源码阅读(35):Java中线程安全的Queue、Deque结构——LinkedBlockingQueue(1)
1、概述
之前花了大量的篇幅介绍了一个Java中线程安全的Queue结构:ArrayBlockingQueue。主要是为了归纳分类这些线程安全性的Queue、Deque结构的设计共性。实际上ArrayBlockingQueue已经拥有了其它线程安全的Queue结构的大部分处理特点:
-
基本上有界队列都通过类似notEmpty和notFull这样的java.util.concurrent.locks.Condition对象,来协调生产者线程和消费者线程的控制。
-
基本上队列都通过类似count这样的变量,来记录队列中的数据总量。基本上有界队列还要通过类似capacity这样的变量来记录队列的容量上限;而无界队列对于容量的记录要求相对不严格,甚至没有直接的变量进行容量上限的记录。
-
线程安全的阻塞性队列,大多数通过可重入锁ReentrantLock来保证多线程场景下的操作安全性(基于AQS方式),但也有线程安全的队列使用CAS方式保证线程安全性。两种保证线程安全新的技术使用其中一种就足够了。
-
为了保证多线程操作场景下,多个迭代器的工作稳定性,这些队列结构中的迭代器都做了较复杂的设计,其中ArrayBlockingQueue的迭代器又最具有代表性。
-
为了保证设计思路的可靠性,java原生的线程安全队列的设计原理只有几种:数组、链表(一般是单向的)、树(一般是堆树)。这样做的目的主要是为了承接基础java集合框架(Java Collection Framework)的设计思想,以便于使用者进行源码阅读。
基于介绍ArrayBlockingQueue时我们描述的这些设计共性,本系列开始为读者介绍另一个重要的阻塞性队列LinkedBlockingQueue。LinkedBlockingQueue是一种内部基于链表的,使用在高并发场景下的阻塞队列,且是一种无界队列。
2、LinkedBlockingQueue基本结构
下图展示了LinkedBlockingQueue队列的基本内部结构:
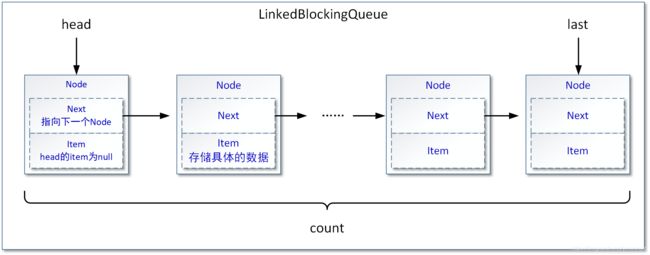
上图即使读者没有接触过LinkedBlockingQueue队列的源代码,也是非常容易理解的。请注意队列中处于队列头部的节点,那个被head属性引用的节点,这个节点(Node)中的item属性始终不存储数据对象(后文会进行详细介绍)。
2.1、LinkedBlockingQueue中重要的属性
从上图中我们知道LinkedBlockingQueue队列通过一个单向链表进行数据描述,其中LinkedBlockingQueue类中的head属性指向单向链表的首节点,last变量指向单向链表的尾节点。capacity变量表示LinkedBlockingQueue队列的容量上限…………,以下是LinkedBlockingQueue队列中各种重要的属性信息:
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// ......
// 该属性代表当前LinkedBlockingQueue队列的最大容量上限
// 如果在LinkedBlockingQueue队列初始化时没有特别指定,就会被设置为Integer.MAX_VALUE
// 这样一来LinkedBlockingQueue就相当于一个无界队列
/** The capacity bound, or Integer.MAX_VALUE if none */
private final int capacity;
// 当前LinkedBlockingQueue队列中的数据量,为什么要使用基于CAS原理的AtomicInteger?
// 究其原因是因为LinkedBlockingQueue队列的读写操作分别由两个独立的可重入锁进行控制
/** Current number of elements */
private final AtomicInteger count = new AtomicInteger();
// head指向单向链表的首节点,注意,head不会为null
transient Node<E> head;
// last指向单向链表的尾节点,注意,laset也不会为null
// 有的时候head和last可能指向同一个节点。
private transient Node<E> last;
// 这个可重入锁保证取出数据时的安全性,主要保证类似take, poll这样的方法的取数正确性
private final ReentrantLock takeLock = new ReentrantLock();
// 这个Condition条件对象,当队列中至少有一个数据时,进行通知
@SuppressWarnings("serial") // Classes implementing Condition may be serializable.
private final Condition notEmpty = takeLock.newCondition();
/ 这个可重入锁保证添加数据时的安全性,主要保证类似put, offer这样的方法的添加正确性
private final ReentrantLock putLock = new ReentrantLock();
// 这个Condition条件对象,当队列中至少有一个空闲的可添加数据的位置时,进行通知
@SuppressWarnings("serial") // Classes implementing Condition may be serializable.
private final Condition notFull = putLock.newCondition();
// ......
}
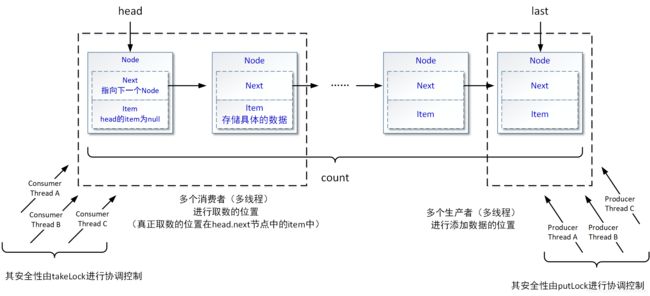
以上代码片段在读者阅读了ArrayBlockingQueue的源代码后,是不是就有了一些似曾相识的感觉?这就是因为这两个BlockingQueue结构的基本设计思路都是统一的。从以上代码片段可以看出,后者和前者最大的区别除了一个使用单向链表结构,一个使用数组结构外,另外最大的区别就是后者的代码中有两个可重入锁分别对数据添加过程和取数过程的多线程操作正确性进行控制。换句话说LinkedBlockingQueue的添加和取数过程应该是不冲突的,这在后续的内容中会进行详细介绍。
根据以上的描述,我们对之前LinkedBlockingQueue队列内部结构的示意图进行了细化:
2.2、LinkedBlockingQueue的构造函数
LinkedBlockingQueue一共有三个可用的构造函数,代码片段如下所示:
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// 这是默认的构造函数,其中调用了LinkedBlockingQueue(int)这个构造函数
// 设定LinkedBlockingQueue队列的最大熔炼上限为Integer.MAX_VALUE(相当于无界队列)
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
// 该构造函数可以由调用者设定LinkedBlockingQueue队列的容量上限
// 如果设定的容量上限小于等于0,则会抛出异常
