数据挖掘算法和实践(六):seaborn数据可视化探索(tips 数据集)
seaborn是一个面向对象作图工具,直译是海洋生物,tips 是小费数据集(seaborn自带),本次使用seaborn学习数据分布的探索,在遇到新的数据集合时候,分析问题不至于无从下手;关于使用seaborn,参考官网 http://seaborn.pydata.org/index.html
python数据分析的可视化库有:
-
matplotlib 是可视化的必备技能库,比较底层,api很多,学起来不太容易。
-
seaborn 是建构于matplotlib基础上,能满足绝大多数可视化需求。
-
matplotlib和seabron是静态可视化库,pyecharts有很好的web兼容性,可以进行可视化动态效果。
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np一、数据读取
# 修改baseUrl的路径即可完成数据读取修改
baseUrl="C:\\Users\\71781\\Desktop\\2020\\ML-20200422\\seaborn_sklearn\\"
# tips=sns.load_dataset("tips")
tips=pd.read_csv("tips.csv")
# 如果想增加对特征属性的描述(单位或含义),可对数据进行重命名操作
tips.columns=("total_bill_dollar","tips_dollar","sex","smoker","day","time","size")
# 特征属性多的时候使用set_option方法可展示最多500个列;
pd.set_option("display.max_columns",500) #让所有列都能加载出来
# tips['day'].values
# tips['day'].value_counts
# tips['day'].shape
tips.head()
# 针对离散值,查看值域
np.unique(tips['time'])
# 针对整型特征属性describe查看常规统计
tips.describe()一、seaborn可视化
Seaborn装载了一些默认主题风格,通过sns.set()方法实现。sns.set()可以设置5种风格的图表背景:darkgrid, whitegrid, dark, white, ticks,通过参数style设置,默认情况下为darkgrid风格:
1、分布图(连续性变量):distplot()
# 1、分布图(连续性变量):distplot()
# 探究单个连续属性的分布图,使用distplot()方法,横坐标是数据,纵坐标是概率图;参照seaborn官网api:
# seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
# 被定义为灵活的绘制单变量分布图l
sns.distplot(tips["total_bill_dollar"])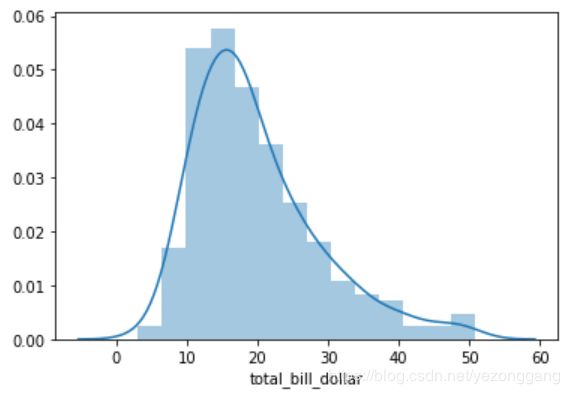
2、数量统计图(离散变量):countplot()
# 2、数量统计图(离散变量):countplot()
# 分布图一般是针对连续性的特征属性,当特征属性是离散的时使用countplot()方法查看特征属性值的个数统计量;
# seaborn.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
# 由于seaborn默认是图形竖着排列,不好观察,所以这里使用matplotlib和seaborn结合使得两个图横向排列,预先定义画布然后填充图形,非常实用!
fig,(axis1,axis2,axis3) = plt.subplots(1,3,figsize=(15,5))
sns.countplot(x='sex', data=tips, ax=axis1)
# countplot() 可以绘制两个离散值之间的统计关系图,能够直观观察问题
sns.countplot(x='sex', hue="time", data=tips, order=['Female','Male'], ax=axis2)
sns.countplot(x='time', hue="sex", data=tips, order=['Dinner','Lunch'], ax=axis3)
# 图2和图3描述了一个问题,女性偏爱吃午餐,男性偏爱吃晚餐;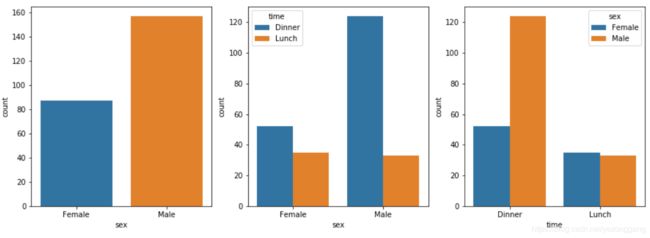
# countplot() 中x和y只能指定一个,指定x轴则y轴展示数量,指定y轴则x轴展示数量
fig,(axis1,axis2,axis3) = plt.subplots(1,3,figsize=(15,5))
sns.countplot(y='sex', data=tips, ax=axis1)
sns.countplot(y='sex', hue="time", data=tips, order=['Female','Male'], ax=axis2)
sns.countplot(y='time', hue="sex", data=tips, order=['Dinner','Lunch'], ax=axis3)
3、两个变量的散点图:scatterplot()
# 3、两个变量的散点图:scatterplot()
# scatterplot() 单纯只做散点图,但是能突出3个变量间的关系,一般把参数中的hue设置成分类结果,观察每一种分类的分布情况
# seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None, data=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=True, style_order=None, x_bins=None, y_bins=None, units=None, estimator=None, ci=95, n_boot=1000, alpha='auto', x_jitter=None, y_jitter=None, legend='brief', ax=None, **kwargs)
ax = sns.scatterplot(x="total_bill_dollar", y="tips_dollar", hue="day",size="smoker",data=tips)
