课程总结 -- CPU/GPU并行计算基础(CPU篇)
上学期选修了Prof. Tolga Soyata的“GPU Parallel Programming using C/C++”课程。该课程主要分两部分:前半部分通过讲解CPU并行程序来介绍并行计算的原理和思路;后半部分讲解如何用CUDA在GPU上进行并行计算。本文纪录其中的基础要点和关键实现方式。通过本文大家可以了解到:1、如何用CPU进行多线程并行计算;2、CUDA是什么,GPU如何进行并行计算;3、并行计算的优越性;4、内存的应用对程序性能的影响。
本文分两部分:第一部分是CPU计算部分,第二部分是GPU计算部分。其中主要介绍实现的具体方法(理论也讲不清楚)。内容参考课上课件和代码,以及教材:CUDA BY EXAMPLE。
0、串行程序
在接下来的几个小节,我们会用不同的方式完成同一个任务:纵向翻转一张3200x1600的图片,并比较它们之间的性能差异。首先我们来看的是采用串行方法的实现,即不使用并行计算,对逐个像素进行交换操作。为了简化读写等无关操作,我们用opencv进行图像的读写,具体代码见这里。
性能:使用串行计算,其速度为平均每张图片约 107ms。
1、第一个CPU并行程序
分析一下这个任务,我们可以发现:每一行执行的操作是独立且相同的。因此我们其实可以让不同行同时执行同样的操作,这便是并行的程序。具体来说,假设我们有 n 个并行的线程,我们便可以让每个线程完成 1/n 的任务,比如线程1完成 [1...colsn] 列,线程2完成 [(colsn+1)...2∗colsn] 列,以此类推。理想状况下,通过 n 个线程同时工作,我们可以将程序的运行时间降低 n 倍。
利用CPU实现上述并行程序需要用到pthread。Pthread是线程的POSIX标准,定义了创建和操作线程的一套API。以下将一些重要的核心代码列出,完整代码可见这里。
- 引用pthread库及声明需要用到的变量
#include - pthread初始化
pthread_attr_init(&ThAttr);
pthread_attr_setdetachstate(&ThAttr, PTHREAD_CREATE_JOINABLE);- 分配线程和结束
for (i=0; ii++) {
ThParam[i] = i;
// important!! lauch threads
ThErr = pthread_create(&ThHandle[i], &ThAttr, MFlip, (void *)&ThParam[i]);
if (ThErr != 0) {
printf("\nThread Creation Error %d.\n", ThErr);
exit(EXIT_FAILURE);
}
}
for (i=0; ii++) {
// important!! join all threads
pthread_join(ThHandle[i], NULL);
}
- 根据线程ID决定改线程开始执行的列数,及该线程退出语句
long ts = *((int *) tid); // thread ID
ts *= rows / NumThreads; // start index
...
pthread_exit(NULL);并行程序的性能如下:
| 线程数 | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| 时间(ms) | 135.54 | 91.72 | 52.18 | 27.99 | 15.13 | 13.62 | 14.40 |
从上表可以看出:
- 线程数为1时,由于增加了调用pthread的一些开销,程序比上一小节的会慢一些
- 逐步增加线程数,可以看到接近线性的加速(增加两倍线程数,时间减少两倍),从中可以看到并行程序的有效性
- 当线程数增加到一定程度后(上表为32),速度提升会遇到瓶颈,即不能永远的达到线性加速。其中的原因比较复杂(其实是我没完全听懂。。),可能涉及内存的共享、系统CPU核的数量、调度等问题,在此不妄加评论了。
2、改善并行程序
在这个小节中,我们会看到合理的内存应用和程序执行方式会对程序性能造成多大的影响。
我们先来分析一下上一小节的并行程序。我们将数据按照线程数量分割成等量的小块,并让不同线程同时执行各个小部分,这种并行方式可以成为数据并行。这种并行方式的好处是每个线程执行的任务都是相同的,只需要标记不同的处理位置。但是这样就足够了吗?并非如此。在上述程序中,我们没有考虑过程序的内存访问模式(Memory Access Pattern)。
毫无疑问,MFlip() 函数是一个内存密集型(memory-intensive)的函数。因为它对每个像素并没有进行任何计算,但是需要频繁的对内存进行读取和写入(为了交换像素值)。对于这一类的函数,其内存访问模式会大大地影响程序的性能。
从直观上我们便能体会到上节中程序的内存访问模式有多么糟糕。每次交换两个像素值,程序都要从内存中读取两个不同位置的数据,并且这两个位置相隔非常的远。而且每次从内存中读取一个像素的值(1比特)也是非常浪费资源的做法。再加上多线程同时进行不同位置的内存读写操作,会使程序的内存访问变得非常低效。从理论上讲,为了达到好的DRAM读写性能,我们需要遵守以下几条规则(为了描述的准确性直接上原文):
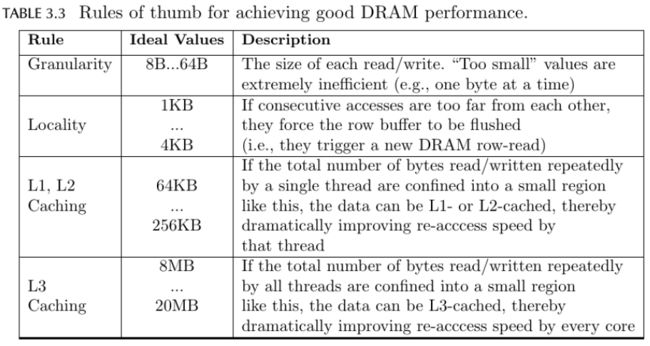
