分支界定法 branch-and-bound 分析与实现
1. 介绍分支界定法之前需要了解一下广度优先搜索breadth-First-search(BFS)
宽度优先搜索算法(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
BFS,其英文全称是Breadth First Search。 BFS并不使用经验法则算法。从算法的观点,所有因为展开节点而得到的子节点都会被加进一个先进先出的队列中。一般的实验里,其邻居节点尚未被检验过的节点会被放置在一个被称为 open 的容器中(例如队列或是链表)list, vector或者是最优值的小根堆大根堆,而被检验过的节点则被放置在被称为 closed 的容器中。(open-closed表)
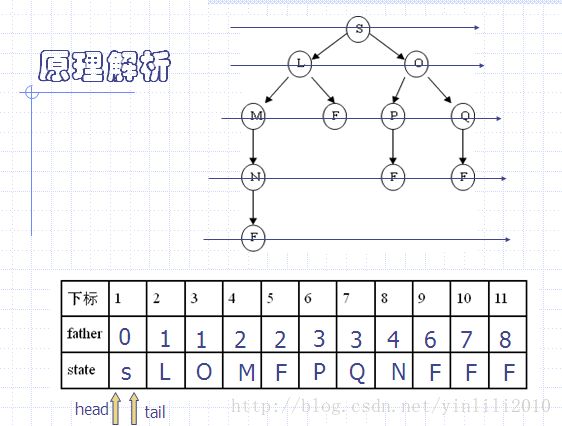
广度搜索的判断重复如果直接判断十分耗时,我们一般借助哈希表来优化时间复杂度。
分支界定法一般是广度优先搜索的优化
2. 分支界定法
分支界定算法是一种在问题的解空间树上搜索问题的解方法。一般如果有n层, 那么解空间树的叶节点有2 power n, 那么分支界定法就是使用限定条件,不断对这颗解空间树进行剪枝, 直到最后一层。
分支界定法采用广度优先或者最小耗费优先的方法搜索解空间树。 并且,在分解界定法中, 每一个活结点只有一次机会会成为扩展节点。他的搜索策略是:
1. 产生当前扩展节点的所有孩子节点, 并且在活结点链表中删除当前拓展节点;对于一般的求最优值和资源问题是二叉树, 对于求最短路径这样的图论问题, 是一般的树
2. 在产生的孩子节点中,剪掉那些不可能产生可行解(或最优解)的节点;(使用限定条件)
3.将其余所有的孩子节点加入活节点链表;
4.从活结点表中选择下一个活结点作为新的扩展节点;
5. 遇到层结束标记(采取不同的数据结构实现可能不同, 加入新的结束标记)
如此循环,直到找到问题的可行解(或最优解)或者活结点表为空。
分支界定法的思想是:首先确定目标值的上下界, 边搜索边减掉搜索树的某些枝, 提高搜索效率。
分支界定法在两个方面加速了算法的搜索效率, 一是在选择扩展节点时, 总是选择一个最小成本的节点, 尽可能早的进入最有可能成为最优解的分支;二是扩展节点的过程,舍弃导致不可行解或导致非最优解的子节点。
选择下一个扩展节点E-节点有如下方式

3. 使用C++实现FIFO的分支界定算法, 集装箱问题
现在有一个集装箱, 能装30的容量, 有分别为10, 15, 20的货物, 问如何能最大化集装箱的载重货物??
我们知道答案为30
下面使用C++实现改算法
#include
#include
using namespace std;
#define MAX 3
const int CAP=30;//最大容量
const int box[MAX]={10,15,20};//三个箱子
int main()
{
int temp=0,level=-1,best=0;
int curVal=0,parentVal=0,expectVal=0;
list queue;
queue.push_back(-1);//-1表示一层
queue.push_back(parentVal);
do
{
parentVal=queue.front(); //first in first out
queue.pop_front(); //按照FIFO取出第一个元素,并且删除
if(parentVal!=-1)
{
//left child
curVal=parentVal+box[level]; //提高效率的一方面
if(curVal>best&&curVal<=CAP)//边界条件 记录一个最大值 并且条件限定在CAP之内, 不满足条件的剪枝
{
best=curVal;
std::cout<<"bestvalue"<best&&level::iterator ite = queue.begin(); ite != queue.end(); ite++)
{
std::cout<<" "<<*ite;
}
}
else//处理层次问题,加入层结束标志,进入下一层
{
if(level
如果细分,上面的算法实际上是FIFO通过加入“限界”策略加速搜索。
4. FIFO实现分支搜索
w1+w2+……+wn≤c1+c2。
确定是否有一种可将所有n 个货箱全部装船的方法。若有的话,找出该方法。
1) 使用FIFO分支搜索实现算法
#include
#include
using namespace std;
int w[100];
int n;
int bestw=0;
queue queue1;//存储当前或节点
void AddLiveNode(int wt,int i)
{
if (i==n)//是叶子, 需要结束
{
if (wt>bestw)
bestw=wt;
}
else //不是叶子
{
queue1.push(wt);
}
}
int MaxLoading(int c)
{
// 初始化活结点队列,标记分层
queue1.push(-1);
int level=0;
int currentw=0;
while(!queue1.empty())
{
if(currentw!= -1)
{
if(currentw+w[level]<=c) //左节点,限定条件为current + wi < c1
{
AddLiveNode(currentw+w[level],level); //物品i可以装载
}
AddLiveNode(currentw,level); //右孩子总是可行的,不装载物品i
//取下一个E-结点
currentw = queue1.front();
queue1.pop();
cout<<"current"<c1+c2)
{
cout<<"no solution"<
5. 优先队列构造最优解
数据结构设计:
1)要输出解的方案,在搜索过程中仍需要生成解结构树,其结点信息包括指向父结点的指针和标识物品取舍(或是父结点的左、右孩子)。 (左节点1, 右节点0)
2)堆结点包括结点优先级信息:结点所在分支的装载上界uweight;堆中无法体现结点的层次信息(level),只能存储在结点中;
AddLiveNode用于把活结点加到子树中,并把HeapNode类型的活结点插入最大堆。
3)不同于算法2,由于扩展结点不是按层进行的,计算结点所在分支的装载上界时(expectVal>best),要用数组变量r记录当前层以下的最大重量,这样可随时方便使用各层结点的装载上界。
6. 算法复杂度
不管如何算法的复杂度仍为O(2n),但通过限界策略,并没有搜索子集树中的所有结点,且由于每次都是选取最接近最优解的结点扩展,所以一旦搜索到叶结点作E结点时算法就可结束。算法结束时堆并不一定为空。