企业级mysql数据库集群实战——mysql的全同步复制(组复制)
1.mysql的全同步复制(组复制)的基础知识
组复制模型:
MySQL组复制是MySQL 5.7.17开始引入的新功能,为主从复制实现高可用功能
它支持单主模型和多主模型两种工作方式(默认是单主模型)
单主模型:从复制组中众多个MySQL节点中自动选举一个master节点,只有master节点可以写,其他节点自动设置为read only
当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master
多主模型:复制组中的任何一个节点都可以写,因此没有master和slave的概念
只要突然故障的节点数量不太多,这个多主模型就能继续可用
组复制原理:
复制组由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事务
但所有读写(RW)事务只有在冲突检测成功后才会提交。只读(RO)事务不需要在冲突检测,可以立即提交。
换句话说,对于任何 RW 事务,提交操作并不是由始发 server 单向决定的,而是由组来决定是否提交。准确地说,在始发 server 上,当事务准备好提交时,该 server 会广播写入值(已改变的行)和对应的写入集(已更新的行的唯一标识符)。然后会为该事务建立一个全局的顺序。最终,这意味着所有 server 成员以相同的顺序接收同一组事务。因此,所有 server 成员以相同的顺序应用相同的更改,以确保组内一致。
组复制能够根据在一组 server 中复制系统的状态来创建具有冗余的容错系统。因此,只要它不是全部或多数 server 发生故障,即使有一些 server 故障,系统仍然可用,最多只是性能和可伸缩性降低,但它仍然可用。server 故障是孤立并且独立的。它们由组成员服务来监控,组成员服务依赖于分布式故障检测系统,其能够在任何 server 自愿地或由于意外停止而离开组时发出信号。
总之,MySQL 组复制提供了高可用性,高弹性,可靠的 MySQL 服务
但是组复制的效率很低
当master节点写数据的时候,会等待所有的slave节点完成数据的复制,然后才继续往下进行
组复制的每一个节点都可能是slave
2.搭建实验环境
实验环境:(一主多从模式),一个master节点+两个slave节点
| 主机名 | IP | 功能 |
|---|---|---|
| server1 | 172.25.12.1 | master节点 |
| server2 | 172.25.12.2 | slave节点 |
| server3 | 172.25.12.3 | slave节点 |
这个实验是在之前的半同步做完之后做的,因此要准备实验环境
- (1)重新开启一台新的虚拟机server3

- (2)把server1上面的要安装的包传输给server3
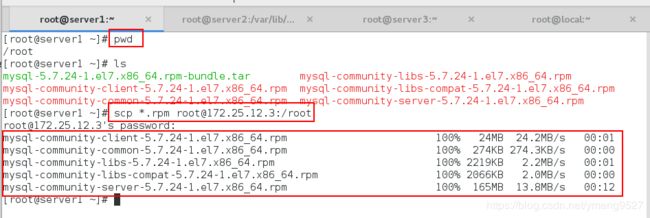
- (3)给server3安装数据库
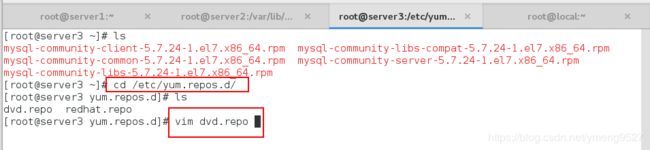




到这里基本的实验环境已经搭建完毕
3.开始实现组复制(全同步)
组复制(全同步复制),互相主从,互相为master和slave
就相当于一个集群,都可以作为master和slave
只需要在一个上面开启组复制即可,大家都是master
- (1)在server1上面进行设置(组同步的发起者)
查看一下UUID备用,三个节点的uuid使用同一个值,而且不能与三个节点自身的uuid相同

编辑配置文件/etc/my.cnf
vim /etc/mysql.cnf
先删掉之前实验加入的内容,然后加入下面的东西
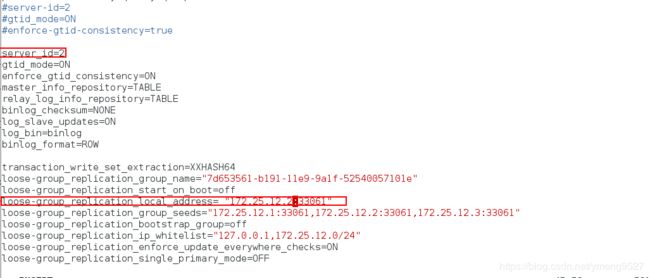
server_id=1第一个节点
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE #关闭binlog校验
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW#组复制依赖基于行的复制格式
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name="查出来的uuid"##可以看/var/lib/mysql/auto.cnf
loose-group_replication_start_on_boot=off
loose-group_replication_local_address= "172.25.12.1:33061"当前节点的ip
loose-group_replication_group_seeds="172.25.12.1:33061,172.25.12.2:33061,172.25.12.3:33061"
loose-group_replication_bootstrap_group=off
##插件是否自动引导,这个选项一般都要off掉,只需要由发起组复制的节点开启,并只启动一次,如果是on,下次再启动时,会生成一个同名的组,可能会发生脑裂
loose-group_replication_ip_whitelist="127.0.0.1,172.25.12.0/24"
loose-group_replication_enforce_update_everywhere_checks=ON
loose-group_replication_single_primary_mode=OFF#后两行是开启多主模式的参数


开启mysql服务 systemctl restart mysqld

mysql -uroot -pYan+123kou登录数据库
show databases;查看数据库
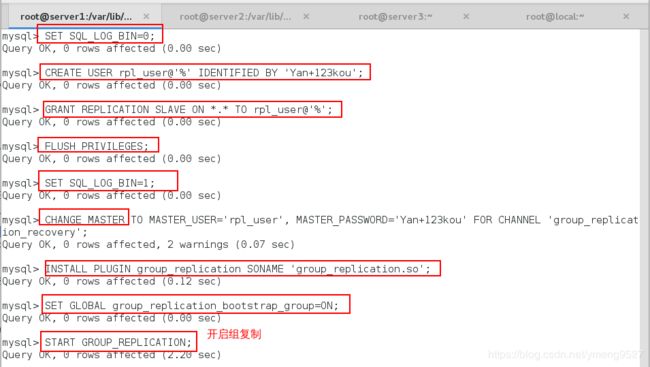
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'Yan+123kou';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;

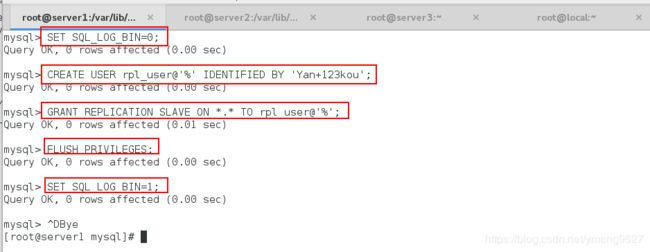
做完上述之后发现实验之前忘记清空环境了,删除数据目录下的所有数据
cd /var/lib/mysql
systemctl stop mysqld关闭服务
rm -rf *删除,防止后面不同步
systemctl start mysqld开启服务

继续配置数据库
查看临时密码grep password /var/log/mysqld.log复制密码
mysql -uroot -p粘贴密码,登录数据库
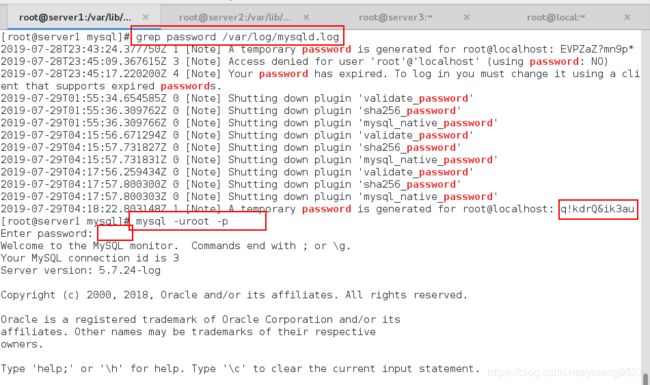
alter user root@localhost identified by 'Yan+123kou';修改密码
show databases;可以查看数据库

SET SQL_LOG_BIN=0;关闭二进制日志
CREATE USER rpl_user@'%' IDENTIFIED BY 'Yan+123kou';创建用户
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';用户授权
FLUSH PRIVILEGES;刷新用户授权表
SET SQL_LOG_BIN=1;开启二进制日志
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='Yan+123kou' FOR CHANNEL 'group_replication_recovery';配置用户
INSTALL PLUGIN group_replication SONAME 'group_replication.so';安装组复制插件
SET GLOBAL group_replication_bootstrap_group=ON;在第一个节点上要先打开一次
START GROUP_REPLICATION;开启组复制
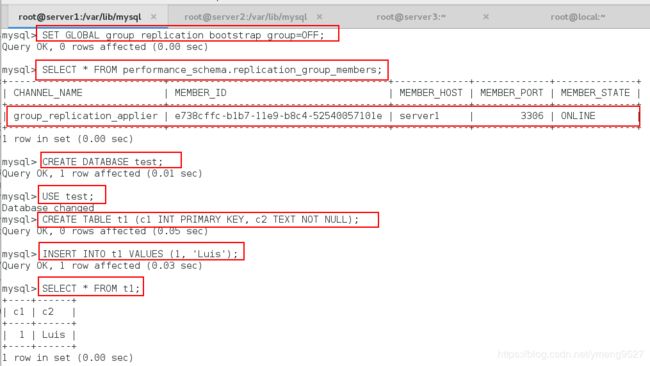
SET GLOBAL group_replication_bootstrap_group=OFF; 关闭组复制激活
SELECT * FROM performance_schema.replication_group_members;查看组的状态,当前只有一个节点在线
CREATE DATABASE test; 创建库
USE test;进入库
CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);创建表
INSERT INTO t1 VALUES (1, 'Luis');插入数据
SELECT * FROM t1;查看数据
- (2)在第二个节点server2上面进行配置
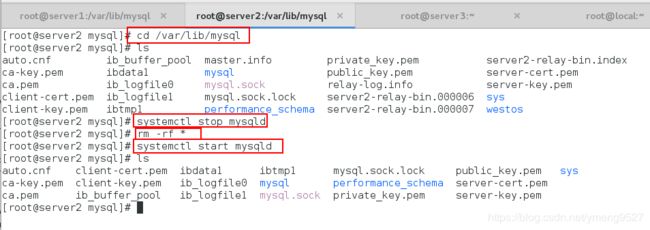
cd /var/lib/mysql
systemctl stop mysqld关闭mysql服务
rm -rf *删除数据目录的内容
systemctl start mysqld
编辑配置文件,开启服务 (修改的只有两个地方)
vim /etc/my.cnf
复制过来
systemctl start mysqld