对比一下我们可以发现,上节的程序违反了Granularity的规则,即每次都读写过于少量的数据,造成读写时资源的浪费。另外,上节的程序并没有利用好缓存(cache memory),因为它从来没有进行数据的复用。
因此,我们来改进上节的程序,使其能满足上述的几点规则。从上表可以看到,虽然图片数据存储在DRAM中,我们并不希望频繁地对它进行访问。因此我们可以一次把一行图片的数据读取到一个临时缓冲区中,再对其中的数据进行处理。这样的好处不仅能够减少对DRAM的访问,还能充分利用L1缓存的作用对读取的数据进行重复利用。核心实现代码如下,整体代码在这里。
- 准备两个缓冲区用来存放两行的数据
unsigned char Buffer1[16384]; // This is the buffer to get the first row of image;
unsigned char Buffer2[16384]; // This is the buffer to get the second row of image;- 读取数据进入缓冲区
// important!! copy data to cache memory
memcpy((void *)Buffer1, TheImage.ptr(r), cols*sizeof(unsigned char));
memcpy((void *)Buffer2, TheImage.ptr(rows-(r+1)), cols*sizeof(unsigned char)); - 交换数据(从缓冲区写入内存)
memcpy((void *) TheImage.ptr(r), (void *)Buffer2, cols*sizeof(unsigned char));
memcpy((void *) TheImage.ptr(rows-(r+1)), (void *)Buffer1, cols*sizeof(unsigned char)); 性能如下:(注意,这里的提速有点夸张,个人认为除了内存访问模式的影响以为,还和之前程序中直接对opencv的矩阵对象进行操作有关)
| 线程数 | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| 时间(ms) | 1.65 | 0.95 | 0.96 | 0.85 | 0.86 | 1.42 | 2.52 |
3、同步和异步
前面介绍的并行方式都属于同步并行(synchronized),即程序等待所有并行的线程都执行完当前的任务,再执行下一步工作。这样可能会出现的一个问题是:有些线程由于某些原因执行速度变慢了,则所有线程都会受到它的影响而滞后,因为它们需要等待所有线程都完成任务。换句话说,具有木桶效应。
除了同步并行以外,我们还有另一种并行方式叫作异步并行(asynchronized)。这种并行方式可以使线程无需等待其它线程的工作情况,而直接进行其它任务。下图可以看到它们的关系:
这里我们不讨论同步和异步之间的优劣,只介绍如何实现一个异步的并行程序。与同步并行不同,异步并行会出现线程之间对资源访问的冲突问题。解决这个问题的一种方法是使用互斥量(mutex)。简单来说就是通过对一个共享变量的上锁(lock)和解锁(unlock)来保证在同一时期只有一个线程对共享资源进行修改,从而解决冲突的问题。下图说明了其工作原理:

利用互斥量实现异步并行的核心代码如下,完整代码见这里。注意我们不再将数据等分为 n 份,而是每次让一个空闲的线程执行一行,若完成则等待下一次分配任务。
- 定义和初始化mutex
pthread_mutex_t CounterMutex; // define mutex
...
// initialize mutex
pthread_mutex_init(&CounterMutex, NULL);
pthread_mutex_lock(&CounterMutex);
NextRowToProcess = 0;
for (i=0; i0;
}
pthread_mutex_unlock(&CounterMutex); - 利用mutex互斥地读取和修改下一行的值
// get the next row number
pthread_mutex_lock(&CounterMutex); // lock it before accessing
r = NextRowToProcess;
NextRowToProcess ++;
pthread_mutex_unlock(&CounterMutex); // unlock it after accessing
性能如下:
| 线程数 | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| 时间(ms) | 1.70 | 1.99 | 1.15 | 1.18 | 1.32 | 1.67 | 2.66 |
4、程序与性能(optional)
在这课程中,除了学习到并行计算的原理及实现方式外,我最大的感触便是程序的细微改动对性能巨大的影响。这些改动涉及到内存的访问、CPU计算量的减少等方面。下面这个例子中,我们用7种不同方式实现旋转图片的任务,其中每种实现逐步地对代码进行修改和优化。我们可以看见rotate7()比rotate()的性能要优越很多。由于篇幅关系就不再一一讲解了,具体代码请看这里。