UnityShader:摄像机深度图获取,屏幕分割,变形
最近由于公司业务需要,需要输出深度图,并且游戏最终画面效果要同时输出RGB图和深度图,并分别占据屏幕不同的比例。之前公司同事的做法是用一个相机获取RGB,另一个相机获取深度图(需要用shader对画面进行后期处理),然后相机在屏幕显示比例不同达到最终要求。效果是可行的,但是总感觉很别扭,过于复杂。实际上shader能够输出深度图,本身又有RGB数据,理论上可以用算法一次输出最终分割效果,试了试果然成功了。下面一步步来看如何实现。
一、 后期渲染
屏幕后期渲染需要用到回调函数OnRenderImage:
void OnRenderImage(RenderTexture src, RenderTexture dest)
{
Graphics.Blit(src, dest);
}其中src是屏幕图像,dest是处理后输出的图像,Graphics.Blit函数可以通过材质来对屏幕图像进行加工得到所要的输出图像,比如:
depthMat是上的shader是获取深度图的shader
Graphics.Blit(src, dest, depthMat);将会输出屏幕深度图。
注意这个回调所在的脚本所挂载的对象需要有Camera组件。
这个回调以及相关方法的细节Unity官方都有,在此不细讲。
二、 深度图
有了这个回调之后我们就可以获取深度图了。
下面是获取深度图的shader:
Shader "Custom/Depth" {
SubShader{
Tags{ "RenderType" = "Opaque" }
Pass{
ZTest Always Cull Off ZWrite Off
CGPROGRAM
// Use shader model 3.0 target, to get nicer looking lighting
#pragma glsl
#pragma fragmentoption ARB_precision_hint_fastest
#pragma target 3.0
#pragma vertex vert
#pragma fragment frag
#include "unityCG.cginc"
sampler2D _CameraDepthTexture;
struct v2f {
float4 pos : SV_POSITION;
float4 scrPos:TEXCOORD0;
};
//Vertex Shader
v2f vert(appdata_base v) {
v2f o;
o.pos = mul(UNITY_MATRIX_MVP, v.vertex);
o.scrPos = ComputeScreenPos(o.pos);
return o;
}
//Fragment Shader
float4 frag(v2f i) :COLOR{
float depthValue = 1 - Linear01Depth(tex2Dproj(_CameraDepthTexture, UNITY_PROJ_COORD(i.scrPos)).r);
return float4(depthValue, depthValue, depthValue, 1.0f);
}
ENDCG
}
}
FallBack "Diffuse"
}脚本很简单,关键是用内置深度变量_CameraDepthTexture,对他使用屏幕坐标映射可以获取屏幕坐标的深度数据。获取深度数据后将其缩放到0~1区间并发挥。
有了shader后我们要创建一个Material,将shader赋给它,然后在脚本中获取到这个材质。
假设材质为depthMat,则输出深度图的回调为:
void OnRenderImage(RenderTexture src, RenderTexture dest)
{
Graphics.Blit(src, dest, depthMat);
}原始图:

处理后深度图:

三、 文字深度
上面的内容都是游戏内对象,有时候我们需要文字也有深度,在3D环境下(比如裸眼3D,VR)能够有3D空间效果,这个时候就需要对文字进行处理让它具有深度。具体操作步骤如下:
1. 建立Canves Group
建立一个空对象,添加Canvas Group组件

2. 建立文本Canvans
在上述Canvans Group下建立空子对象,添加Canvas Renderer组件,Canvas组件,Text组件,Text组件的Material需要添加一个材质,Unity自带材质就行,路径为LegacyShaders/Transparent/Cutout/Diffuse(这是新版路径,旧版可能在LegacyShaders目录下。Cutout目录下不止一个shader可以实现且效果不同,自行尝试):

3. 建立图片Canvans
和上述Canvas文本一样的操作,不过最后一个组件是Image而不是Text。图片的各项属性和文本基本相同,有两个地方需要注意:一个是图片要在文本的前方(我这里是Z坐标比文本小),但是Canvas的Order in Layer属性比文本低。
注意这里图片的材质和颜色就是文字的颜色。如果图片不在文字前方,文字将会显示黑色。

4. 相机视野内文字后方必须有背景,不然RGB图中文字会被图片遮挡不显示。
上述步骤最后效果:
RGB图:

深度图:
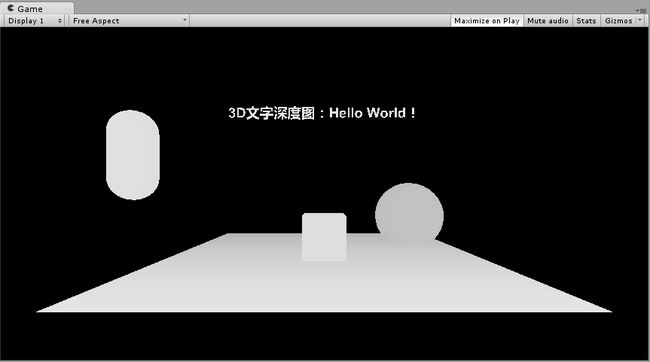
注意:这个方法中的shader除了用来处理文字还可以用来处理有透明通道的图片,让图片的颜色部分产生深度。只需要将材质挂在一个plane上,材质的图片选择对应的图片即可。图片压缩格式要求为DXT5。
四、 RGB+深度图
大多数时候我们要的并不是单纯的深度图,而是RGB和深度图的组合,比如左边是RGB,右边是深度图,在经过画面处理合成后可以显示深度效果(我们公司的裸眼3D显示器就是这么干的),根据设备不同,显示比例也不同,有的还需要特殊的分割,比如3X3或者2X2。这里仅仅实现一种简单的输出:边框占画面的十分之一,左边是RGB图,右边是深度图,并且RGB图宽度是深度图的两倍。
Shader如下:
Shader "Custom/RGBDepth" {
Properties{
_MainTex("Base (RGB)", 2D) = "white" {}
}
SubShader{
Tags{ "RenderType" = "Opaque" }
Pass{
Cull off
ZTest Always Cull Off ZWrite Off
CGPROGRAM
//Physically based Standard lighting model, and enable shadows on all light types
//#pragma surface surf Standard fullforwardshadows
// Use shader model 3.0 target, to get nicer looking lighting
#pragma glsl
#pragma fragmentoption ARB_precision_hint_fastest
#pragma target 3.0
#pragma vertex vert
#pragma fragment frag
#include "unityCG.cginc"
sampler2D _CameraDepthTexture;
uniform sampler2D _MainTex;
struct v2f {
float4 pos : SV_POSITION;
float4 scrPos:TEXCOORD0;
float2 uv : TEXCOORD1;
};
//Vertex Shader
v2f vert(appdata_base v) {
v2f o;
o.pos = mul(UNITY_MATRIX_MVP, v.vertex);
o.scrPos = ComputeScreenPos(o.pos);
o.uv = v.texcoord.xy;
return o;
}
//Fragment Shader
float4 frag(v2f i) :COLOR{
int width = 2560;//画面宽度放大比率
int height = 1440;//画面高度放大比率
int frame = 128;//边框宽度
int RGBWidht = 1536;//RGB图宽度放大比率
int depthWidth = 768;//深度图宽度放大比率
int targetHeight = 1184;//输出图像部分高度
float x = i.uv.x*width;
float y = i.uv.y*height;
//生成四边框
if (xreturn float4(1.0f, 1.0f, 1.0f, 1.0f);
if (x>width - frame)
return float4(1.0f, 1.0f, 1.0f, 1.0f);
if (yreturn float4(1.0f, 1.0f, 1.0f, 1.0f);
if (y>height - frame)
return float4(1.0f, 1.0f, 1.0f, 1.0f);
y = (y-frame);
//分割画面
if (x < frame + RGBWidht) {
x = (x - frame) / RGBWidht;
y= y / targetHeight;
return tex2D(_MainTex, float2(x , y ));
}
else {
x= (x - frame - RGBWidht) ;
i.scrPos.x= x / depthWidth;
i.scrPos.y = y / targetHeight;
float4 uv = UNITY_PROJ_COORD(i.scrPos);
float depthValue = 1 - Linear01Depth(tex2Dproj(_CameraDepthTexture, uv).r);
return float4(depthValue, depthValue, depthValue, 1.0f);
}
return float4(0.0f, 0.0f, 0.0f, 1.0f);
}
ENDCG
}
}
FallBack "Diffuse"
} 转载请注明出处:http://blog.csdn.net/ylbs110/article/details/53366112
可以看到shader并不长,和上面的depth很像,我就不注释太多,多出的部分是用来分割画面的。算法的主要内容是判断当前像素的横坐标是处于RGB图还是深度图范围内(if (x < frame + RGBWidht)),如果在RGB图范围内,则将x,y坐标换算为RGB图像对应像素点的坐标,然后将该颜色返回。在深度图范围内也同样处理。最终效果如下:
