java源码阅读 - TreeMap
往期文章
- HashMap中putAll()方法批量保存的源码解读,并发现严重缺陷
- 用最简单的话讲最明白的红黑树
- 数据结构 - 堆与堆排序
文章目录
- 往期文章
- 一、介绍
- 二、类的声明
- 三、底层实现
- 四、成员变量
- 五、内部类Entry
- 六、构造方法
- 七、buildFromSorted()方法
-
- 1. computeRedLevel()方法
- 2. 重载buildFromSorted()方法
- 八、getEntry()方法
- 九、getFirstEntry()
- 十、getLastEntry()
- 十一、successor()
- 十二、predecessor()
- 十三、常用方法
-
- 1. NavigableMap接口的实现
- 2. SortedMap接口的实现
- 3. Map接口的实现
- 十四、总结
一、介绍
在上一篇文章中,我们介绍了java集合框架中的Map一族的HashMap源码解读,从中得知在HashMap中各个键值对的存储是无序的,导致我们在遍历它的时候无法得到一个有序的键值对集合。所以本文章给大家带来Map的另一个实现TreeMap,从使用上来看,TreeMap中的键值对是有序的;从底层实现来看,TreeMap是由红黑树实现的。这两点是TreeMap与HashMap最大的区别。同时也正因为TreeMap底层是由红黑树实现的,所以他是有序的。
在学习TreeMap之前,如果您对红黑树还不是很了解,请一定先把红黑树学好了再学TreeMap,参考前面的文章用最简单的话讲最明白的红黑树
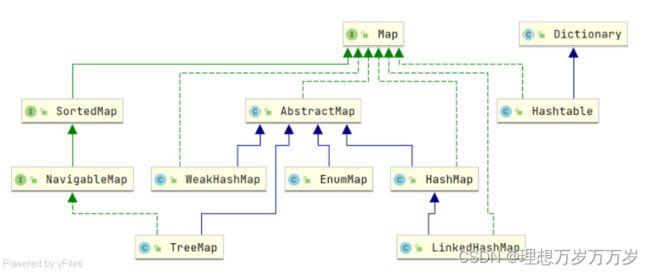
首先看一下Map家族的UML类图:
二、类的声明
我们来看一下TreeMap的声明,可以大致了解他的功能。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
-
继承了AbstractMap类,提供了一些Map相关的基本功能如添加、删除、判空、获取元素数量等,同时是一个以
键值对 -
实现了NavigableMap,提供了导航功能,NavigableMap实现了SortedMap,因此也提供了排序的功能。
所谓导航,就是为给定的搜索目标返回最接近的匹配从字面上不好理解它的含义,我们看一下该接口中声明了哪些方法就明白了
public interface NavigableMap<K,V> extends SortedMap<K,V> { // 方法lowerEntry、floorrEntry、higherEntry、ceilingEntry分别返回集合中小于、小于等于、大于、大于等于指定key的map集合。如果集合中不存在该指定的key,则返回null。 Map.Entry<K,V> lowerEntry(K key); Map.Entry<K,V> floorEntry(K key); Map.Entry<K,V> higherEntry(K key); Map.Entry<K,V> ceilingEntry(K key); // 方法lowerKey、floorKey、higherKey、ceilingKey分别返回集合中小于、小于等于、大于、大于等于指定key的且最接近该指定key的key。如果集合中不存在该指定的key,则返回null。 K lowerKey(K key); K floorKey(K key); K higherKey(K key); K ceilingKey(K key); // 方法firstEntry、lastEntry分别返回该有序集合中的第一个、最后一个键值对。如果集合为空,则返回null Map.Entry<K,V> firstEntry(); Map.Entry<K,V> lastEntry(); // 方法pollFirstEntry、pollLastEntry分别返回该有序集合中的第一个、最后一个键值对,然后从集合中删除该键值对。