Tensorflow快速入门1--实现K-Means聚类算法
Tensorflow快速入门1–实现K-Means聚类算法
环境:
虚拟机ubuntun16.0.4
Tensorflow版本:0.12.0(仅使用cpu下,pip命令安装)
目录
1.环境搭建
1.1Tensorflow的安装
1.2简单测试Tensorflow
1.3Tensorflow学习文档
1.4Python相关的库Seaborn、pandas安装
2.TensorFlow实现K-Means聚类算法
2.1最基本的K-Means聚类算法步骤
2.2TensorFlow实现K-Means聚类算法
2.3测试数据准备
2.4完整的kmeans.py文件
2.5简单测试结果
1.环境搭建
1.1Tensorflow的安装
这里通过pip安装(只安装cpu单机版的,有条件的可以安装gpu下的)。
yhh@ubuntu:~$ sudo apt-get install python-pip python-dev
yhh@ubuntu:~$ sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0-cp27-none-linux_x86_64.whl注意:如果pip安装Tensorflow时失败,可尝试上述命令重新安装。再次安装则成功。
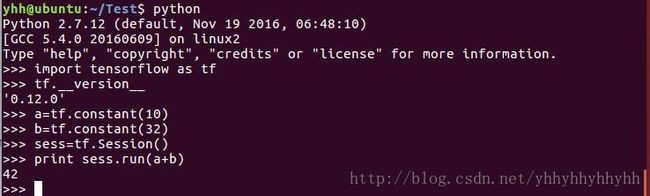
1.2简单测试Tensorflow
按照下述简单测试Tensorflow安装成功。
yhh@ubuntu:~/Test$ python
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>> tf.__version__
'0.12.0'
>>> a=tf.constant(10)
>>> b=tf.constant(32)
>>> sess=tf.Session()
>>> print sess.run(a+b)
42
>>>
1.3Tensorflow学习文档
Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow使用基础数据结构—tensor来表示所有数据。一个tensor可以看成是一个拥用静态数据类型动态大小且多维的数组,它可以从布尔或string转换成数值类型。
Tensorflow的具体细节及框架可在Tensorflow中文社区学习,上面内容非常详细:
http://www.tensorfly.cn/tfdoc/get_started/introduction.html
Tensorflow源码下载:
https://github.com/tensorflow/tensorflow
1.4Python相关的库Seaborn、pandas安装
Tensorflow支持多种前端语言,但对Python的支持是最好的,因此开发大多基于Python。在python编程中,计算及画图需要用到一些包,主要有matplotlib、Seaborn、NumPy、pandas等。这里安装Seaborn(其实也是基于matplotlib的,用起来更方便简洁),数据用库pandas,画图时用起来更方便简洁(NumPy也一样,画图时稍微麻烦)。
Ubuntun下自带的有python。这里建议以下四个都安装一下。
安装Seaborn:sudo pip install seaborn
安装pandas:sudo pip install pandas
安装numpy:sudo pip install numpy
安装matplotlib:sudo pip install matplotlib
由于后续开发中需要利用python计算等等,所以这里可以把numpy和matplotlib也都安装上。
当然也可以使用apt-get安装,安装不成功时上网搜搜解决方法,这个应该很简单的。
2.TensorFlow实现K-Means聚类算法
2.1最基本的K-Means聚类算法步骤

