺点也很明显:
- 其准确率往往比较低。
- 只统计词语是否出现或者词频,会被无意义的词汇所影响。如: “这里的猪脑、肥肠好吃”与“这里的沙拉好吃”会被认为很相似。一个改进方式是进行文本预处理。
- 对于句子级别的短文本识别能力较弱。如对于句子“我点了牛肚、肥肠、藕片、金针菇之类,味道还不错”,其关键信息是“牛肚、肥肠、藕片、金针菇”,通过他们我们能判断出这家店应该是火锅、麻辣烫之类的。但这样语义层面的信息简单的词袋子模型识别不出来。它改进的方式是用上深度学习,至少要用上词向量。
- 无法关注词语之间的顺序关系,这是词袋子模型最大的缺点。如“武松打老虎”跟“老虎打武松”在词袋子模型中是认为一样的。它改进的方式是用上更复杂的深度学习,如CNN、RNN、Attention等。
文本预处理
刚才说到文本预处理技术。他们典型的方法包括:
- 去除停用词,如“的”“是”“我”等等。
- 文字、字母、标点符号统一,比如繁体统一转换为简体、大写统一转换为小写、标点统一转换为半角等。其实就是准备几个字典加几个正则表达式就行。
- 统计词频与逆文档频率——TFIDF。不仅考虑词语是否出现,还考虑其出现的频率(TF)。不仅考虑这个词在当下文本的出现的概率,还考虑出现该词语的文档占总文档出现的频率(DF)。其基本假设是如果一个词语在不同的文档中反复出现,那么它对于识别该文本并不重要。如高频词“我们”、“那么”之类。
基于深度学习的文本表示:词向量
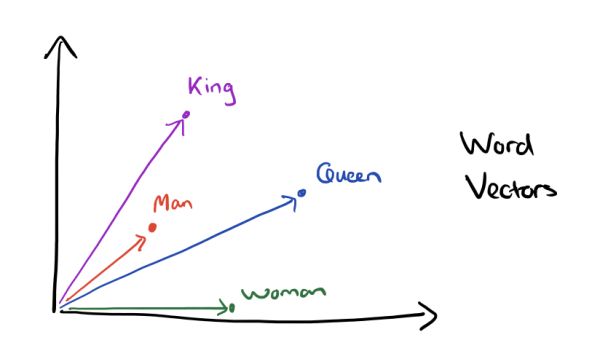
在词袋子模型中,每个词只对应一个词表向量中的某一个位置,向量其他位置为0。这种术语叫作 “one-hot表示”,导致每个词都是孤立、离散的。而词向量出来之后,几乎颠覆了大家的认知——原来可以用一个稠密的短向量来表示一个词。比如“国王”这个词可以对应向量[0.5,0.713],“女王”这个词可以对应向量[0.713,0.5]。至于每一维度的数值是什么意思可以先不管,直接拿来用。
词向量最神奇的一点是可以用简单的向量运算表达类比关系。比如可以直接用等式 “国王-男人+女人=女王” 来表达 “国王与男人的关系类似女王与女人的关系” 。这就带有了很强的 语义信息 。
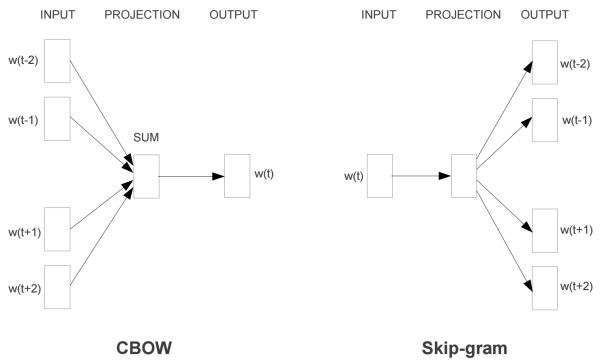
下图是Word2vec的两个典型的机器学习模型图(CBOW和Skip-gram)。CBOW模型通过一个词的上下文(N个词)预测当前词,而Skip-gram则是反过来,基于一个词来预测其上下文(N个词)。两种不同的算法都可以得到每个词的词向量。