# 下图中用不用颜色区分day,然后用不同大小区分了smoker,一个图装了4个变量之间的关系。。。
4、根据属性值域绘制散点图:relplot()
# 4、根据属性值域绘制散点图:relplot()
# relplot()根据不同特征属性值域绘制变量之间的散点图
# seaborn.relplot(x=None, y=None, hue=None, size=None, style=None, data=None, row=None, col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None, style_order=None, legend='brief', kind='scatter', height=5, aspect=1, facet_kws=None, **kwargs)
# 行按照time值域分类,列按照sex值域分类,总共是 2*2 =4个图,很容易发现女性喜欢周四中午吃午餐,男性喜欢周末吃晚餐;
sns.relplot(x="total_bill_dollar", y="tips_dollar", hue="day",col="time", row="sex", data=tips)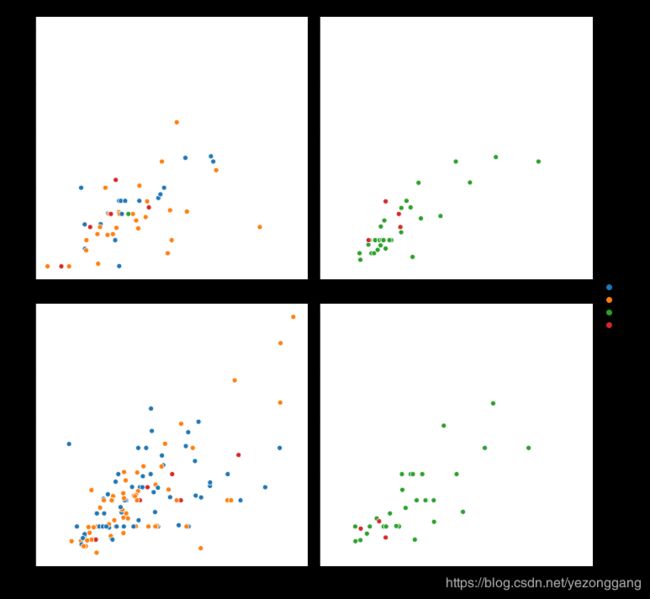
5、两个变量的联合分布图jointplot()
# 5、两个变量的联合分布图jointplot()
# 单个变量的分布探究完成后,可以做多个连续性变量之间的联合分布散点图,使用jointplot()函数,在x和y轴绘制分布图,在中心绘制散点图;
# seaborn.jointplot(x, y, data=None, kind='scatter', stat_func=None, color=None, height=6, ratio=5, space=0.2, dropna=True, xlim=None, ylim=None, joint_kws=None, marginal_kws=None, annot_kws=None, **kwargs)
sns.jointplot(x="total_bill_dollar", y="tips_dollar", data=tips, color="black")
# jointplot() 既可以看到单个变量的分布,又可以查看两者之间的关系,kind='kde'得到密度图,kind='reg'得到回归线;
sns.jointplot(x="total_bill_dollar", y="tips_dollar", data=tips,kind='reg',color="red")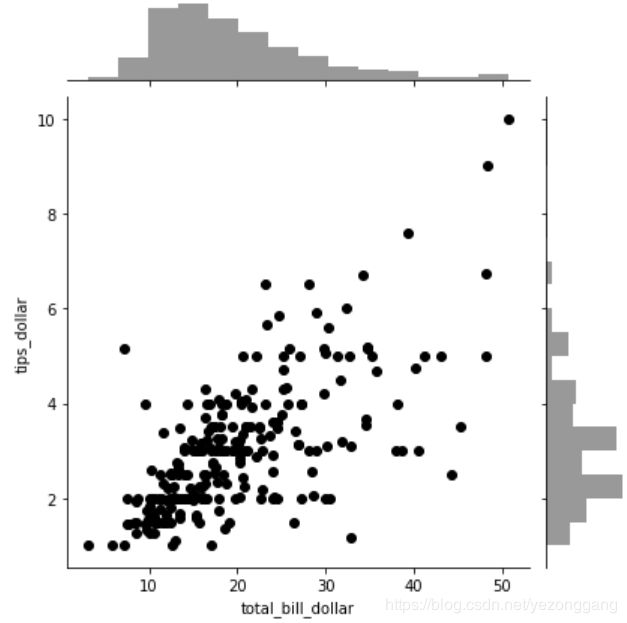

6、箱线图:boxplot()
# 6、箱线图:boxplot()
# boxplot可以直观明了地识别数据批中的异常值,也可以判断数据批的偏态和尾重,发现有一些异常点;
ax1=sns.boxplot(x="day", y="total_bill_dollar",hue="smoker", data=tips)
7、不重叠散点图:swarmplot()
# 7、不重叠散点图:swarmplot()
ax1=sns.swarmplot(x="day", y="total_bill_dollar",hue="smoker", data=tips)
