中文情感分析之TextCNN
中文情感分析之TextCNN
- 综述
- 情感分析方法
- 基于情感词典的情感分析
- 基于机器学习算法的情感分析
- 文本分类模型TextCNN
- 中文情感分析实践
- 数据预处理
- 文本数值化
- 模型构建
- 结果分析
- 总结
最近接了个业务需求,需要对论坛发帖进行情感分析,以便于对恶意发帖的行为进行审核治理。在此对情感分析方法进行一个总结,并重点介绍下文本分类基准模型TextCNN在中文情感分析中的实践应用。
综述
情感分析(Sentiment Analysis)是自然语言处理领域的一个重要的研究方向。它的目的是挖掘文本要表达的情感观点,对文本按情感倾向进行分类。
情感分析在工业领域有着广泛的应用场景。例如,电商网站根据商品评论数据提取评论标签,调整评论显示顺序;影评网站根据电影评论来评估电影口碑,预测电影是否卖座;外卖网站根据菜品口味、送达时间、菜品丰富度等用户情感指数来改进外卖服务等。

情感分析方法
情感分析方法可以分为两大类:一是基于情感词典的方法,一是基于机器学习算法的方法。
基于情感词典的情感分析
基于情感词典的方法属于传统的情感分析方法,是对人的记忆和判断思维的最简单的模拟。直观来讲,它先通过学习来记忆一些基本词汇,从而在大脑中形成一个包含积极词汇、消极词汇、否定词、程度副词的情感词典。对输入的句子进行情感分析时,首先对句子进行分词,然后获取各个词在情感词典中的情感打分,最后将所有词的情感打分加起来得到句子的情感分。
基于上述思路,基于情感词典的方法的处理流程为:先对文本进行分词、去停用词等预处理,再利用预先构建好的情感词典,对文本进行字符串匹配,从而提取出文本所要表达的正面或负面信息。具体流程如下图所示。

从中可以看出,情感词典在整个情感分析过程中处于至关重要的地位,而要构建一个情感词典又是一项耗费精力的工作。目前的做法一般是采用开源的情感词典,如BosonNLP情感词典,它是从微博、新闻、论坛等数据来源的上百万篇情感标注数据中构建的情感极性词典。
基于情感词典的情感分析方法思路简单,可解释性强,通用性也比较好。但是该方法的不足之处是:
- 精度不高。语言是一个高度复杂的东西,采用简单的线性叠加会造成很大的精度损失。词语权重同样不是一成不变的,而且也难以做到准确。
- 新词发现困难。对于新的情感词,词典不一定能覆盖到。如“陈独秀同学请坐下”,“同九义,何汝秀”等。
- 词典构建难。情感词典的构建需要有较强的背景知识,需要对语言有较深刻的理解,构建一个适用于自己的应用场景的情感词典是一项复杂的工作。
因此,在进行情感分析时,我们更倾向于考虑使用具有精度高,通用性强,不需要情感词典的机器学习方法。
基于机器学习算法的情感分析
情感分析按不同的应用场景对应于不同类型的机器学习算法,如果要判断是正面还是负面,那就是机器学习中的二分类问题,如果要给商品评论打上标签就对应于机器学习中的多标签分类问题。由于多标签问题可以转化为二分类问题,因此本文仅讨论更基础的二分类问题。常见的用于分类的机器学习算法有朴素贝叶斯、逻辑回归、支持向量机、神经网络等。
近年来,随着深度学习技术的兴起,它的应用领域从最初的计算机视觉迅速扩展到语音识别和自然语言处理领域,并在各个领域都取得了突破性的进展。深度学习算法在多个算法竞赛中取得了state-of-the-art(当前最高水平),尤其是在大规模数据处理任务中,深度学习算法取得的性能优势相对于传统的特征+模型的机器学习方法大有碾压之势。因此本文重点介绍深度学习模型TextCNN在大规模文本分类任务上的应用,对于传统的机器学习方法的应用或小文本分类问题的处理过程在此不再赘述。
文本分类模型TextCNN
TextCNN模型由Yoon Kim在其2014年的论文Convolutional Neural Networks for Sentence Classification中提出。在该论文中,作者开创性地将源于计算机视觉领域的卷积神经网络CNN应用于NLP的文本分类任务中,提出了TextCNN模型,该模型在与多个benchmark方法的对比中取得了最好的结果,成为文本分类任务的重要baseline之一。
TextCNN模型的结构比较简单,由输入表征 --> 卷积层 --> 最大池化 --> 全连接层 --> 输出softmax组成, 如图所示。

- 由于CNN的输入要求是固定尺寸的(全连接层的限制),因此输入文本需要转换为n × \times × k 的矩阵形式。而且,由于计算机无法直接处理文字,因此需要对文本进行数值化,将文本信息映射到数值化的语义空间中,即常说的词向量空间。文本的数值化方法有很多种,如TF-IDF、BOW、One-Hot、word2vec、GloVe等。其中word2vec和glove属于分布式的表示方法,word2vec是业界使用最广泛的词向量工具,由word2vec训练得到的词向量,可以很好地度量词与词之间的相似性。TextCNN模型就是使用预训练的词向量作为CNN的输入。
- 在计算机视觉领域,CNN的输入是二维的图像数据,因此在卷积层进行的是二维卷积运算。而文本数据是只有一个维度的时间序列,因此只能将文本当作一维图像,在卷积层使用一维卷积运算来捕捉临近词之间的关联关系。TextCNN中的卷积层采用一维卷积操作(虽然文本经过词向量表达后是二维数据,但是在词向量维度上的二维卷积是没有意义的),一维卷积带来的问题是需要通过设计不同kernel_size的卷积滤波器来获取不同宽度的感受野。
- TextCNN中使用的池化方法是时序最大池化(Max-over-time pooling)。它实际上就是一维的全局最大池化,即对于多通道输入,各通道的输出是所有时间步中最大的数值。使用时序最大池化还有个优势是,它可以提取时序数据中最重要的特征,使得模型不受人为添加字符的影响(在构建词向量时对于较短的句子通常使用0向量补全,使用最大池化可以过滤掉这些补0的数据)。
- 数据经过池化处理后,作为输入送入全连接层,全连接层起到将学到的特征表示映射到样本标记空间的作用。在实际应用中为了防止过拟合,通常在全连接层加dropout来提升模型的泛化能力。
- 全连接层的输出是0到1之间的概率值,要解决分类问题需要使用softmax函数来将这些概率转化为离散的0或1类标。
中文情感分析实践
数据和特征决定了机器学习的上限,而模型和算法只是为了逼近这个上限而已。
分类问题属于有监督机器学习问题,因此需要提前准备一些标注数据。本文使用的情感分析数据是从携程和京东爬取的商品评论中文情感分析语料库,包含酒店、服装、水果、平板、洗发水等5个领域的评价数据,每个领域各包含5000条正面和负面评价。我们将这5个领域的数据合并起来,获得了一个包含25000条正面评论和25000条负面评论的数据集。
数据预处理
在机器学习任务中,数据的质量对模型的最终性能起着决定性的作用。为了训练一个好的模型,需要先对数据进行预处理,以剔除无意义或冗余的信息。例如,爬虫数据中的html标签、特殊符号等。
不同于自带空格的英文文本,中文文本在预处理阶段需要进行分词处理,将一段连续的文本序列切分为词/字序列。中文分词的工具有很多,在此我们使用常用的jieba分词工具进行中文分词。
在文本预处理中,我们还需要将出现频率很高但是自身又没有明确意义的词剔除。这类词语即所谓的停用词(Stop Words),主要包括语气助词、副词、介词、连接词、标点符号、数学字符等(如‘的’,‘啊’,‘总之’,‘综上所述’…)。目前,有一些公开的中文停用词表,可根据自己的具体应用选择合适的停用词表进行去停用词操作。
在机器学习任务中,另一个经常被忽略但是又非常重要的问题是数据不均衡问题,即数据集中存在某个或某些类下的样本数远大于另一些类别下的样本数目。该问题在实际生活中也比较常见,如正面评论的数据量往往远大于负面评论的数据量。这个‘远大于’通常以10:1作为判断标准,假如正负样本数量的比例超过10:1,那么就需要采取应对措施了。当不均衡问题比较严重时,训练出来的模型可能会把所有样本都分为样本数较大的类别,这样的模型虽然训练精度也挺高,但是对于实际应用是没有价值的。解决不均衡问题可以从两方面进行考虑,一是从数据集入手,通过重采样改变训练样本分布,如对小样本进行上采样或对大类样本进行下采样;二是从机器学习算法角度进行改良,如分类器集成、代价敏感方法即提高小样本的错分代价降低大样本的错分代价、特征选择方法等。
本文所使用的中文情感分析语料库正负样本比为1:1,因此不用考虑不均衡问题,只进行分词和停用词操作即可。
文本数值化
经过预处理,我们将最初的一个句子转换为由多个词语组成的词语序列。然而,这些词语序列对于我们的机器学习模型来说仍然是无法处理的,计算机只能处理数值运算,并不认识这些文本符号,因此还需要将这些文本数值化。