基于深度学习的文本表示:句向量
既然有了词级别的向量表示,那也可以有句子级别的向量表示。当然最简单的句子级别向量表示就是将句子中所有词的词向量加起来,也很常用。这种方法本质上也是一种词袋子模型,因为它也没有考虑到词语间的顺序。
那怎么建模句子向量呢?一种简单的方法是通过神经网络将输入的词向量经过CNN\RNN\self-attention机制得到整个句子的表示,最后用一层max pooling转换到固定长度的向量。计算两个句子的余弦值(cos)作为它们的相似度。
直接用深度神经网络算出相似度
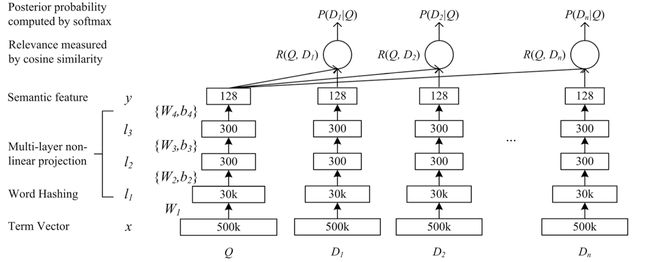
一种更加激进的方法是直接用神经网络建模句子之间的相似度,句子向量都不必用。如下图所示,在搜索引擎的场景下,把用户的搜索语句(query)和搜索引擎展示的网页文本(document)都输入给神经网络。之后分别输出query与各个document的相似度,以用户是否点击作为标注进行建模。得到模型后,就可以直接给任意两句话计算相似度了。
可见,这种方法比较依赖海量的标注数据。而搜索引擎天然具有这海量的标注数据。那如果我没有搜索引擎这么多的数据怎么办?其实像百度这样的搜索引擎公司都开放了api,直接用它们训练好的模型就是了。
打造综合解决方案
现实的业务场景往往十分复杂,需要多种算法进行组合。对于判断马蜂窝点评抄袭的场景,综合以上的介绍,我们可以形成下面的简单方案:
- 先用基于统计的词袋子模型快速筛选一批相似点评
- 再用再用字符串匹配确定一批实锤
- 把中间地带的文本用深度学习筛选一遍,捞一批一批漏网之鱼
- 最后再用人工校验,分析badcase,进一步优化模型……
识别用户:文本分类看穿“忽男忽女”
马蜂窝事件中,另一个双方都承认的实锤是存在一批抄袭账号。而小声比比方面对抄袭账号的判断标准也比较严格:同时抄袭150个大众点评账号的才算作弊账号。
当然这批马蜂窝的抄袭水军的技术的确不行,简单的规则就可以捞出一大把。但我们仍可以试想一下, 如果抄袭者聪明一些,每个机器人账号只抄袭几个账号, 那如何找出他们?
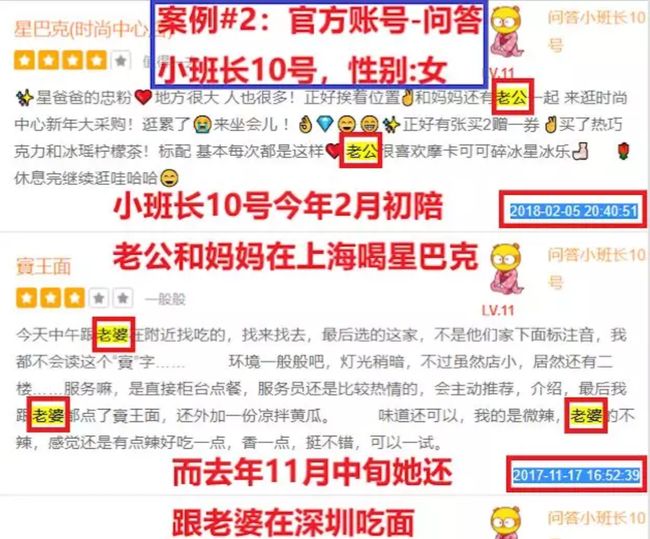
其实,我们可以利用抄袭账号的另一个实锤:性别自相矛盾。如果同一个用户的一部分点评明显是男性,另一部分明显是女性,就是一个自相矛盾,就基本可以判断其是抄袭账号。
