使用keras版本的yoloV3训练并在VOC数据集上测试
yoloV3主页:https://pjreddie.com/darknet/yolo/
keras-yolo3代码:https://github.com/qqwweee/keras-yolo3
VOC数据集:http://host.robots.ox.ac.uk/pascal/VOC/
一、环境需求:
tensorflow
keras
(编译运行时按照错误提示pip install 相应库文件即可)
二、Demo:
1、下载代码:
git clone https://github.com/qqwweee/keras-yolo32、下载yoloV3权重文件:
https://pjreddie.com/media/files/yolov3.weights3、将darknet下的yolov3配置文件转换成keras适用的h5文件:
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
4、运行预测图像程序(预测视频程序跳过):
python yolo.py输入需要预测的图片路径即可,示例如下,可以看到结果还是蛮准确的,但对于某些小目标(如图片左半部分)仍然未能很好地检测出来:

三、训练:
1、将VOC数据集放在代码同一目录下,然后先生成需要进行训练的txt文件,包括图片路径、类别和bbox,一张图片有多个目标时用' '隔开,根据使用VOC数据集的年份修改voc_annotation.py文件中的sets,根据需要训练的类别修改classes(如注释中只使用person类)。
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# classes = ['person']
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
运行生成txt文件程序,根据sets得到三个不同的txt文件,方便用于做训练、验证和测试:
python voc_annotation.py2、修改train.py中的annotation_path为刚刚生成的txt文件,data_path是根据txt提供的训练图像提取出的数据信息并保存为了npz格式(注意,如果需要更换训练数据的话,需要删除上一次生成的npz文件,或者在给get_training_data函数传参时设置load_previous=False),output_path是当前训练的模型保存路径,log_dir记录了每一次迭代生成的模型,classes_path是需要训练的目标种类,根据上一步修改过的classes调整(如注释中选择的txt文件中只包含自己需要训练的类别),anchors_path是锚点文件(因还不太了解所以没有改过)。
annotation_path = '2007_train.txt'
data_path = 'train.npz'
output_path = 'model_data/my_yolo.h5'
log_dir = 'logs/000/'
#classes_path = 'model_data/my_classes.txt'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/yolo_anchors.txt'同时,在训练时还会存在这样的情况:可能数据集中某些图像中不包含你想要训练的目标,那么可以在生成txt文件时就筛除掉,或者在读取训练数据时跳过没有数据的那一行,这里作者选择后者,修改train.py中get_training_data函数:
with open(annotation_path) as f:
for line in f.readlines():
line = line.split(' ')
# skip the rows contain no target
if len(line) <= 1:
continue
filename = line[0]
image = Image.open(filename)这里需要注意的是,如果想要训练某一类或某几类特定的目标类别,必须要同时修改以上两步中voc_annotation.py和train.py相应的位置,否则可能会报维数不符的错误。
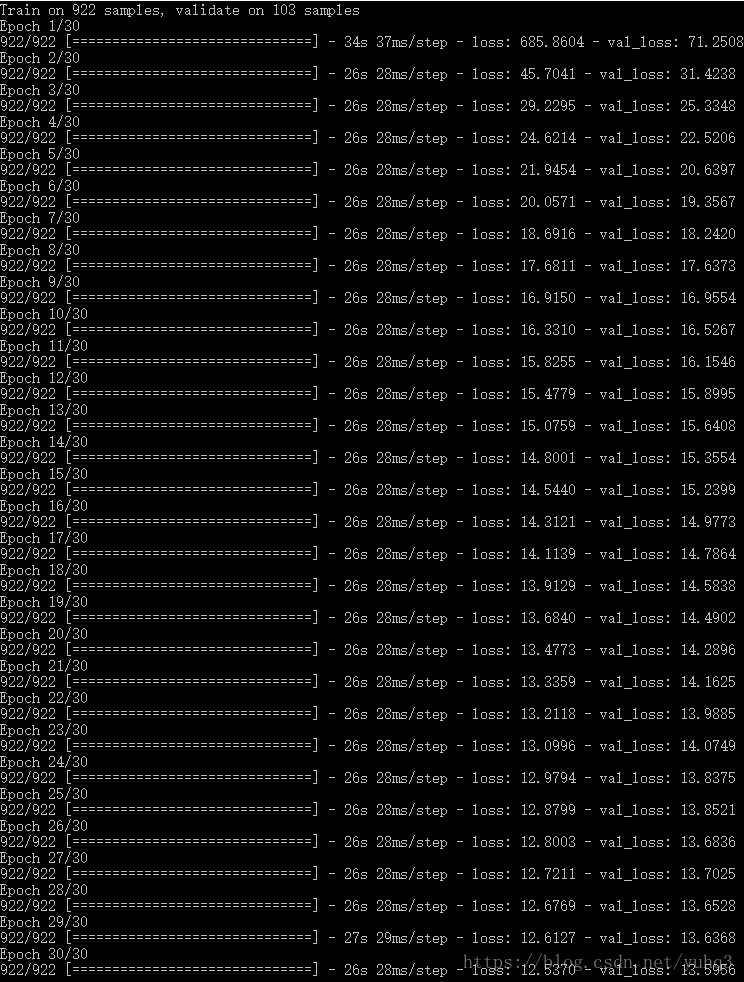
修改完成后,开始训练:
python train.py随着epoch迭代,会得到越来越小的loss,直到loss达到某一阈值自动停止,或者epoch达到上限也会停止。可以在train.py中的train函数中修改预设的epochs。
3、修改yolo.py,使用自己训练的模型预测图像:
#self.model_path = 'model_data/yolo.h5'
self.model_path = 'model_data/my_yolo.h5'
self.anchors_path = 'model_data/yolo_anchors.txt'
#self.classes_path = 'model_data/coco_classes.txt'
self.classes_path = 'model_data/my_classes.txt'因为只在2007VOC训练集上进行30次的迭代训练,所以得到的模型效果不算好,在VOC测试图像上的预测效果还可以,但不够精确。如果测试图像更大,差的预测结果就比较明显了,因此需要更多训练数据来训练自己的模型。

四、在VOC2007上评估MAP
1、具体过程参考:YOLO在VOC2007数据集计算mAP 备忘
2、输出文件格式要求:Pascal VOC 数据集介绍
五、其他:
1、如果想要使用自己的权重继续训练,在train.py中的create_model函数中修改weights_path。如果不想使用预训练的权重,设置传给create_model函数的参数load_pretrained=False。