8、有个变量属性的重叠散点图:stripplot()
# 8、有个变量属性的重叠散点图:stripplot()
ax = sns.stripplot(x="day", y="total_bill_dollar", hue="smoker",data=tips)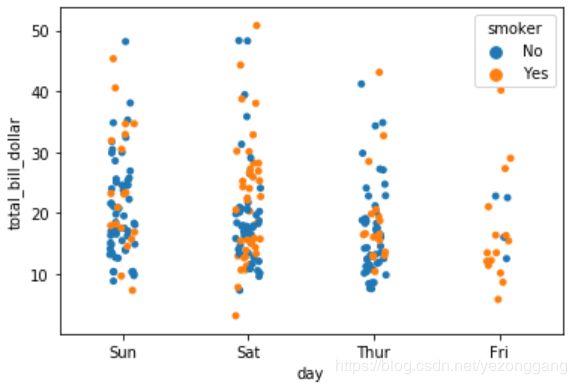
# 一般swarmplot(),stripplot() 同boxplot()和violinplot()一同使用,既可以观察总体分布,也能看个体分布情况
ax1=sns.boxplot(x="day", y="total_bill_dollar", data=tips)
ax1 = sns.swarmplot(x="day", y="total_bill_dollar", data=tips)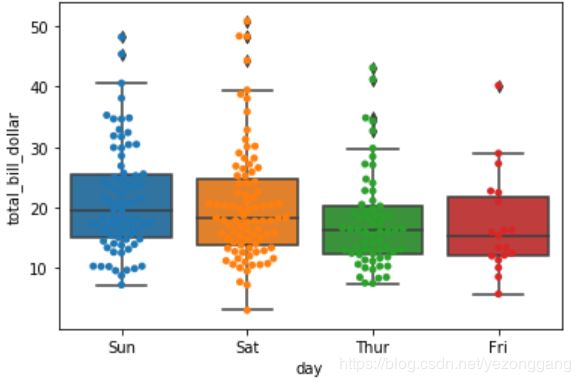
9、小提琴图跟boxplot()用途一样
# 9、小提琴图跟boxplot()用途一样
ax1 = sns.violinplot(x="day", y="total_bill_dollar", hue="smoker",data=tips)
ax1 = sns.stripplot(x="day", y="total_bill_dollar", hue="smoker",data=tips)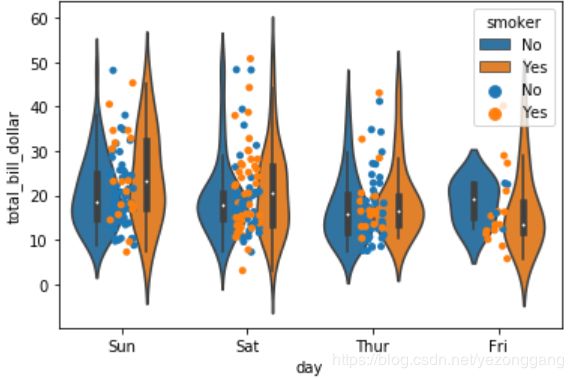
10、绘制条件关系的多图网格:FacetGrid()
# 10、绘制条件关系的多图网格:FacetGrid()
g = sns.FacetGrid(tips, col="time", row="smoker")
g = g.map(plt.hist, "total_bill_dollar")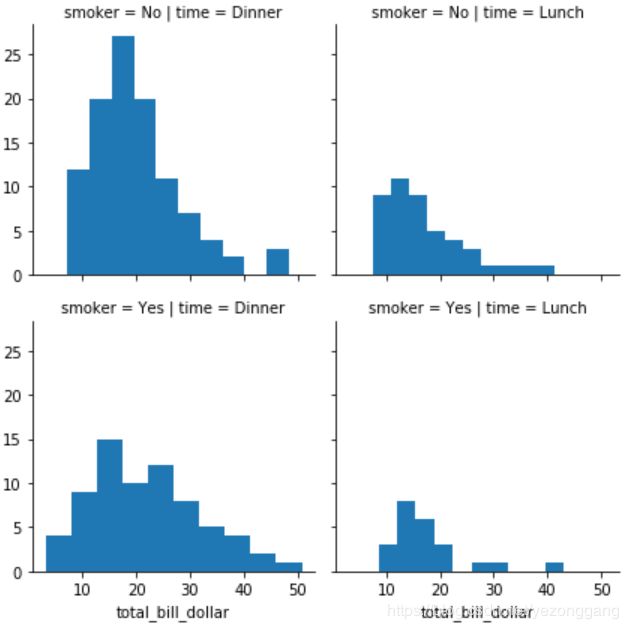
# 比较随性的绘图方法,很灵活
g = sns.FacetGrid(tips, col="time", row="sex")
g = g.map(plt.scatter, "total_bill_dollar", "tips_dollar", edgecolor="w")11、barplot()函数
若输出的值域是离散值,我们可以将其转换成1/0的连续性,然后看特征属性的贡献度;
# 11、barplot()函数,直观绘制曲线图
# 若输出值域是离散值,我们可以将其转换成1/0
# 这里值域是个连续性的,所以我们把sex转换为1和0,探究一下
tips['sex'].replace('Female',0,inplace=True)
tips['sex'].replace('Male',1,inplace=True)
tips.head()
# 求均值
perc=tips[['day','sex','time']].groupby(['day','time'],as_index=False).mean()
sns.barplot(x='time',y='sex',hue='day',data=perc)
一般掌握以上的绘图方法就能够确保够用,主要是熟能生巧,能够快速找到数据之间的关系,快速发现数据价值;