这些问题理论上还可以扩展到年龄、身份的自相矛盾。这些本质上就是一个文本分类的问题。我们将从传统方法、机器学习、深度学习的角度加以说明。
传统方法:关键词匹配
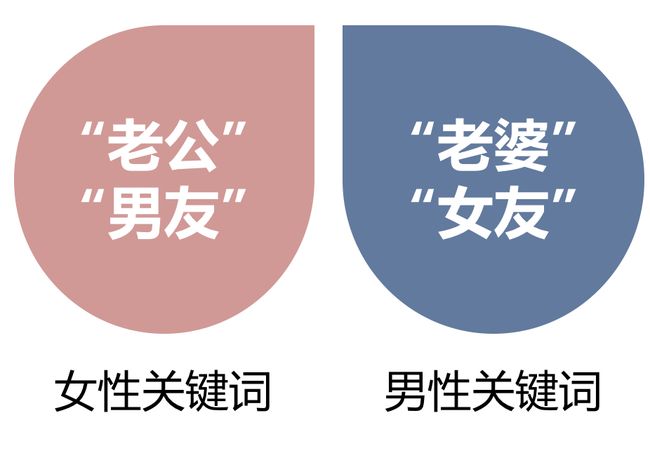
关键词匹配是指关键词与页面中的内容进行匹配。如果文本中出现了某些典型关键词,就可以直接判断该文本所属的分类。如上图的例子,我们可以抽出女性关键词:“老公”、“男友”等。男性关键词:“老婆”、“女友”等。我们将已知关键词拿到文中去进行匹配,就可以识别账号评论的性别。
但这种关键词匹配的方法同样存在准确率高、召回率低的问题。
机器学习方法:词袋子模型+朴素贝叶斯/逻辑回归/支持向量机
词袋模型上文已提到过,是一种基于统计的将文本中的词进行统一表示的方法。而得到这些文档的向量表示后,可以采用朴素贝叶斯、逻辑回归或支持向量机等机器学习的算法模型对文本加以分类,从而识别出各文本中的人物年龄、性别等信息,进而找出矛盾点及识别出账号的真伪。
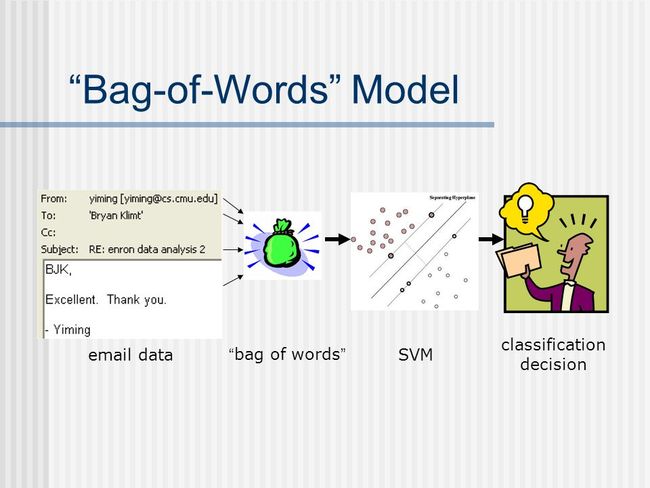
如下图显示了词袋模型与支持向量机结合对邮件进行分类的过程。
采用机器学习的方法使模型的召回率有所提升,但正如前文所说,词袋模型无法实现对文本顺序的判断,因此准确率可能不满足要求。
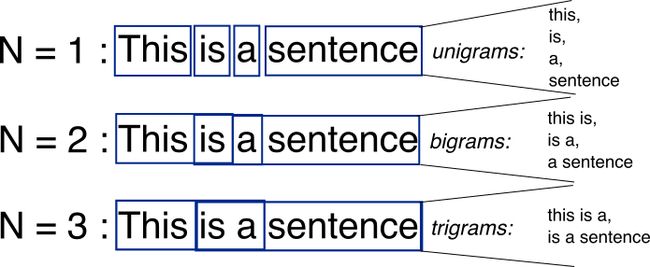
传统改进方法是进行大量的特征工程。比如增加词语的词性、命名实体相关特征,或者采用更好的分词器。另一个思路是增加2gram、3gram特征。
所谓2gram、3gram就是把句子中相邻的2个、3个词语拼成一个大一点的词,当成一个整体进行统计,放入词表中。这样至少就能识别2个、3个词语之间的顺序关系。
深度学习进行文本分类
采用基于深度学习方法的文本分类技术主要包括卷积神经网络(CNN),循环神经网络(RNN),注意力机制(Attention)等。自2012年深度学习技术快速发展后,尤其CNN、RNN在NLP领域获得了广泛应用,使得文本分类的准确率不断提升。
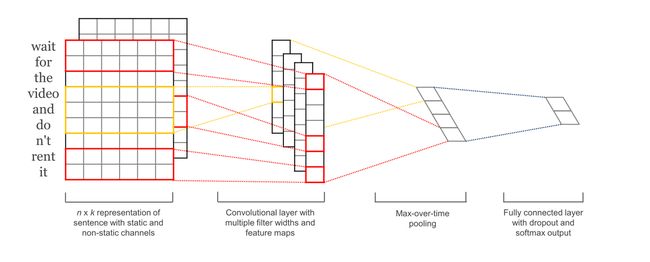
如下如显示了TextCNN的结构模型,将词向量经过卷积层、池化层、全连接层后,最终得出分类结果。
盘点评论:闹了笑话的评论都犯了哪些错
马蜂窝事件中关于评论的内容又有哪些可以分析的点呢?