由于训练集数据量并不大,因此考虑使用预训练的中文词向量来将文本映射到对应的词向量空间。本文使用的是由北京师范大学中文信息处理研究所与中国人民大学DBIIR实验室开源的中文词向量语料库,使用其在微博语料上训练的词向量(531M)。腾讯AI实验室也开源了一个中文词向量语料库,据说是目前质量最好的中文词向量语料库,但是解压后大约有16G,还是放弃了,有条件的可以一试。
原数据预处理后得到的词语序列长度不同,对于长度不够的词语序列用0向量补全,如果当前词没有对应词向量,则用随机数产生的向量替代。
模型构建

整个模型的处理流程如果所示,为了能够让无机器学习相关知识背景的同学也能清楚每一步具体在做什么,我们以一个例子来进行说明。
-
我们从某电商网站中拿到了50000条评论数据,这些数据中好评和差评数据各占25000条,其中的一条好评数据是“质量好,做工也不错,而且尺码标准。”。拿到这些数据后,我们进行的第一步处理是数据预处理过程,即对这50000条数据中的每一条进行分词、去停用词操作。分词故名思义就是将句子切分成词语,分词后得到“质量 好 , 做工 也 不错 , 而且 尺码 标准”。去停用词是去掉无意义的词语或符号,如‘也’、‘而且’、标点符号等起连接作用的词,去停用词后得到“质量 好 做工 不错 尺码 标准”。经过预处理过程后我们就把原来的中文句子,转化为这样的词语组合,原来的每条句子变成了由多个词组成的词组。
-
将句子拆成词组之后,需要继续将其转化为方便计算机处理的数字,最直观的想法就是给每个词分一个编号,以编号来代替词语。这个想法是可行的,然而我们也没必要对所有词语进行编号,因为这之间肯定有很多词语只是偶尔出现了一次。所以我们考虑对出现的所有词语进行统计分析,看下各个词语出现的概率,然后取出现概率最高的前n个词语对其进行编号,将词语映射为id。构建了这样一个映射关系后,就可以将各个词组转换为数字列表。“质量 好 做工 不错 尺码 标准”就变成了
[15, 20, 210, 3, 337, 241],也就是说“质量”这个词语的编号就是15。这里有个问题,我们在编号过程中丢掉了一些低频词,那这些词要怎么转为数字呢?先不做处理,给他个特殊标记,如。 -
至此,词组转成了数字列表,但是由于原句子长短不一,转换后的数字列表也长短不齐,由于后续模型的输入需要固定尺寸,因此还需要对数字列表进行补全/截断操作。假设要将数字列表的长度都变为10,补全后得到
[15, 20, 210, 3, 337, 241, 0, 0, 0, 0]。 -
将词语转为数字后,我们就可以来构建TextCNN模型了,模型的第一层是Embedding层,这一层的作用是将词语转换为词向量(word embedding)。我们所拥有的数据量并不大,所以考虑使用预训练好的词向量来进行模型训练。构建Embedding层需要使用之前将词语转数值时的词语和id的映射关系,假设word_index表示word–>id的映射,那么embedding矩阵即为id–>embedding_vector的映射,也就是说embedding矩阵是一个词向量列表,它的第i个元素表示原word_index中id为i的词对应的词向量。绕了一圈,做的工作其实就是将单词转为了词向量,只不过因为模型输入需要是数字所以多做了词语到数值,数值到词向量的转换。如果觉得比较绕,可以简单的将Embedding层理解为将词语转为词向量。(对于之前的标记,由于它不在词向量矩阵中,所以经过该层后以0向量填充,相当于将低频词都映射为0向量了)
-
假设输入样本长度为10,词向量维度为300,经过Embedding层后,输出为 10 × 300 10 \times 300 10×300的词向量矩阵。至此,我们已经成功地将中文文本转化为规整的 m × n m \times n m×n矩阵,这样的数据可以作为各种机器学习模型的输入。
-
在TextCNN模型中,数据经过Embedding层转换后送入卷积层,这里卷积使用一维卷积,这是因为虽然Embedding层输出是一个二维矩阵,但是在词向量维度上的卷积运算是无意义的,因此只进行时间维度上的卷积运算来获取相邻词之间的关系。一维卷积带来的一个问题是,需要设计不同尺寸的滤波器核来捕获不同尺度的信息。直观上看,中文词以2个或4个为一组的比较多,因此考虑使用滤波器核尺寸为2、4和5的三种滤波器进行卷积操作,每种滤波器使用128个。 10 × 300 10 \times 300 10×300的矩阵经过kernal_size为2,4,5的一维卷积操作后分别得到 9 × 128 9 \times 128 9×128、 7 × 128 7 \times 128 7×128和 6 × 12 6 \times 12 6×12。