如果集合为空,则返回null Map.Entry<K,V> pollFirstEntry(); Map.Entry<K,V> pollLastEntry(); // 返回与原集合顺序相反的map集合 NavigableMap<K,V> descendingMap(); // 返回原集合中键值对的set集合、 NavigableSet<K> navigableKeySet(); // 返回与navigableKeySet方法返回的set集合 顺序相反 的set集合 NavigableSet<K> descendingKeySet(); // 以下方法为 从原map集合中截取集合 NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive); NavigableMap<K,V> headMap(K toKey, boolean inclusive); NavigableMap<K,V> tailMap(K fromKey, boolean inclusive); SortedMap<K,V> subMap(K fromKey, K toKey); SortedMap<K,V> headMap(K toKey); SortedMap<K,V> tailMap(K fromKey); } -
实现了Cloneable接口,提供了对象克隆方法,但请注意,是浅克隆。
-
实现了Serializable接口,支持序列化。
三、底层实现
TreeMap是以红黑树作为底层实现的,每个 Comparator 或 key所实现的继承自Compareable的compareTo()方法。
注意:我们在讲HashMap时关键字之间的比较是equals()方法判断是否相同,而在TreeMap中,关键字之间的比较是通过比较器对关键字比个高低。
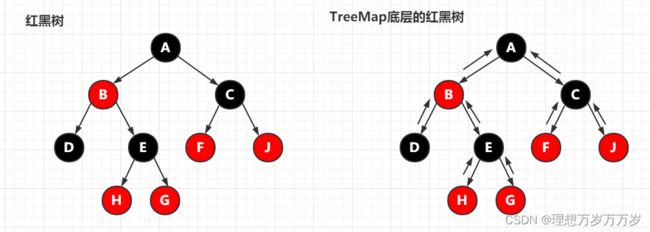
另外:红黑树中只保留了从父节点指向两个子节点的指针,分别为left和right。而TreeMap在红黑树的基础上,添加了从子节点到父节点的指针。如图所示:
四、成员变量
在TreeMap中,成员变量非常少。原因是由于底层实现为红黑树,即树形结构,只需要一个表示根节点的属性,节点与节点之间的链接都是通过节点内的属性表示的。另外还需要一个比较器,由于红黑树属于二叉排序树,需要通过比较器决定新节点将放置在父节点的左边或者右边。如下所示
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {
// 比较器
private final Comparator<? super K> comparator;
// 根节点
private transient Entry<K,V> root;
// 红黑树中entry节点的数量
private transient int size = 0;
// 修改次数,用于在迭代器中遍历时提供快速失败
private transient int modCount = 0;
}
五、内部类Entry
TreeMap的内部类Entry实现了Map接口的内部接口Entry,因此TreeMap使用该内部类Entry作为红黑树中保存数据以及父子引用关系的节点,如下所示。
static final class Entry<K,V> implements Map.Entry<K,V> {
// key-value键值对
K key;
V value;
// left、right、parent分别指向当前节点的左孩子、右孩子、父节点
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
// 标记当前节点的红黑属性
boolean color = BLACK;
// 在创建entry节点实例时,确定该节点的父节点
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
}
六、构造方法
TreeMap提供了四个构造方法
-
无参构造
该方法实现仅仅是将比较器置为空,即不存在比较器。那么在遍历红黑树时如何进行比较呢?
public TreeMap() { comparator = null; }这种情况下,要求节点中的key必须实现
Compareable接口的compareTo()方法。为啥?我们看一下
put()方法,在保存key-value键值对时,如果没有指定的构造器,则需要将传入的key转为Comparable对象,并通过其compareTo进行比较。public V put(K key, V value) { Entry<K,V> t = root; // ... Comparator<? super K> cpr = comparator; if (cpr != null) { // ... } else { // ... Comparable<? super K> k = (Comparable<? super K>) key; cmp = k.compareTo(t.key); // ... } // ... } -
指定比较器
该构造方法仅仅指定了比较器。
public TreeMap(Comparator<? super K> comparator) { this.comparator = comparator; } -
根据传入的
Map集合构造该方法传入一个Map集合,将该集合中的所有键值对通过
putAll()方法保存到TreeMap集合中。由于Map集合范围较大,既有有序的Map集合,又有无序的Map集合。该方法针对的就是将无序的Map集合中的键值对保存到TreeMap集合中,并将比较器置为空,也正因此,我们传入的无序的Map集合中的键值对的key必须实现Compareable接口的compareTo()方法。public TreeMap(Map<? extends K, ? extends V> m) { comparator = null; putAll(m); } public void putAll(Map<? extends K, ? extends V> map) { int mapSize = map.size(); if (size==0 && mapSize!=0 && map instanceof SortedMap) { Comparator<?> c = ((SortedMap<?,?>)map).comparator(); // 在比较器相同、参数map中存在键值对,且当前TreeMap实例中键值对数量为0时,通过buildFromSorted将参数map中的键值对构建成红黑树 if (c == comparator || (c != null && c.equals(comparator))) { ++modCount; try { buildFromSorted(mapSize, map.entrySet().iterator(), null, null); } catch (java.io.IOException cannotHappen) { } catch (ClassNotFoundException cannotHappen) { } return; } } super.putAll(map); }在这里有同学会说了,前面不是说只针对无序的Map集合进行实例化吗?但是
putAll()方法明明对有序的Map集合进行了判断处理。别忘了,putAll()方法可不仅在这一个地方调用。因此,在该构造方法中,虽然调用了putAll()方法,但在putAll()方法中实际只运行了super.putAll(map)这一行代码。来看一下父类的
putAll()方法如何实现?如下代码所示,其实就是遍历参数map集合中的键值对,并调用put()方法将每一个键值对逐个保存到红黑树中,这里父类提供的putAll()方法是设计模式——模版方法的体现,put()方法由TreeMap实现。public void putAll(Map<? extends K, ? extends V> m) { for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) put(e.getKey(), e.getValue()); } -
根据传入的
SortedMap集合构造因为
SortedMap集合本身就是通过比较器Comparator比较后得到有序的map集合,即使其不存在比较器Comparator,它内部键值对的key也一定是实现了Compareable接口的compareTo()方法。所以这个构造器针对的是有序的map集合。其中
buildFromSorted()方法较为复杂,我们下面详细介绍。public TreeMap(SortedMap<K, ? extends V> m) { // 获取SortedMap中的比较器,用来在遍历TreeMap键值对时的比较 comparator = m.comparator(); try { // 从有序的map集合中构建红黑树 buildFromSorted(m.size(), m.entrySet().iterator(), null, null); } catch (java.io.IOException cannotHappen) { } catch (ClassNotFoundException cannotHappen) { } }
七、buildFromSorted()方法
该方法虽然只有短短两行,但是包含的信息量可不少,从方法名来看就是从有序的集合中构建红黑树,但从参数来看它其实是提供了两种方式来构建红黑树的。
-
根据迭代器构建。
该迭代器必须是键值对的迭代器。
-
根据对象输入流构建。
以对象输入流中的对象作为key,参数
defaultVal作为key对应的value值。结合红黑树的要求,该对象输入流中的对象必须实现了Compareable接口的compareTo()方法,或当前TreeMap中已经存在一个比较器Comparator。
另外在该方法中调用了它的重载方法buildFromSorted(),该重载方法是真正处理构建红黑树的方法。
/**
* 根据有序的键值对迭代器或对象输入流构建红黑树,
* 注意:迭代器的优先级比输入流高,如果迭代器和输入流都不为空,则选择迭代器构建。
*
* @param size 即键值对的数量
* @param it 键值对的迭代器,如果迭代器不为空,则通过该迭代器构建红黑树,也就是说红黑树中的键值对来自该迭代器
* @param str 对象输入流,如果输入流不为空,则通过该输入流构建红黑树,也就是说红黑树中的键值对来自该输入流。
* @param defaultVal 默认的value值,与对象输入流搭配使用。对象输入流中的对象作为键值对的key,defaultVal作为默认的value
*
**/
private void buildFromSorted(int size, Iterator<?> it, java.io.ObjectInputStream str, V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
}
1. computeRedLevel()方法
在buildFromSorted()方法中我们看到首先是调用了computeRedLevel()方法,并以键值对数量作为参数。从方法名来看,它是为了计算红色节点的层次,这是什么意思呢?这个计算方法借鉴于完全二叉树,计算结果为树的高度或树的深度
private static int computeRedLevel(int sz) {
int level = 0;
for (int m = sz - 1; m >= 0; m = m / 2 - 1)
level++;
return level;
}
2. 重载buildFromSorted()方法
我本想站在代码的角度通过图解的方式对代码一行一行分析,但是由于递归一层一层套用,把我给画迷瞪了不说,画出来的图经过一晚上的睡眠后我是一点都看不懂了,哈哈哈哈哈。所以就换个方法,站在设计者的角度分析该方法实现的思路,也许这是讲解递归最好的方式。
/**
*
* @param level 红黑树中当前处理的深度,即level为n时,表示当前正在处理红黑树中深度为n的那一层
* @param lo 以数组的角度看这个元素序列,序列中第一个元素下标为0,最后一个元素下标为size-1,lo即代表第一个元素的下标
* @param hi 以数组的角度看这个元素序列,序列中第一个元素下标为0,最后一个元素下标为size-1,hi即代表最后一个元素的下标
* @param redlevel 红黑树中深度为redlevel的那一层节点颜色均为红色,方法中有所体现
* @param it 键值对的迭代器,如果迭代器不为空,则通过该迭代器构建红黑树,也就是说红黑树中的键值对来自该迭代器
* @param str 对象输入流,如果输入流不为空,则通过该输入流构建红黑树,也就是说红黑树中的键值对来自该输入流。
* @param defaultVal 默认的value值,与对象输入流搭配使用。对象输入流中的对象作为键值对的key,defaultVal作为默认的value
**/
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
// 该方法通过递归构建红黑树,每递归一次,递归深度+1,就意味着红黑树的深度+1。总的来看,分为三步
// 1.拿到左子树
// 2.将序列中当前元素构造为树的节点,如果当前元素所在的深度==redLevel,则将当前元素对应的节点设为红色,并为该节点设置左子树
// 3.拿到右子树,并为该节点设置右子树
// 下面我们通过源码详细介绍这三个步骤。
// 当前序列中不存在元素,直接返回null
if (hi < lo) return null;
// 获取到序列的中间元素的下标,类似于通过二分法计算子树的根节点下标
int mid = (lo + hi) >>> 1;
// 1.拿到左子树,left即表示左子树的根节点
Entry<K,V> left = null;
if (lo < mid)
// 向树的左下方逐层递归获取到左子树。
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
// 2.将序列中当前元素构造为树的节点
K key;
V value;
if (it != null) {
if (defaultVal==null) {
Map.Entry<?,?> entry = (Map.Entry<?,?>)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
} else { // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
// middle表示当前子树的根节点,因为从整棵树来看,根节点位于左右子树的中间,所以变量名为middle
Entry<K,V> middle = new Entry<>(key, value, null);
// 如果当前元素所在的深度==redLevel,则将当前元素对应的节点设为红色
if (level == redLevel)
middle.color = RED;
// 为当前节点设置左子树
if (left != null) {
middle.left = left;
left.parent = middle;
}
// 3.拿到右子树,并为该节点设置右子树
if (mid < hi) {
// 向树的右下方逐层递归获取到右子树。
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
// 为当前节点设置右子树
middle.right = right;
right.parent = middle;
}
// 返回当前子树的跟节点
return middle;
}
从上面对源码的分析看,该方法构造的红黑树和我们在前面介绍的红黑树似乎不大一样。我们在前面讲的红黑树中从某节点到叶子结点的路径上可能是黑红节点交叉出现,而该方法构造出来的红黑树有所不同,他是只有最下面一层节点的颜色为红色。如下图所示
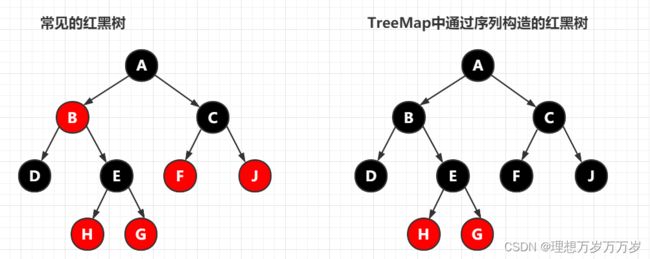
为什么只有最下面一层节点的颜色为红色
从重载的buildFromSorted()方法中我们注意到一个代码块:
// 如果当前元素所在的深度==redLevel,则将当前元素对应的节点设为红色
if (level == redLevel)
middle.color = RED;
八、getEntry()方法
该方法通过接收一个参数key,返回红黑树中该key对应的键值对。
如果当前TreeMap实例中比较器comparator不为空,则调用getEntryUsingComparator方法使用使用比较器遍历红黑树并返回参数key对应的键值对。
如果不存在比较器comparator,我们看到的是将参数key向上转型为Comparable对象,并通过其compareTo()方法进行比较,
遍历的过程非常简单,如果当前节点小于参数key,则使用其右孩子节点与参数key比较;如果当前节点大于参数key,则使用其左孩子节点与参数key比较;如果当前节点等于参数key,则当前节点对应的键值对即为所求。
另外getEntryUsingComparator方法的遍历过程与此相同,就不再赘述了。
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
// 通过比较器遍历红黑树,找到对应的键值对
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
//通过实现Comparable接口的compareTo()方法遍历红黑树,找到对应的键值对
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
九、getFirstEntry()
获取TreeMap中的第一个节点(键值对),由红黑树的性质决定,左子树的节点始终小于根节点,且作为有序的序列,该序列的第一个节点必然位于该红黑树的最小左子树的根节点。因此从根节点开始不断沿着其左孩子遍历,最终得到第一个节点。
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
十、getLastEntry()
与getFirstEntry()同理,红黑树中最后一个节点必然位于该红黑树的最小右子树的根节点。因此从根节点开始不断沿着其右孩子遍历,最终得到最后一个节点。
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p;
}
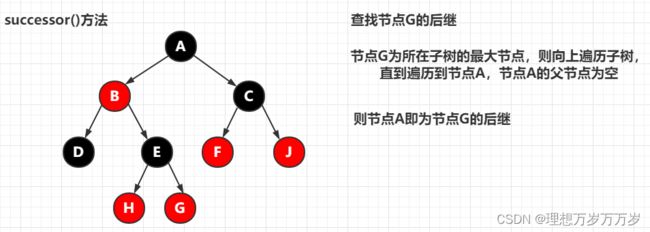
十一、successor()
获取红黑树中当前节点的后继节点,即有序序列中当前节点的后面的节点。
所谓当前节点的后继节点,存在两种情况:
-
当前节点的右子树中的最小节点,即当前节点的右子树中的第一个节点。只要拿到了当前节点的右孩子,再针对以右孩子节点为根的右子树,调用
getFirstEntry()就可以了。虽然没有明着调用getFirstEntry()方法,但是存在与其一模一样的代码逻辑。
-
当前节点为所在子树的最小值,则其父节点即为其后继节点。当前节点为所在子树的最大值,则向更大的子树遍历,直到子树为更大子树的左子树或其父节点为空,则该子树的父节点即为后继节点。
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {
// 获取当前节点的右子树中的第一个节点并将其返回
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
十二、predecessor()
与successor()同理,只是在遍历时左右方向相反,读者可自行体会
static <K,V> Entry<K,V> predecessor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.left != null) {
Entry<K,V> p = t.left;
while (p.right != null)
p = p.right;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.left) {
ch = p;
p = p.parent;
}
return p;
}
}
十三、常用方法
1. NavigableMap接口的实现
-
firstEntry()
导出第一个键值对
public Map.Entry<K,V> firstEntry() { return exportEntry(getFirstEntry()); }可以看到也是通过
getFirstEntry()方法获取第一个键值对的。但exportEntry()是什么操作?何为导出节点?static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) { return (e == null) ? null : new AbstractMap.SimpleImmutableEntry<>(e); }原来,所谓导出节点,就是将
TreeMap.Entry类型的节点转换为AbstractMap.SimpleImmutableEntry类型,虽然导出前后的节点都是Map.Entry接口的实例,但具体的实现类不同。而且从命名来看,转换后的节点是不可变节点,从其成员变量都是final修饰便可得知。public static class SimpleImmutableEntry<K,V> implements Entry<K,V>, java.io.Serializable { private static final long serialVersionUID = 7138329143949025153L; private final K key; private final V value; public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) { this.key = entry.getKey(); this.value = entry.getValue(); } } -
lastEntry()
与
frstEntry()同理,导出最后一个键值对。其中的getLastEntry()方法和exportEntry()方法不再赘述。public Map.Entry<K,V> lastEntry() { return exportEntry(getLastEntry()); } -
pollFirstEntry()
导出第一个键值对,并将其从原集合中删除。
我们不难看出,与
frstEntry()方法相比多了一个删除节点操作,deleteEntry()实现逻辑可参考文章用最简单的话讲最明白的红黑树public Map.Entry<K,V> pollFirstEntry() { Entry<K,V> p = getFirstEntry(); Map.Entry<K,V> result = exportEntry(p); if (p != null) deleteEntry(p); return result; } -
pollLastEntry()
导出最后一个键值对,并将其从原集合中删除。
与
pollFirstEntry()方法同理,不多说了,说不动了。public Map.Entry<K,V> pollLastEntry() { Entry<K,V> p = getLastEntry(); Map.Entry<K,V> result = exportEntry(p); if (p != null) deleteEntry(p); return result; }
2. SortedMap接口的实现
-
comparator()
返回当前TreeMap实例中的比较器。
当然了。如果不存在比较器,而是通过实现
Comparable接口的compareTo()方法进行比较的,它仍然属于不存在比较器的情况,返回null。public Comparator<? super K> comparator() { return comparator; } -
firstKey()
返回第一个键值对的key。
getFirstEntry()方法我们在前面已经讲过,即获取第一个键值对,再通过key()方法获取键值对的key值并返回即可。public K firstKey() { return key(getFirstEntry()); } static <K> K key(Entry<K,?> e) { if (e==null) throw new NoSuchElementException(); return e.key; } -
lastKey()
返回最后一个键值对的key,实现原理与
kirstKey()一致。public K lastKey() { return key(getLastEntry()); }
3. Map接口的实现
-
size()
返回当前TreeMap中键值对的数量
-
containsKey()
是否包含指定的key,true-包含。
从源码可以看到,就是调用
getEntry()方法,如果存在指定的key所对应的键值对,就表明存在指定的key了。public boolean containsKey(Object key) { return getEntry(key) != null; } -
containsValue()
判断是否包含指定的value,true-包含。
从源码可以看到,它是从该序列的第一个元素开始,通过
successor()方法获取后继节点来遍历该红黑树所对应的有序序列。在遍历每一个节点的过程中,判断节点中键值对的value值是否与指定的value值相等。public boolean containsValue(Object value) { for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) if (valEquals(value, e.value)) return true; return false; } -
get()
根据指定的key,获取对应的键值对的value值。
根据
getEntry()方法获取指定key对应的键值对,如果键值对存在,则返回该键值对的value值。否则返回null。public V get(Object key) { Entry<K,V> p = getEntry(key); return (p==null ? null : p.value); } -
put()
通过该方法,向红黑树中添加一个键值对。
其实该方法的实现就是向红黑树中插入一个节点。详细过程我们可以参考前面的文章用最简单的话讲最明白的红黑树,这里我们只是对源码做一些注释。
public V put(K key, V value) { Entry<K,V> t = root; // 根节点为空,说明为空树,则直接根据键值对创建节点并作为根节点 if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; // 通过比较器遍历红黑树,找到新节点的父节点 if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } // 通过实现Compareable接口的compare()方法遍历红黑树,找到新节点的父节点 else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } // 创建节点,并关联父节点 Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; // 节点插入后,可能需要旋转以及对颜色的设置以重新实现红黑树的平衡 fixAfterInsertion(e); size++; modCount++; return null; } -
putAll()
向红黑树中批量存放键值对。忽略其中的两层条件判断,有两种途径实现批量存放:
- 调用
buildFromSorted()方法通过递归实现,该方法在前面已经详细聊过,不再赘述 - 调用父类的
putAll()方法,通过循环遍历键值对并调用put()方法实现。
public void putAll(Map<? extends K, ? extends V> map) { int mapSize = map.size(); if (size==0 && mapSize!=0 && map instanceof SortedMap) { Comparator<?> c = ((SortedMap<?,?>)map).comparator(); if (c == comparator || (c != null && c.equals(comparator))) { ++modCount; try { buildFromSorted(mapSize, map.entrySet().iterator(), null, null); } catch (java.io.IOException cannotHappen) { } catch (ClassNotFoundException cannotHappen) { } return; } } super.putAll(map); }来看一下父类的
putAll()方法如何实现?如下代码所示,其实就是遍历参数map集合中的键值对,并调用put()方法将每一个键值对逐个保存到红黑树中,这里父类提供的putAll()方法是设计模式——模版方法的体现,put()方法由TreeMap实现。正好,put()方法前面讲过,不再赘述。public void putAll(Map<? extends K, ? extends V> m) { for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) put(e.getKey(), e.getValue()); } - 调用
-
remove()
根据指定的key,删除红黑树中对应的节点,并返回该节点中的value
思路很简单,通过
getEntry()找到对应的节点,再调用deleteEntry()删除该节点。getEntry()方法已详细说过,deleteEntry()实现逻辑可参考文章用最简单的话讲最明白的红黑树public V remove(Object key) { Entry<K,V> p = getEntry(key); if (p == null) return null; V oldValue = p.value; deleteEntry(p); return oldValue; } -
clear()
清空红黑树。
由于我们在访问红黑树时都是通过成员变量
root来遍历的。因此直接将该变量置为空即可。public void clear() { modCount++; size = 0; root = null; } -
replace()
根据key替换其对应的value;
通过
getEntry()方法获取到对应的键值对,如果存在,则将键值对中的value值替换成指定的value值。public V replace(K key, V value) { Entry<K,V> p = getEntry(key); if (p!=null) { V oldValue = p.value; p.value = value; return oldValue; } return null; } -
重载replace()
与上面的
replace()方法一致,但多了一个条件,在遍历键值对时,不仅要求key相同,value值也要相同。但要注意一点,key值的比较是通过比较器实现的;而value值的比较是通过
equals()方法实现的。public boolean replace(K key, V oldValue, V newValue) { Entry<K,V> p = getEntry(key); if (p!=null && Objects.equals(oldValue, p.value)) { p.value = newValue; return true; } return false; }
十四、总结
- TreeMap是有序的map集合
- 键值对key不能为null
- 底层由红黑树实现,且在传统红黑树的基础上添加了从孩子节点指向父节点的引用。
- 如果TreeMap中不存在比较器
comparator,则键值对的key必须继承Comparable接口,并实现其compareTo()方法 - 线程不安全
- 提供支持快速失败的迭代器
- 由于底层为红黑树实现,节点之间都是通过引用来确定关系的。因此不存在延迟加载这一说法。不像HashMap那样底层存在数组,也就意味着连续地址的分配,某些情况下为了节省空间需要延迟加载。
纸上得来终觉浅,绝知此事要躬行。
————————————————我是万万岁,我们下期再见————————————————