模板评论
如下图,关于游记的回复内容每一条都出现了几千次,这样一个有固定模板的评论,通过词频统计发现。

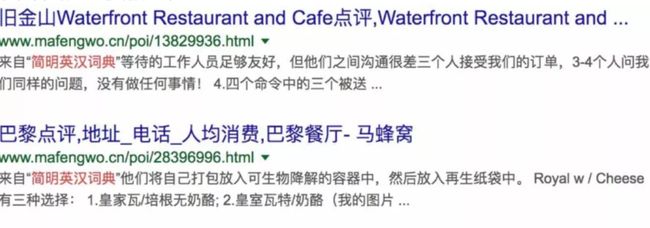
机翻关键词
如下图,可以很明显看到该条评论是来源于“简明英汉词典”,这一点的发现貌似只能结合词组统计和用肉眼看。
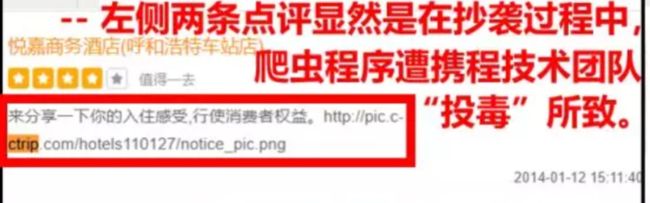
“投毒”
如下图,为在对方平台的评论处挂上自己网站的链接。这种情况的发现类似机翻关键词的寻找。
可见,传统的要找到这些典型的抄袭评论的证据,都需要用肉眼看。而为了提高效率,可以结合统计词频的方法。
但其实随着大数据技术的发展,我们可以用更多的可视化技术帮助人工去寻找作弊关键点。一个典型的方法是绘制词云。其实本质上也是统计词频,但是通过可视化技术可以讲词频较高的词语、短语放大标出。这样可以有个更加直观的认识,形成更加专业的分析报告。

鉴别洗稿
另一个很典型的作弊现象是发现了很多攻略是洗稿作品,有专门的营销目的。如下图显示了针对攻略的洗稿,将对方网站的攻略内容该改头换面到自己的网站下。图的右侧为将原文(左侧)标题和图片进行了篡改。

而鉴别洗稿NLP技术其实目前还是开放问题,因为这属于长文本的相似度判断。长文本相似与短文本相似最大的区别是长文本的信息量更加丰富,处理起来更加困难。如句子之间的顺序、段落间的谋篇布局、篇章整体的主题等等,都远比句子级别的信息更复杂。
这里提供一个简单的综合解决方案:
- 先在词语级别抽取信息:用基于统计的词袋子模型快速筛选一批相似攻略。这个方法的好处是速度快、召回率高,但准确率低。这在面对海量文章进行判断时比较有用,把绝大部分明显不是抄袭的攻略都过滤掉。
- 再在句子级别抽取信息:采用字符串匹配判断是否存在数个以上的句子完全相同。这是洗稿文章典型特征。而这种方法准确率高,但召回率低。而且特别容易被洗稿团队绕过。
- 这之后可以把中间地带的文本拆成句子用深度学习筛选一遍,捞一批漏网之鱼
- 另外,也可以参考篇章级别抽取信息。这里涉及到的NLP技术包括情感倾向分析与主题模型。
- 最后再用人工校验,分析badcase,进一步优化策略……
主题模型:篇章信息的提取利器
这里着重提一下主题模型,它是一种根据文本抽取其主题相关的信息技术,其核心算法是概率图生成模型,典型的算法是LDA。虽然现在深度学习这么火,但还有一种算法分析框架在NLP领域非常重要,就是**概率图模型。概率图的重要一类是有向图,其基本思路就是将问题抽象出不同的状态,状态之间存在符合一定分布的转移概率。概率图的目的就是求出关键的转移概率来分析问题。**下图就是LDA算法的概率图。