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.capacity = capacity;
// 为LinkedBlockingQueue队列初始化一个单向链表,单向链表中只有一个Node节点,且这个节点没有item数据
last = head = new Node<E>(null);
}
// 该构造函数在完成LinkedBlockingQueue队列初始化后,将一个外部集合C中的数据添加到LinkedBlockingQueue队列中
// 集合c不能为null,否则会抛出异常;集合c中被取出的数据也不能为null,否则同样抛出异常。
public LinkedBlockingQueue(Collection<? extends E> c) {
// 进行LinkedBlockingQueue默认的初始化过程
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
// 获取添加操作的操作权
// 注意:由于是对象的实例化过程,所以这里实际上不会有操作抢占的问题
// 但是基于整个LinkedBlockingQueue操作的规范性和代码可读性来说,是必要进行的
putLock.lock();
try {
int n = 0;
for (E e : c) {
// 外部集合c中取出的数据不能为null
if (e == null) {
throw new NullPointerException();
}
// 这句话可避免c中的数据总量大于Integer.MAX_VALUE
// 基本上不会出现这种情况,但还是进行了限制
if (n == capacity) {
throw new IllegalStateException("Queue full");
}
// 依次进行数据的添加操作
// enqueue方法和dequeue方法,下文中将立即进行介绍
enqueue(new Node<E>(e));
++n;
}
// n代表初始化完成后,LinkedBlockingQueue队列中的数据总量
// 赋值为AtomicInteger count属性。
count.set(n);
} finally {
putLock.unlock();
}
}
}
LinkedBlockingQueue队列完成实例化后,最常见的情况如下图所示:
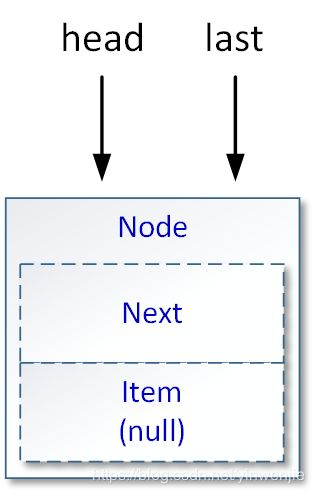
基本上来说,如果在LinkedBlockingQueue队列实例化过程中,没有外部集合要求进行传入,那么实例化过程实际上就是初始化head、last属性的过程——这两个属性将引用同一个Node节点。此时LinkedBlockingQueue队列中只有这一个Node节点,且其中的item属性为null。实际上在后续的操作中,LinkedBlockingQueue队列始终会保证在最前面的Node节点中,item属性一直为null。
2.3、入队和出队操作
和前文已经介绍过的ArrayBlockingQueue队列类似,LinkedBlockingQueue队列的数据入队操作和数据出队操作,也是基于两个私有方法来进行,且在进行这两个私有方法操作时,调用者必须自行获取队列操作权限。这两个私有方法分别是enqueue()方法和dequeue方法,下面本文就先行介绍这两个私有方法:
- enqueue(Node) 方法负责的入队操作
// 这是一个Node节点的定义,其中包括两个属性:
// item:用于存储当前节点的数据引用(可能为null)
// next:指向当前节点的下一个节点(可能为null)
static class Node<E> {
E item;
Node<E> next;
Node(E x) {
item = x;
}
}
// 该私有方法负责进行数据入队操作,既是在当前队尾(last指向的节点之后)添加一个新的Node节点
// 该方法的调用者需要获得两个操作前提:
// 1、外部调用者所在线程必须已经获取了putLock锁
// 2、当前last中的next属性值为null
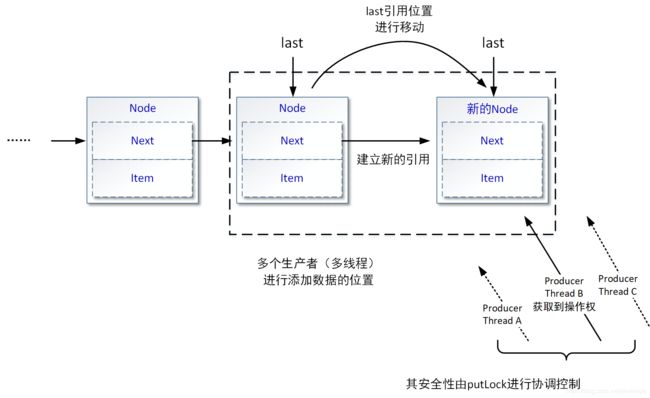
private void enqueue(Node<E> node) {
// 只有这一句代码
last = last.next = node;
}
enqueue(Node)方法中只有一句代码,主要过程是:首先将传入的node节点引用至当前last的next属性下,最后将last位置的指向向后移动,如下图所示:
- dequeue() 方法负责的出队操作
由于ArrayBlockingQueue队列使用的单向链表中,其head位置指向的Node节点中,item属性都为null。为了保持这样的结构特点,ArrayBlockingQueue中的dequeue()方法相比enqueue(Node)方法就要稍微复杂一点:
// 该方法负责出队操作,既是把队列头部的数据移除队列的操作
// 该操作同样需要保证两个前提条件:
// 1、外部调用者所在线程必须已经获取了takeLock锁
// 2、当前head位置的Node节点,其中的item属性为null
private E dequeue() {
// 需要新创建两个局部变量,辅助指向head位置,和head位置的下一个位置(后者可能为null)
Node<E> h = head;
Node<E> first = h.next;
// 将head.next属性引用的位置指向自己,以帮助进行垃圾回收
// 另外将节点的next属性的引用指向自己,这种引用特性将帮助后介绍的迭代器位置校验过程进行逻辑处理
h.next = h; // help GC
// 将当前head的位置向后移动
head = first;
// 从局部变量first所指向的Node中,获得本次要出队的数据对象
// 并使当前first位置的Node节点,称为下一个head位置
E x = first.item;
first.item = null;
// 返回获取到的数据对象
return x;
}
以上dequeue()方法的操作过程,可以用下图进行表达:
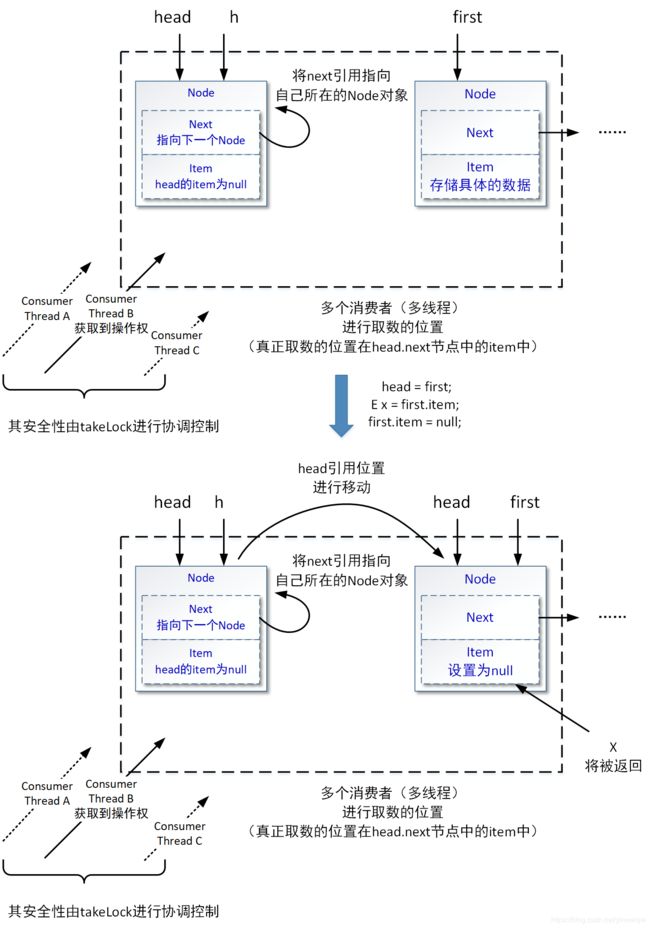
这里我们重点说明一下“h.next = h”这句代码,这句代码从字面的意义可以看出,是将head.next属性的引用位置指向head对象本身,也就是指向当前队列中的第一个节点(头节点)。
我们知道,一般将对象的引用设定为null。这样一来,如果当前对象在内存中已经没有强引用可达,那么垃圾回收器就会回收这个对象。这里需要注意的是,可达性是判定垃圾回收器是否回收对象的主要判定依据,为了提高可达性的判定性能还加入了引用计数器,但是后者在对象不可达时,不一定非要降为0。(有兴趣的读者可以自行查阅关于可达性和引用计数器的相关资料)
如上所示的“h.next = h”这个代码片段,虽然h.next所指向的对象其引用计数器不为0,但如果整个进程中从GC Roots开始该对象已经不可达,那么这个对象也会被垃圾回收器回收。
========
(接后文《源码阅读(36):Java中线程安全的Queue、Deque结构——LinkedBlockingQueue(2)》)