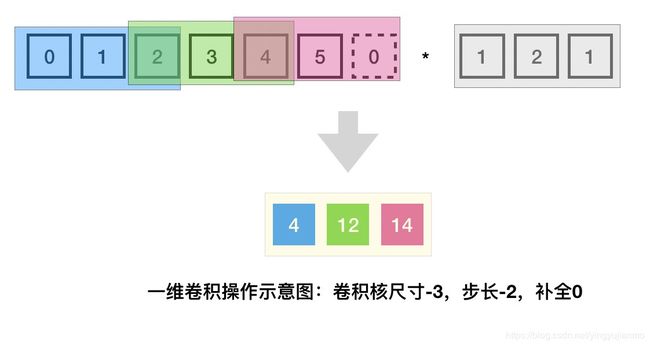
-
数据经过卷积层进行特征映射后,送入时序最大池化层,即一维全局最大池化,该层的主要作用是提取各滤波器输出的主要特征,过滤掉无效数据的影响。经过最大池化处理后,之前处理中的padding补全操作或者无映射关系标记为等处理的数据都会过滤掉。
-
经过时序最大池化处理后得到的是3组128维(滤波器个数)的向量,我们将这3组输出合并起来得到384维的向量数据,将其作为全连接层的输入。
-
全连接层使用一个有两个隐层的神经网络,每层的节点数设置为128,在两层隐层之间加入dropout层用于减轻过拟合。dropout层就是在每次训练过程中按概率随机丢弃一些参数,比如当丢弃率设置为0.5的时候,在每次训练过程中更新隐层权重的时候会以50%的概率对128个节点的权重进行更新,也就是说在每次训练回合中只更新其中的64个节点的参数。dropout层可以有效减轻模型的过拟合程度,使得模型具有较好的泛化性能。
在本次情感分析任务中,需要将样本分为正面评论或负面评论两种,是一个二分类问题。在二分类问题中,模型的输出可以有两种方式,一种是输出节点只有1个,以输出是0/1来判断分类结果的正负。另一种是输出节点有两个,[0,1]表示分类结果是第二类,[1,0]表示分类结果是第一类,这种方法可以方便的扩展到多类分类问题,比如要分为10个类别,那输出节点数就是10,在每次分类中只有1个节点值为1,表示分类结果是该节点代表的类别,其他9个节点的值都是0。如果一个样本可以同时分为多个类别,比如一篇文章同时是金融、社会、政治相关的,这样的任务就属于多标签分类了。
二分类、多分类、多标签分类三种分类任务本质上是相通的,区别在于所用的损失函数不同。当然,训练数据的类标是不同的。二分类常用binary_crossentropy损失函数,多分类使用categorical_crossentropy损失函数。另外,输出层使用的激活函数也不同,在多分类任务中使用softmax函数作为输出层的激活函数。在二分类或多标签分类任务中,使用sigmoid函数作为输出层的激活函数。
至此,我们从一个样本的角度从中文文本到分类结果输出,走完了整个分类流程。在实际训练的时候通常是分批训练的,即多个样本为一组进行训练。每批训练的样本数是一个超参数,需要根据具体任务进行调整,如果batch_size太小,每次训练的样本数太少不足以反应整个训练集的样本分布,会使得模型的训练发生抖动,收敛速度慢。增大batch_size,可以提高内存利用率,每次训练下降方向越准,引起的震荡越小。但盲目增大batch_size又会带来内存问题,而且一次训练速度过慢,不利于及时修正训练参数。
结果分析
数据分析和模型训练过程见代码:https://github.com/kiss90/textcnn-tf。
在20个回合训练过程中,模型在训练集和验证集上的精度变化如图所示。

从图中可以看出模型在训练集上的精度很快超过了90%,大约从第5个训练回合开始,模型的训练精度已经达到了98%,之后的训练回合中训练精度在该值附近波动。模型在验证集上的精度一直维持在90%左右。
这样初步训练的模型,能达到90%的精度已经是一个良好的开端了。如果所在的应用场景要求更高精度的分类模型,我们可以继续从多个方面对模型进行性能调优。比如,在本次训练中,我们固定了Embedding层的参数,使用预训练好的词向量来做模型训练。这样的词向量并不一定适合我们的情感分析使用场景,我们可以在训练几个回合后,对Embedding层的参数进行微调,使其更适用于我们的特定应用任务。这是从训练过程角度出发进行的改进考虑,也可以从数据和模型结构角度进行性能改进,例如可以考虑使用多通道CNN来学习更强大的特征表示或者构造更好的数据集或者对模型超参数进行调优等等。
总结
本文介绍了自然语言处理中情感分析任务的常用解决思路,以中文情感分析任务为载体,从数据分析、数据预处理、模型搭建、结果分析等角度对文本分类基准模型TextCNN的使用进行讲解,对机器学习任务处理的各个环节可能会遇到的问题进行了分析讨论,希望可以借此普及下机器学习解决实际问题的基本套路。