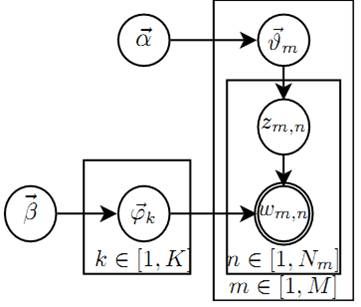
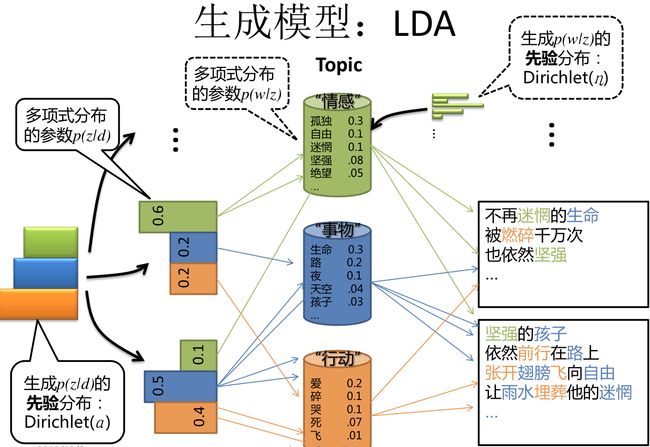
好吧,这个图太抽象了,想要解释清楚会比较复杂。这里用一个简单的例子说明一下。比如我们想抽取汪峰的每首歌词的三个主题信息的分布,我们姑且将它们命名为“情感、实物、行动”(严格来说LDA只能找出三个主题的分布,并知道这三个主题是什么意思,本质上是一种软性聚类)。
不同的歌词的主题分布是不一样的,比如有些歌是“情感”相关的主题比例更多一些,有些歌是“行动”相关的主题更多。主题模型的目的就是得到任何一篇歌词的主题分布,提取其篇章层面信息。
而LDA的基本假设是存在一个先验分布(狄利克雷分布)其能够产生各首歌的主题分布(多项分布)。而每个主题又能够产生该主题下的每个词语的分布(多项式分布)。最终得到每个歌词里所有词的分布。这个假设比较符合人们对于主题的概率意义理解,符合文本词语是离散分布的特点。因此LDA在实际的应用中效果也比较好。
打开NLP世界的大门
到此为止,我们基本介绍完了马蜂窝事件中的NLP技术。如果大家想更深入地学习NLP,可以参考以下推荐课程和NLP相关api。
推荐课程
a)网易云课堂的课程
https://mooc.study.163.com/smartSpec/detail/1001477005.htm
b)牛津大学与deepmind联合办的课程
https://study.163.com/course/courseMain.htm?courseId=1004336028&share=2&shareId=10146755
c)斯坦福大学NLP课程
NLP应用api
百度AI开放平台
http://ai.baidu.com/tech/nlp/
腾讯文智自然语言处理
https://cloud.tencent.com/product/nlp
谷歌云自然语言
https://cloud.google.com/natural-language/
Microsoft Azure
https://azure.microsoft.com/zh-cn/services/cognitive-services/text-analytics/