还在用json和xml传消息?谷歌喊你换protocol buffer了
网络程序交互时,两端需要交互一些消息,不同的开发者会制定不同的消息报文格式,大多可能是json,xml,但已经不够快不够省流量了。另一种解决方案:protocol buffer,了解下。
一、网络程序交互的消息封装类型
文本类消息
例如我们在浏览器里访问网页说用的HTTP协议,就是文本消息。

目前非常流行的json消息格式:
{
"people":[
{
"firstName":"Brett",
"lastName":"McLaughlin"
},
{
"firstName":"Jason",
"lastName":"Hunter"
}
]
}
xml消息格式:
<peoples>
<people>
<firstName>BrettfirstName>
<lastName>McLaughlinlastName>
people>
<people>
<firstName>JasonfirstName>
<lastName>HunterlastName>
people>
peoples>
优点
- 具有自解释功能,人可看懂
- 扩展起来方便
缺点
-
消息解析效率低 (基于字符串的操作)
-
消息体积大,消耗流量多
二进制消息
例如IP协议说用到的报文格式的定义就是二进制类型的。

一个TCP的SYN消息以16进制显示就长这样:

优点
- 体积小,节省流量
- 解析快
缺点
- 人类不可读
- 不易扩展
二、关于消息格式的制定,开发者面临的问题
由于文本类消息好看又好扩展,目前大多数开发者都采用文本类消息,二进制消息在一些消息格式变化几率小的场合使用。随着移动互联网的出现,应用对服务器的请求越来越多,压缩消息体积,加快消息解析的需求就迫在眉睫了。
HTTP2协议就是一个例子,它将HTTP1.x协议中的文本改成了二进制的,像下面这样:
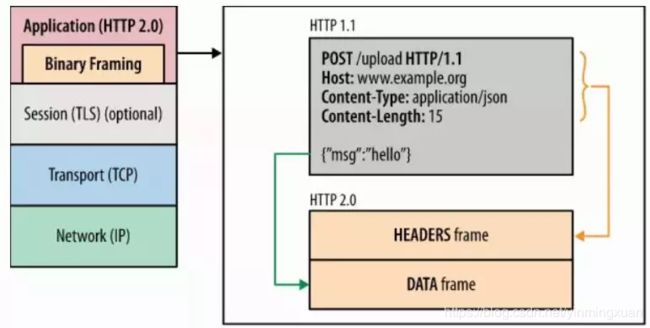
HTTP2的例子告诉我们,为了程序的效率,未来大趋势应该用二进制消息,而不是文本消息。使用二进制消息格式,一般来说开发人员是比较厌恶的,因为需要自己一个个字节,甚至一个个比特位去解析,非常麻烦,而且还不好扩展,也不像json那样有大把的第三方库可用。
三、protocol buffer简单介绍
有需求就会商机啊,protocol buffer就是谷歌公司的解决方案,如今都做打造成数据标准了。
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。(这是几乎10年前的数据,说明protobuf经历了实践的检验)
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前protobuf几乎支持所有编程语言。
总的说,protobuf有几个优点:
- 多开发语言支持, 通用!
- 基于二进制,比xml快20到100倍!
- 可扩展!
- 体积小 ,比xml小3到10倍
- 已经大规模商用过,可信赖
以上几个特点让protobuf开始普及,国内好多应用开发者都开始使用protobuf,没用上的都感觉吃亏了。
为什么protobuf能节省消息体积,网络上有好文章:
https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
四、软件安装
接下来我们以ubuntu操作系统为例,介绍protobuf的安装。
下载
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git submodule update --init --recursive
编译与安装
sudo apt-get install autoconf automake libtool curl make g++ unzip
./autogen.sh
./configure
make
make check
sudo make install
安装好后,我们得到
- protoc 用于将消息定义文件编译成特定编程语言代码
- 头文件,默认位于
/usr/local/include/google/protobuf/下 - libprotobuf.so
五、protobuf的使用,以c++为例
一般使用protobuf,分两步:
-
创建一个扩展名为.proto的文本文件,然后在里边定义消息的格式
-
按制定的消息协议规范使用protobuf消息
a. 静态使用
将.proto文件编译成代码
用生成的代码编码和解码消息
b. 动态使用
定义消息格式
使用protobuf前,先定义好消息的格式,需要遵循protobuf的消息格式规范来。protobuf目前有proto2和proto3两个版本。
详细的规范可以看官方的说明:
https://developers.google.cn/protocol-buffers/docs
proto3版本消息定义实例
syntax = "proto3"; //设置protobuf的版本
package demo.messages; //protobuf支持用包来区分消息
//消息格式定义
message person
{
string name = 1;
int32 id = 2;
string email = 3;
};
proto2版本消息定义实例
syntax = "proto2";
package demo.messages;
message person
{
//required限定词要求该字段不能忽略
required string name = 1;
optional int32 id = 2;
optional string email = 3;