上述是最基本的k-menas算法,各种改进自行查找资料及文档。
2.2TensorFlow实现K-Means聚类算法
这里使用Sachin Joglekar基于tensorflow写的一个kmeans模板,见Sachin Jogleka的原文
2.3测试数据准备
注意:测试数据是随机生成的数据,每次运行结果会不一样
############生成测试数据###############
sampleNo = 1000;#数据数量
mu =3
# 二维正态分布
mu = np.array([[1, 5]])
Sigma = np.array([[1, 0.5], [1.5, 3]])
R = cholesky(Sigma)
srcdata= np.dot(np.random.randn(sampleNo, 2), R) + mu
plt.plot(srcdata[:,0],srcdata[:,1],'bo')注意:单独运行上述代码需要导入包:
# -*- coding: utf-8 -*-
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt2.4完整的kmeans.py文件
kmeans.py,可以在终端中直接使用:
python+kmeans.py路径+kmeans.py运行
# -*- coding: utf-8 -*-
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import tensorflow as tf
from random import choice, shuffle
from numpy import array
############Sachin Joglekar的基于tensorflow写的一个kmeans模板###############
def KMeansCluster(vectors, noofclusters):
"""
K-Means Clustering using TensorFlow.
`vertors`应该是一个n*k的二维的NumPy的数组,其中n代表着K维向量的数目
'noofclusters' 代表了待分的集群的数目,是一个整型值
"""
noofclusters = int(noofclusters)
assert noofclusters < len(vectors)
#找出每个向量的维度
dim = len(vectors[0])
#辅助随机地从可得的向量中选取中心点
vector_indices = list(range(len(vectors)))
shuffle(vector_indices)
#计算图
#我们创建了一个默认的计算流的图用于整个算法中,这样就保证了当函数被多次调用 #时,默认的图并不会被从上一次调用时留下的未使用的OPS或者Variables挤满
graph = tf.Graph()
with graph.as_default():
#计算的会话
sess = tf.Session()
##构建基本的计算的元素
##首先我们需要保证每个中心点都会存在一个Variable矩阵
##从现有的点集合中抽取出一部分作为默认的中心点
centroids = [tf.Variable((vectors[vector_indices[i]]))
for i in range(noofclusters)]
##创建一个placeholder用于存放各个中心点可能的分类的情况
centroid_value = tf.placeholder("float64", [dim])
cent_assigns = []
for centroid in centroids:
cent_assigns.append(tf.assign(centroid, centroid_value))
##对于每个独立向量的分属的类别设置为默认值0
assignments = [tf.Variable(0) for i in range(len(vectors))]
##这些节点在后续的操作中会被分配到合适的值
assignment_value = tf.placeholder("int32")
cluster_assigns = []
for assignment in assignments:
cluster_assigns.append(tf.assign(assignment,
assignment_value))
##下面创建用于计算平均值的操作节点
#输入的placeholder
mean_input = tf.placeholder("float", [None, dim])
#节点/OP接受输入,并且计算0维度的平均值,譬如输入的向量列表
mean_op = tf.reduce_mean(mean_input, 0)
##用于计算欧几里得距离的节点
v1 = tf.placeholder("float", [dim])
v2 = tf.placeholder("float", [dim])
euclid_dist = tf.sqrt(tf.reduce_sum(tf.pow(tf.sub(
v1, v2), 2)))
##这个OP会决定应该将向量归属到哪个节点
##基于向量到中心点的欧几里得距离
#Placeholder for input
centroid_distances = tf.placeholder("float", [noofclusters])
cluster_assignment = tf.argmin(centroid_distances, 0)
##初始化所有的状态值
##这会帮助初始化图中定义的所有Variables。Variable-initializer应该定
##义在所有的Variables被构造之后,这样所有的Variables才会被纳入初始化
init_op = tf.global_variables_initializer()
#初始化所有的变量
sess.run(init_op)
##集群遍历
#接下来在K-Means聚类迭代中使用最大期望算法。为了简单起见,只让它执行固
#定的次数,而不设置一个终止条件
noofiterations = 20
for iteration_n in range(noofiterations):
##期望步骤
##基于上次迭代后算出的中心点的未知
##the _expected_ centroid assignments.
#首先遍历所有的向量
for vector_n in range(len(vectors)):
vect = vectors[vector_n]
#计算给定向量与分配的中心节点之间的欧几里得距离
distances = [sess.run(euclid_dist, feed_dict={
v1: vect, v2: sess.run(centroid)})
for centroid in centroids]
#下面可以使用集群分配操作,将上述的距离当做输入
assignment = sess.run(cluster_assignment, feed_dict = {
centroid_distances: distances})
#接下来为每个向量分配合适的值
sess.run(cluster_assigns[vector_n], feed_dict={
assignment_value: assignment})
##最大化的步骤
#基于上述的期望步骤,计算每个新的中心点的距离从而使集群内的平方和最小
for cluster_n in range(noofclusters):
#收集所有分配给该集群的向量
assigned_vects = [vectors[i] for i in range(len(vectors))
if sess.run(assignments[i]) == cluster_n]
#计算新的集群中心点
new_location = sess.run(mean_op, feed_dict={
mean_input: array(assigned_vects)})
#为每个向量分配合适的中心点
sess.run(cent_assigns[cluster_n], feed_dict={
centroid_value: new_location})
#返回中心节点和分组
centroids = sess.run(centroids)
assignments = sess.run(assignments)
return centroids, assignments
############生成测试数据###############
sampleNo = 10;#数据数量
mu =3
# 二维正态分布
mu = np.array([[1, 5]])
Sigma = np.array([[1, 0.5], [1.5, 3]])
R = cholesky(Sigma)
srcdata= np.dot(np.random.randn(sampleNo, 2), R) + mu
plt.plot(srcdata[:,0],srcdata[:,1],'bo')
############kmeans算法计算###############
k=4
center,result=KMeansCluster(srcdata,k)
print center
############利用seaborn画图###############
res={"x":[],"y":[],"kmeans_res":[]}
for i in xrange(len(result)):
res["x"].append(srcdata[i][0])
res["y"].append(srcdata[i][1])
res["kmeans_res"].append(result[i])
pd_res=pd.DataFrame(res)
sns.lmplot("x","y",data=pd_res,fit_reg=False,size=5,hue="kmeans_res")
plt.show()2.5简单测试结果
在测试时把最大迭代次数设为了20。
运行代码:python ~/Test/kmeans.py(注意python文件路径)
1)sampleNo = 100
聚类中心:

聚类结果:
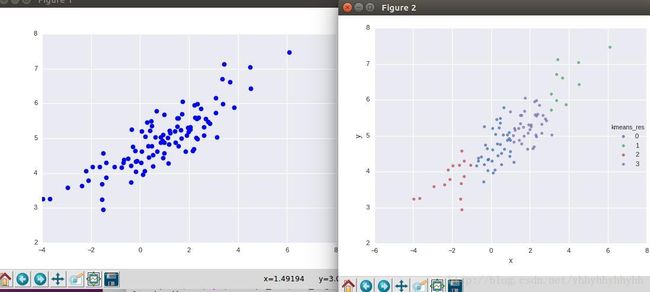
2)sampleNo = 1000
聚类中心:

聚类结果:
