MapReduce教程(一)基于MapReduce框架开发
MapReduce教程(一)基于MapReduce框架开发
1 MapReduce编程
1.1 MapReduce简介
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题。
MapReduce分成了两个部分:
1、映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
2、化简(Reducing)遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,
每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。
Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
MapReduce的伟大之处就在于编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
1.2 MapReduce运行原理

MapReduce论文流程图 - 1.1
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
1、MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
2、user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业3或者Reduce作业),worker的数量也是可以由用户指定的。
3、被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
4、缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
5、master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
6、reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
7、当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码
8、所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。

HadoopMapReduce模型实现图– 1.2
1.3 输入与输出
Map/Reduce框架运转在
框架需要对key和value的类(classes)进行序列化操作,因此,这些类需要实现Writable接口。另外,为了方便框架执行排序操作,key类必须实现 WritableComparable接口。
一个Map/Reduce作业的输入和输出类型如下所示:
(input)
1.4 Writable接口
Writable接口是一个实现了序列化协议的序列化对象。
在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。
| Java基本类型 |
Writable使用序列化大小 |
字节 |
| 布尔型 |
BooleanWritable |
1 |
| 字节型 |
ByteWritable |
1 |
| 整型 |
IntWritable |
4 |
| 整型 |
VIntWritable |
1-5 |
| 浮点型 |
FloatWritable |
4 |
| 长整型 |
LongWritable |
8 |
| 长整型 |
VLongWritable |
1-9 |
| 双精度浮点型 |
DoubleWritable |
8 |
| Text类型对应 |
java的string |
|
2 MapReduce编程
2.1 准备数据
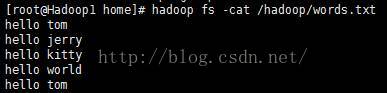
1、 在/home路径下,新建words.txt文档,文档内容如下:
hello tom
hello jerry
hello kitty
hello world
hello tom
2、 上传到hdfs文件服务器/hadoop目录下:
执行命令:hadoop fs -put /home/words.txt /hadoop/words.txt
执行命令:hadoop fs -cat /hadoop/words.txt
2.2 WordCount v1.0代码编写
WordCount是一个简单的应用,它可以计算出指定数据集中每一个单词出现的次数。
1、 在pom.xml引入Jar包:
org.apache.hadoop
hadoop-common
2.7.1
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.1
2、 WCMapper代码编写:
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
* 继承Mapper类需要定义四个输出、输出类型泛型:
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是每行文字中的单词"hello"
* ValueOut Mapper的输出数据的Value,这里是每行文字中的出现的次数
*
* Writable接口是一个实现了序列化协议的序列化对象。
* 在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。
* LongWritable类型:Hadoop.io对Long类型的封装类型
*/
public class WCMapper extends Mapper {
/**
* 重写Map方法
*/
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
// 获得每行文档内容,并且进行折分
String[] words = value.toString().split(" ");
// 遍历折份的内容
for (String word : words) {
// 每出现一次则在原来的基础上:+1
context.write(new Text(word), new LongWritable(1));
}
}
}
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* 继承Reducer类需要定义四个输出、输出类型泛型:
* 四个泛型类型分别代表:
* KeyIn Reducer的输入数据的Key,这里是每行文字中的单词"hello"
* ValueIn Reducer的输入数据的Value,这里是每行文字中的次数
* KeyOut Reducer的输出数据的Key,这里是每行文字中的单词"hello"
* ValueOut Reducer的输出数据的Value,这里是每行文字中的出现的总次数
*/
public class WCReducer extends Reducer {
/**
* 重写reduce方法
*/
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable i : values) {
// i.get转换成long类型
sum += i.get();
}
// 输出总计结果
context.write(key, new LongWritable(sum));
}
}
4、 WordCount代码编写:
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 创建job对象
Job job = Job.getInstance(new Configuration());
// 指定程序的入口
job.setJarByClass(WordCount.class);
// 指定自定义的Mapper阶段的任务处理类
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 数据HDFS文件服务器读取数据路径
FileInputFormat.setInputPaths(job, new Path("/hadoop/words.txt"));
// 指定自定义的Reducer阶段的任务处理类
job.setReducerClass(WCReducer.class);
// 设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 将计算的结果上传到HDFS服务
FileOutputFormat.setOutputPath(job, new Path("/hadoop/wordsResult"));
// 执行提交job方法,直到完成,参数true打印进度和详情
job.waitForCompletion(true);
System.out.println("Finished");
}
}2.3 生成JAR包
1、 选择hdfs项目->右击菜单->Export…,在弹出的提示框中选择Java下的JAR file:

2、 设置导出jar名称和路径,选择Next>:
3、 设置程序的入口,设置完成后,点击Finish:

4、 成生wc.jar如下文件,如下图:

2.4 执行JAR运行结果
1、 在开Xft软件,将D:盘的wc.jar上传到Linux/home路径下:

2、 执行命令
切换目录命令:cd /home/
执行JAR包命令:hadoop jar wc.jar
3、 查看执行结果
执行命令:hadoop fs -ls /hadoop/wordsResult

执行命令:hadoop fs -cat /hadoop/wordsResult/part-r-00000

——厚积薄发(yuanxw)