};
proto3中规定没有必选字段,所有字段都是可选的,这一规定使得protobuf对旧协议有良好的兼容性,并可随意扩展。这个思想我们可以借鉴一下,平时不要将消息定死。
protobuf静态解析
所谓静态解析,就是protobuf按照你的消息格式定义为你生成相应的数据结构定义,以及编码和解码的代码,我们利用这部分生成的代码来编码和解析消息。
例如,我们使用protobuf提供的protoc工具生成消息编码和解码代码:
$ protoc -I. --cpp_out=. person.proto
$ ls
person.pb.cc person.pb.h person.proto
person.pb.cc person.pb.h这两个文件就是protoc为我们生成的消息格式定义以及编码解码代码。我们用的是c++语言,代码为我们生成了struct person的定义和struct person的解码和编码接口。
本地写
下面演示将一个protobuf消息对象序列化后写入到本地磁盘文件内:
#include "person.pb.h"
#include
#include
using namespace std;
int main(int argc, char** argv) {
GOOGLE_PROTOBUF_VERIFY_VERSION; //检验版本
//用protobuf生成的代码定义一个消息
demo::messages::person p;
p.set_name("egg");
p.set_id(1);
p.set_email("[email protected]");
cout << "length: " << p.ByteSize() << endl;
//序列化到文件里
fstream fout("./egg.db", ios::out | ios::trunc | ios::binary);
//
if (!p.SerializeToOstream(&fout)) {
cerr << "save fail." << endl;
return -1;
}
cout << "save ok." << endl;
}
本地读
下面演示将本地存储的protobuf消息反序列化为内存里的对象。
#include "person.pb.h"
#include
#include
using namespace std;
int main(int argc, char** argv) {
GOOGLE_PROTOBUF_VERIFY_VERSION;
demo::messages::person p;
fstream fin("./egg.db", ios::in | ios::binary);
//ParseFromIstream是protoc为我们生成的解析函数
if (!p.ParseFromIstream(&fin)) {
cerr << "parse fail." << endl;
return -1;
}
cout << "id:" << p.id() << endl;
cout << "name:" << p.name() << endl;
cout << "email:" << p.email() << endl;
}
输出结果
id:1
name:egg
email:[email protected]
跨网络传输消息的例子
protocol buffer可以对数据进行序列化和反序列化,但是要在网络上传输protocol buffer二进制消息还需要处理下面的问题:
- 长度,protobuf 打包的数据没有自带长度信息或终结符,需要由应用程序自己在发生和接收的时候做正确的切分;
- 类型,protobuf 打包的数据没有自带类型信息,需要由发送方把类型信息传给给接收方,接收方创建具体的 Protobuf Message 对象,再做的反序列化。
对于第一个问题,我们在数据传输时,可以自行加上一个长度字段length。
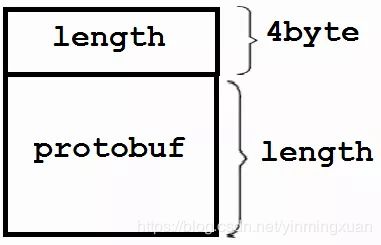
第二个问题我们可以再加上一个消息名称字段(读者可以自行尝试),也可以通过后边j讲到的动态解析来解决。
发送端
char tmp[100];
sprintf(tmp, "egg %d", i+1);
demo::messages::person p;
p.set_name(tmp);
p.set_id(1);
p.set_email("[email protected]");
//总共发送的长度为 4 + protobuf消息长度
int totalLength = 4 + p.ByteSize();
char *buffer = new char[totalLength];
*((int*)buffer) = p.ByteSize();//设置长度
//序列化到buffer中
p.SerializeToArray(buffer + 4, p.ByteSize());
//将总共4 + p.ByteSize()个字节数据发送过去
if(0 != sendn(sock, buffer, totalLength)){
cerr << "send fail..." << endl;
}
接收端
//先读消息长度,4字节
len = readn(clientfd, buffer, 4);
if (4 != len) {
break;
}
len = *(int*)buffer;
//再读取protobuf消息体
if (len != readn(clientfd, buffer, len)) {
cerr << "bug2" << endl;
break;
}
//同样,读取自己添加的消息类型字段
...
if (消息类型是demo::messages::person) {
demo::messages::person pp;
//用protobuf生成的ParseFromArray接口解析
if(!pp.ParseFromArray(buffer, len)) {
cerr << "bug3" << endl;
break;
}
}
protobuf动态解析
动态解析,程序不再需要包含静态的上面提到的person.pb.h和person.pb.cc,protobuf只需要知道消息的定义规则person.proto就可以将消息解析出来。
动态解析消息
这种方式protobuf可以从序列化的数据中解析出消息对象,保存为通用的Message对象,使用的时候我们从Message消息里取相应的字段的值。
int reflect_test(char *buffer, int len) {
DiskSourceTree sourceTree;
sourceTree.MapPath("", "./");
Importer importer(&sourceTree, NULL);
importer.Import("person.proto");
const Descriptor *descriptor = importer.pool()->FindMessageTypeByName("demo.messages.person");
if (!descriptor) {
cerr << "find msg fail." << endl;
return -1;
}
cout << descriptor->DebugString();
DynamicMessageFactory factory;
const Message *message = factory.GetPrototype(descriptor);
Message *msg = message->New();
if (!msg) {
cerr << "create msg fail." << endl;
return -1;
}
//消息解析
if (!msg->ParseFromArray(buffer, len)) {
cerr << "bug4" << endl;
return -1;
}
//解析成功后,就可以拿到消息类型了
cout << "msg type is: " << msg->GetTypeName() <PrintDebugString();
const Reflection *reflection = msg->GetReflection();
int valueInt;
string valueString;
//遍历,动态获取各个字段的值
for (int i = 0; i < descriptor->field_count(); i++) {
const google::protobuf::FieldDescriptor * fieldDescriptor = descriptor->field(i);
cout << "name: " << fieldDescriptor->name()
<< " type:" << fieldDescriptor->type_name() ;
switch (fieldDescriptor->cpp_type()) {
case google::protobuf::FieldDescriptor::CPPTYPE_INT32:
//获取值
valueInt = reflection->GetInt32(*msg, fieldDescriptor);
cout << " value: " << valueInt << endl;
break;
case google::protobuf::FieldDescriptor::CPPTYPE_STRING:
valueString = reflection->GetString(*msg, fieldDescriptor);
cout << " value: \"" << valueString << "\"" << endl;
break;
default:
break;
}
}
//或者直接获取某个字段
//const google::protobuf::FieldDescriptor * fieldDescriptor = descriptor->FindFieldByName("xxx");
//msg->PrintDebugString();
delete msg;
cout << "reflect test success." << endl;
return 0;
}
输出
message person {
string name = 1;
int32 id = 2;
string email = 3;
}
#这是拿到的消息类型
msg type is: demo.messages.person
#反射获取到的消息对象个字段的类型,名称,以及值
name: name type: string value = "egg 10000"
name: id type: int32 value = 1
name: email type: string value = "[email protected]"
动态修改消息
像java一样,可以通过反射修改消息对象某个字段的值:
DiskSourceTree sourceTree;
sourceTree.MapPath("", "./");
Importer importer(&sourceTree, NULL);
importer.Import("person.proto");
const Descriptor *descriptor = importer.pool()->FindMessageTypeByName("demo.messages.person");
if (!descriptor) {
cerr << "find msg fail." << endl;
return -1;
}
DynamicMessageFactory factory;
const Message *message = factory.GetPrototype(descriptor);
Message *msg = message->New();
const Reflection *reflection = msg->GetReflection();
//找到字段
const FieldDescriptor *field = descriptor->FindFieldByName("len");
//动态修改字段的值
reflection->SetUInt32(msg, field, 1);
动态创建消息定义
除了通过前边提到的import的方式,还可通过代码生成消息的格式定义。
FileDescriptorProto file_proto;
file_proto.set_name("demo.messages.student");
file_proto.set_syntax("proto3");
//定义一个新消息
DescriptorProto *message_proto = file_proto.add_message_type();
message_proto->set_name("student");
FieldDescriptorProto *field_proto = NULL;
//添加消息的字段
field_proto = message_proto->add_field();
field_proto->set_name("len");
field_proto->set_type(FieldDescriptorProto::TYPE_UINT32);
field_proto->set_number(1);
RPC
Protocol Buffer仅仅是提供了一套序列化和反序列化结构数据的机制,本身不具有RPC功能,但是可以基于其实现一套RPC框架。本文不再介绍,感兴趣的可以自行了解。
六、结束语
protobuf是不错的数据交互与存储的方案,提效又降费!很多应用已经用上了,如果自家应用没有跟上就吃亏了,因为比别人的应用慢还比别人多花流量费。需要文中例子代码的朋友,欢迎关注我们公众号,回复"protobuf"获取。