假如你在重启服务时出现报错,有可能手残把配置文件写错了
找到错误后先执行一次关闭服务操作,然后删除mysql数据目录下的所有内容,再次尝试打开服务
查看临时密码
grep password /var/log/mysqld.log
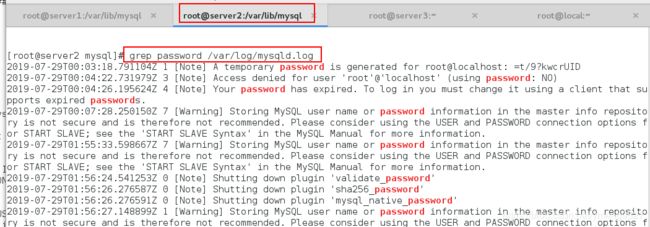
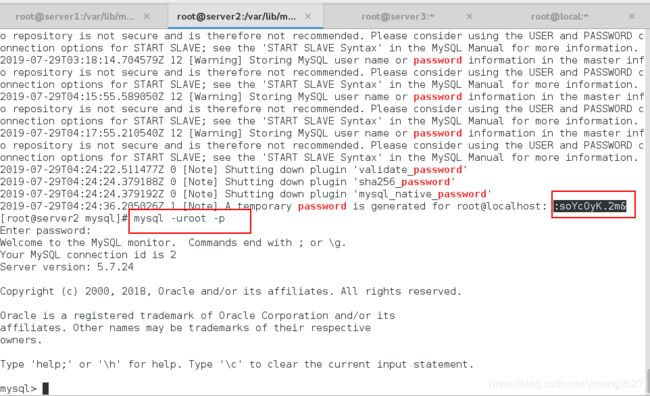
登陆数据库,配置
mysql -uroot -p
alter user root@localhost identified by 'Yan+123kou';
show databases;
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'Yan+123kou';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
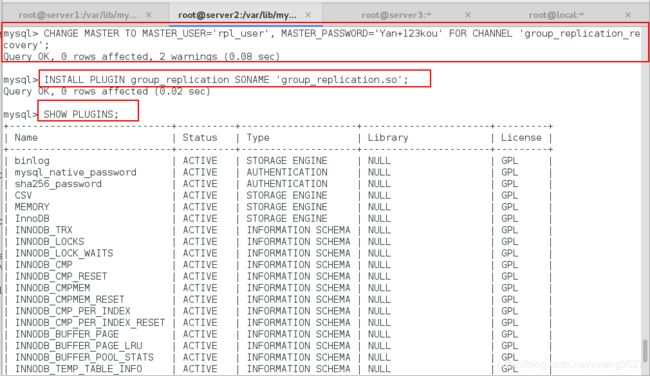
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='Yan+123kou' FOR CHANNEL 'group_replication_recovery';
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
SHOW PLUGINS;
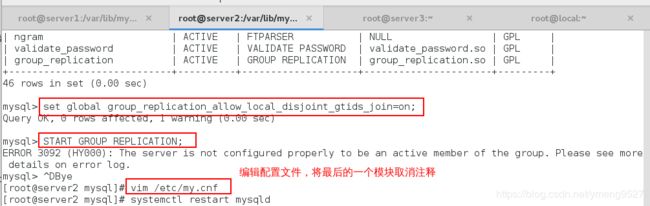
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;

change master的时候会报错,先将配置文件的最后一个模块注释掉,然后启动mysql服务
再次登录,尝试,就成功啦
开启组复制,报错,因为节点1已经写入数据,两端数据不一致


- (3)在第三个节点server3上面进行配置
编辑配置文件,开启服务
vim /etc/my.cnf
systemctl start mysqld


开启服务之前要保证数据目录里啥都没有

过滤临时密码,登陆数据库,配置
grep password /var/log/mysqld.log
mysql -uroot -p
alter user root@localhost identified by 'Yan+123kou';
show databases;
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'Yan+123kou';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='Yan+123kou' FOR CHANNEL 'group_replication_recovery';
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
SHOW PLUGINS;
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;




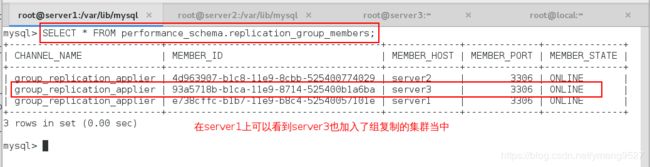
- (4)在server1上面:查看几个online
SELECT * FROM performance_schema.replication_group_members;
- (5)测试:在server3上面上传数据
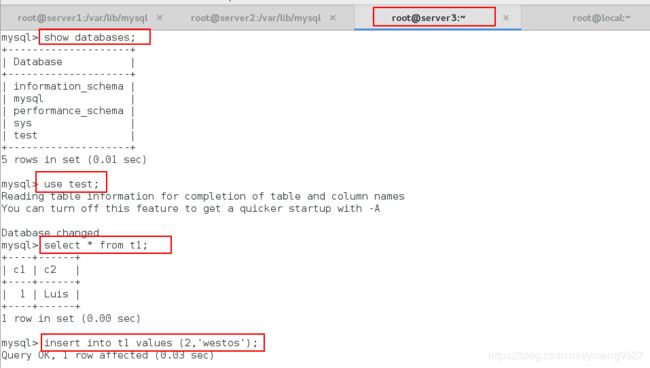

- (6)在server1和server2上面查看数据


可以看出,已经实现了组复制
可以在任意一个节点写数据,其他两个节点会进行组复制