python入门基础(8)——操作文件与目录
文件操作在图形界面的操作系统下,实现起来很简单,只需要右键粘贴复制、新建、拖拽等等即可(比如windows系统中,我们常用的电脑界面)。
但是在Python代码中,我们如何实现呢,下面让我们来看一下吧!
1、基本操作
这些基本操作都被归纳到了一个名为os模块内,我们只需将其导入,然后直接调用操作系统提供的接口函数即可:
import os #导入模块
print(os.name) #这里输出所属操作系统的名称
print(os.environ) #可以查看环境变量(1)上面说的操作系统的名称,这里是特指,比如:
- 输出posix,则说明系统是#nix族(也就是各种Unix系统,常见的比如Unix和linux)
- 如果输出nt,表示是win都是系统
(2)这里所说的环境变量,其实就是电脑的环境变量,也就是右键“我的电脑”,然后点击属性,里面的系统属性(通常安装Eclipse或者其他软件时,都需要配置的环境变量),这里输出的是一个字典,变量名为key(字符串),变量值为values(也是字符串),其输出 结果如下图所示:

2、操作文件与目录
(1)查看、创建和删除目录操作
import os
# 当前目录的绝对路径
print(os.path.abspath('.'))
# 比如这里返回:'E:\Python编程\test'
# 在某个目录下创建一个新目录,
# 首先把新目录的完整路径表示出来,下面这行代码没有什么屌用,只是合成路径字符串的:
new_path = os.path.join(os.path.abspath('.'), 'Pictures')
# 这里你得到的是一个字符串,代表了新的文件夹是这个位置:E:\Python编程\test\Pictures\
# 自己也可以拼起来,但是怕不同操作系统下的区分符问题,最好是用OS接口
# 但是你还并没有创建任何的文件
# 需要用mkdir创建:
os.mkdir(new_path)
# 同理,删除一个文件夹
os.rmdir(new_path)这里的创建和删除操作,其实和linux系统下的文件操作是一致的,所有很人都说用Python编代码和在linux上操作是一致的
上面是我创建的文件的操作,aaaa.py是我当前的文件,而上面的Pictures则是我新创建的文件
注意:上面提到的合并文件路径的操作,是很重要的,所以上面用了很多解释性的文字描述
同样的,要拆分路径的时候,也不要直接去拆字符串,而是要通过os.path.split()函数,这样可以把一个路径拆分成两部分,后一部分总是最后级别的目录或文件名:
os.path.split('E:\Python编程\test\Pictures.txt')
# ('E:\Python编程\test\', 'Pictures.txt')得到文件路径的扩展名:
os.path.splitext('E:\Python编程\test\Pictures.txt')
# ('E:\Python编程\test\Pictures', '.txt')(2)文件重命名
os.rename('JAV-001.avi', '学习资料')(3)删除文件
os.remove('学习资料')(4)复制文件
注意:在os模块中,并没有提供直接的复制文件操作,因为复制操作并不是由操作系统提供的系统调用,但是我们可以利用文件读取操作,读入一个文件,然后再写入一个文件,以此来达到复制的目的。
当然,提供文件操作函数接口的库,并不止os模块一个,还有其他的,我们可以调用shutil来实现文件复制操作,它可以算是os模块的补充,提供copyfile()方法,来复制你的文件:
import shutil
shutil.copyfile('E:\song.txt', 'E:\工作\song.txt')(5)列出当前目录所有目录
import os
list = [x for x in os.listdir('.') if os.path.isdir(x)] #这里会将所有目录形成一个列表
print(list)输出结果如下:

上面列出的是所有目录,而不是所有文件,注意这个说法
(6)列出当前目录下,所有文件(.py文件)
import os
list = [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
print(list)输出结果:

3、序列化与反序列化
(1)什么是序列化
程序在运行过程中,所有变量都是存储在内存中的,但是一旦程序运行完毕,所有变量都会被回收(占用的内存被回收),但是往往有时候,我们需要永久保留这些变量,以便下次运行时,继续用,节省大量的时间,这就需要将这些变量保存到磁盘中,这样下次我们就可以直接从磁盘中读取相关数据了。
我们将变量从内存中变成可以存储或传输的过程称之为序列化,在Python中叫做pickling,在其它语言中也称之为 serialization、marshaling、flattening等等,说的都是一个意思。 反之,则为反序列化,称之为unpickling,把变量内容从序列化的对象重新读取到内存中。
(2)序列化:
import pickle
# 此处定义一个dict字典对象
d = dict(name='思聪', age=29, score=80) #一共3个key-value值
str = pickle.dumps(d) # 调用pickle的dumps函数进行序列化处理
print(str)
# 你可以看看它长什么样子
# 定义和创建一个file文件对象,设定模式为wb
f = open('dump.txt', 'wb')
# 将内容序列化写入到file文件中
pickle.dump(d, f)
f.close() # 最后关闭掉文件资源注意:上面的wb模式(不懂可以参考我的上一篇文件读取博客)是可以自动创建文件的,即如果dump.txt不存在,在写入的时候,它会自动创建该文件,是该你们的str输出为:

很显然,这种编码我们是看不懂的
(3)反序列化
import pickle
# 从之前序列化的dump.txt文件里边读取内容
f = open('dump.txt', 'rb') # 设定文件选项模式为rb
d = pickle.load(f) # 调用load做反序列处理过程
f.close() # 关闭文件资源
print(d)
print('name is %s' % d['name'])这里的反序列化,就是将刚刚生成的一堆看不懂的编码,转换成Python可以看得动的object,下面是输出结果:
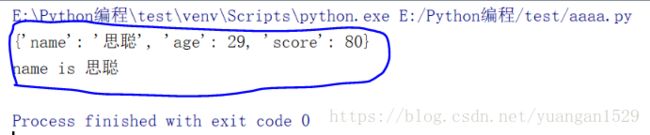
这样,我们是不是就都可以看懂了
注意:Python2和Python3里面的pickle是不一样的,上面的pickle是Python3的(我个人是建议使用Python3的),如果你搞不懂里面的差别,可以百度,或者直接调用下面的的代码:
try:
import cPickle as pickle
except ImportError:
import pickle上面是无论是哪种Python格式,都可以导入
(4)用JSON实现序列和反序列化
在(2)中,我们可以看到序列完了以后的编码,我们也是看不懂的,只有Python自身可以将其来回转换,这对于我们来说是非常不方便的(比如,我们只想把数据保存下来,然后在Eclipse上运行),为了方便我们以后的文件操作,我们可以用Json(读作:摘森)来做序列化处理,Python的数据结构和Json有非常完美的兼容(不懂Json的可以百度一波):
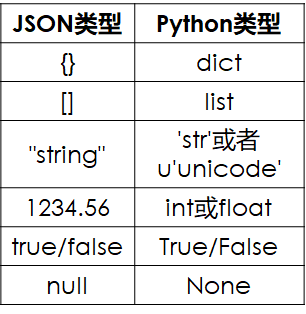
如果你有一个比较结构化的数据想要序列化,并且想要别的地方别的语言也能看得懂。那么你可以用JSON来做:
import json
# 定义dict字典对象
d1 = dict(name='小王', age=20, score=80)
str = json.dumps(d1) # 调用json的dumps函数进行json序列化处理
print(str)
# 调用json的loads函数进行反序列化处理
d2 = json.loads(str)主要参考资料来自:Python入门基础(七月在线学院的)
具体视频和文件材料,在我之前的博客中有分享