知识图谱简介(二)——关键技术
在知识图谱的简介(一)中已经描述过知识图谱,在本文中即对于知识图谱的一些关键技术做简要阐述。
大规模知识库的构建与应用需要多种技术的支持。依据知识图谱构建的过程,主要分为四个部分:信息抽取、知识表示、知识融合、知识推理。
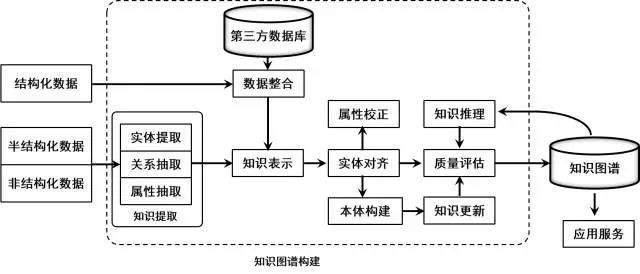
知识提取
知识提取主要是面向开放的链接数据,通常典型的输入是自然语言文本或多媒体内容文档(图像或者视频)等。然后通过自动化或者半自动化的技术抽取出可用的知识单元,知识单元主要包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。
实体抽取
实体抽取也称为命名实体学习(named entity learning)或命名实体识别(name entity recognition),指的是从原始数据语料中自动识别出命名实体。这一步是知识图谱中最为基础与关键的一步,直接影响到知识图谱构建的质量。抽取实体的方法分为4种:
基于百科或垂直站点提取:基于爬取技术在百科类或垂直站点标题和链接中提取实体名。
基于规则与词典的实体提取方法:早期的实体抽取式在限定文本领域、限定语义单元类型的条件下,通过基于规则与词典的方法,抽取文本中的实体。
基于统计机器学习的实体抽取方法:相关研究人员在规则与词典提取的方法上,引入监督学习算法用于命名实体抽取。
面向开放域的实体抽取方法:通过少量文本实例建立特征模型,再通过这个特征模型应用于新的数据集得到新的命名实体。
语义类抽取
语义类抽取是指从文本中自动抽取信息来构造语义类并建立实体和语义类的关联。这里简要介绍一种语义抽取方法,包含三个模块:并列相似度计算、上下位关系提取,以及语义类生成。
并列相似度计算:并列相似度计算的是词与词之间的相似性信息,例如三元组(苹果,梨子,s1)表示苹果和梨子并列相似度s1,s1较高说明他们具有并列关系,可能是同一个语义类水果。
上下位关系提取:该模块从文档中抽取词的上下位关系信息,生成(上义词,下义词)数据对,例如(国家,中国)、(深圳,城市)。
语义类生成:该模块包括聚类和语义类标定两个子模块。聚类的结果决定了要生成哪些语义类以及每个语义类包含哪些实体,而语义类标定的任务是给一个语义类附加一个或者多个上位词作为其成员的公共上位词。这个模块依赖于并列相似性和上下位关系信息来进行聚类和标定。
属性和属性值抽取
属性提取的任务是为每个本体语义类构造属性列表(如城市的属性包括面积、人口、所在国家、地理位置等),而属性值提取则为一个语义类的实体附加属性值。属性和属性值的抽取能够形成完整的实体概念的知识图谱维度。常见的属性和属性值抽取方法包括从百科类站点中提取,从垂直网站中进行包装器归纳,从网页表格中提取,以及利用手工定义或自动生成的模式从句子和查询日志中提取。例如电商平台中某个产品的页面,中包含了大量实体的属性信息,可以通过一定规则模板来提取属性。
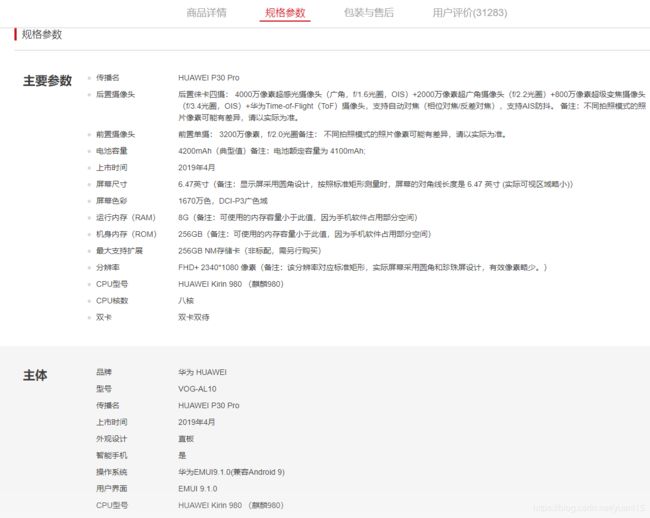 商品属性
商品属性
关系抽取
关系抽取是解决实体语义链接的问题,关系的基本信息包括参数类型、满足次关系的元组模式等。早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后实体间的关系模型逐渐取代了人工预定义的语法与规则。最新的方法是面向开放域的信息抽取框架,通过监督学习获得抽取器,来抽取实体间的关系。
知识表示
传统的知识表示方法主要是以RDF(Resource Description Framework资源描述框架)的三元组SPO(subject,property,object)来符号性描述实体间的关系。这种方法简单直观,但是在计算效率、数据稀疏性等方面面临诸多问题,近年来以深度学习为代表的表示学习技术取得了重要进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。这里简要列举几个表示模型,不做过多描述:
知识表示学习的代表模型有距离模型、单层神经网络模型、双线性模型、神经张量模型、矩阵分解模型、翻译模型等。详细可以参考清华大学刘知远的知识表示学习研究进展。
距离模型
首先将实体用向量表示,然后通过关系矩阵将实体投影到与实体关系对的向量空间中, 最后通过计算投影向量之间的距离来判断实体间已经存在的关系的置信度。
单层神经网络模型
单层神经网络的非线性模型为知识库中每个三元组(h,r,t)定义了以下形式的评价函数:

式中向量Ut是关系r的向量化表示,函数g(x)为tanh(x)函数,Mr,1和Mr,2是通过关系r定义的两个矩阵。
知识融合
提取了知识后,由于知识来源广泛,这些知识常常呈现出分散、异构、自治的特点,还有冗余、噪音、不确定、非完备的特征,清洗数据并不能解决这些问题,所以必须对知识进行融合和验证。来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想融合,形成高质量的知识库。在引入新的知识时,需要判断新知识是否正确,与已有知识是否一致,这里可以用到的证据是权威度、冗余度、多样性、一致性。
知识推理
所谓知识推理就是通过各种方法获取新的知识或者结论,这些知识和结论满足语义,其具体任务可分为可满足性、分类、实例化。目前知识推理的研究主要集中在针对知识图谱缺失关系的补足,即挖掘两个实体之间隐含的语义关系。
1.可满足性可体现在本体概念上,即本体可满足性是检查一个本体是否可满足某一个模型定义。例如语义类Man和Woman不可能有交集,那么不存在一个人Mike既属于Man又属于Woman。
2.分类的概念可以举如下例子:如果Mother是Women的子集,由于Women是Person子集,那么可以推理得出Mother是Person的子集这个新类别关系。
3.实例化的例子也可以如上举得,Marry是Mother的实例,由于Mother是Women的子集,那么可知Women需创建一个新的实例。