彻底理解Python中的"指针"
目录
一、两个Python例子引发的思考
二、Python中的不可变对象和可变对象
三、C语言中定义变量的过程
四、Python中定义对象的过程
五、总结
参考链接:
学过C,C++语言的同学都知道一个重要的概念——指针。
Python中有指针的概念吗?我查了许多资料,没人认明确地说Python中有“指针”这一定义。在我看来,Python中虽然没有“指针”的定义,但是却随处可见“指针”的影子。不过这里的“指针”并不完全等同于c语言中的指针,只能是加引号的“指针”。
一、两个Python例子引发的思考
第一个例子:
# --coding=utf-8--
# 第一个例子
# 方法预期功能:将参数发送出去(这里简化为打印)
def send(param):
print('send: ', param)
# 方法预期功能:把test_list删掉最后一个元素发送出去,也就是['a']
def fun1(param):
print('run fun1...')
param.pop()
send(param)
# 方法预期功能:把test_list增加一个元素'c'发送出去,也就是['a', 'b', 'c']
def fun2(param):
print('run fun2...')
param.append('c')
send(param)
# 方法预期功能:把test_list发送出去,也就是['a', 'b']
def fun3(param):
print('run fun3...')
send(param)
if __name__ == '__main__':
test_list = ['a', 'b']
fun1(test_list)
fun2(test_list)
fun3(test_list)我预期的结果为:
run fun1...
send: ['a']
run fun2...
send: ['a', 'b', 'c']
run fun3...
send: ['a', 'b']
实际的结果为:
run fun1...
send: ['a']
run fun2...
send: ['a', 'c']
run fun3...
send: ['a', 'c']
按照代码表面来理解,三个函数只是对传进来的“形参”param进行了改变,对原来的“实参”test_list并没有影响,所以每个函数传进去的test_list应该都是 ['a', 'b']。可是从结果来看,每个函数里的“形参”被改变后,外面的“实参”也跟着改变了。在原来的代码基础上加几条打印,可以看到就是这样。
if __name__ == '__main__':
test_list = ['a', 'b']
print('test_list:', test_list)
fun1(test_list)
print('test_list:', test_list)
fun2(test_list)
print('test_list:', test_list)
fun3(test_list)
print('test_list:', test_list)test_list: ['a', 'b']
run fun1...
send: ['a']
test_list: ['a']
run fun2...
send: ['a', 'c']
test_list: ['a', 'c']
run fun3...
send: ['a', 'c']
test_list: ['a', 'c']
所以上面例子中三个函数里的param和test_list其实是一个对象,fun1里的pop和fun2里的append都是操作的同一个变量(对象),也就是说传递到三个函数中的参数是test_list的“地址”。类似C语言中,函数的参数为指针类型。
第二个例子:
# --coding=utf-8--
# 第二个例子
# 方法预期功能:将参数发送出去(这里简化为打印)
def send(param):
print('send: ', param)
# 方法预期功能:把test_value的值加上1发送出去,也就是2
def fun1(param):
print('run fun1...')
param += 1
send(param)
# 方法预期功能:把test_value的值减去1发送出去,也就是0
def fun2(param):
print('run fun2...')
param -= 1
send(param)
# 方法预期功能:把test_value发送出去,也就是1
def fun3(param):
print('run fun3...')
send(param)
if __name__ == '__main__':
test_value = 1
# print('test_value:', test_value)
fun1(test_value)
# print('test_value:', test_value)
fun2(test_value)
# print('test_value:', test_value)
fun3(test_value)
# print('test_value:', test_value)实际输出结果:
run fun1...
send: 2
run fun2...
send: 0
run fun3...
send: 1
这次的结果和上次不太一样,结果表明三个函数里的param和test_value并不是一个对象,fun1里的加1和fun2里的减1操作之后,并没有影响test_value的值,也就是说传递到三个函数中的参数是test_list的“值”(的拷贝)。那么什么时候传的是指针,什么时候传的是值呢?其实只要了解一下Python中创建对象的具体过程,问题就迎刃而解了。
二、Python中的不可变对象和可变对象
众所周知,Python中一切皆对象,每个对象至少包含三个数据:引用计数、类型和值。引用计数用于Python的GC机制,类型用于在CPython层运行时保证类型安全性,值就是对象关联的实际值。
Python对象分为不可变对象和可变对象。可变对象可以修改,上面第一个例子中的test_list(list类型)就属于可变对象,不可变对象无法更改,类似C语言中加了const修饰,上面第二个例子中的test_value(int类型)就属于不可变对象。
不可变对象:int(整形)、str(字符串)、float(浮点型)、tuple(元组)
可变对象:dict(字典)、list(列表)、 set(集合)
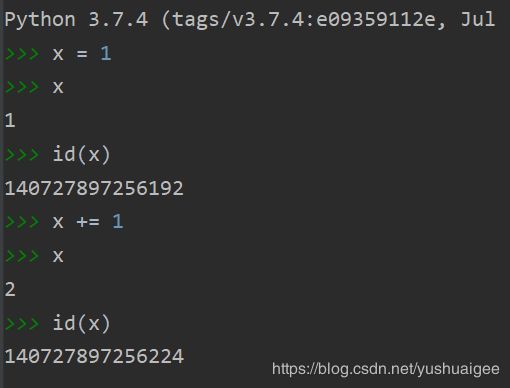
这里 x += 1 看似更改了 x 的值,实际上已经改变了ID,所以是新建了一个值。

同样str类型的v可以重新赋值,但是不能更改元素。这就类似于C语言中加了const修饰的数组,不能更改它的内容,但是你可以将原来指向它指针改为指向别人。
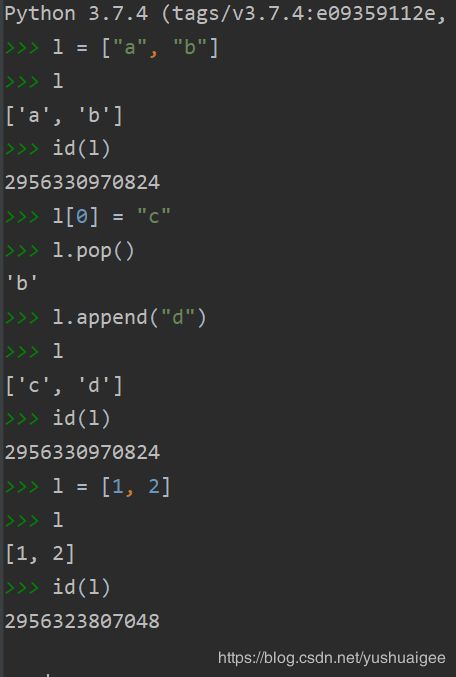
可变对象的情形就不一样了,可以任意更改元素。ID不会变,直到重新赋值:
三、C语言中定义变量的过程
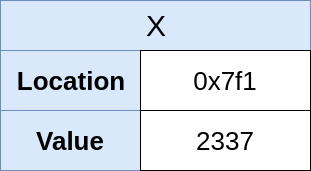
例如:int x = 2337;
在C语言中,这行代码的执行分为三步:
1. 为整数分配足够的内存
2. 将值2337分配给该内存位置
3. 将x指向该值
简化的内存视图如下:
如果将x重新赋值:x = 2338;
上面的代码为变量 x 重新分配了一个新值2338,从而覆盖了以前的值2337。这意味着在这里变量 x 是可变的。更新简化的内存视图如下:

x 的地址并没有变,这意味着在C语言中定义变量时, x 它代表的是一个内存位置,可以理解为一个空盒子,而关键字 int 就确定了这个盒子的大小,我们可以将值2337放进这个盒子,也可以将2338放进这个盒子,因为它们是 int 型的值。
此时再引入一个新的变量:int y = x;
这时会创建一个新的 int 型的盒子 y ,再把 x 中的值赋值过来。在内存中是这样:

两个变量除了值都是 2338 之外,其他并没有任何关系。任意更改其中一个变量的值,另一个不会受到任何影响。
例如更改 y 的值为 2339:y = 2339;

四、Python中定义对象的过程
再看一下同样的代码,在Python中运行的情况。严格上来讲Python中的变量和C中的变量的意义不是等价的,Python中的变量或许叫做“名称”会更加贴切一点,看了下面的分析就会有所体会。
定义一个变量 x:x = 2337
与C类似,上面的代码在执行过程中会分解为5步:
1. 创建一个PyObject
2. 将PyObject的类型设置为整数型
3. 将PyObject的值设置为2337
4.创建一个变量(名称)x
5.将 x 指向新建的PyObject
6.将该PyObject的引用计数加 1
简化的内存视图如下:

如果将x重新赋值:x = 2338
上面这行代码在Python中的执行过程和在C中有很大不同,具体过程是这样:
1. 创建一个新的PyObject
2. 将PyObject的类型设置为整数型
3. 将PyObject的值设置为2338
4.将 x 指向新的PyObject
5.将新的PyObject的引用计数加 1
6.将旧的PyObject的引用计数减 1
内存中的情况如下:
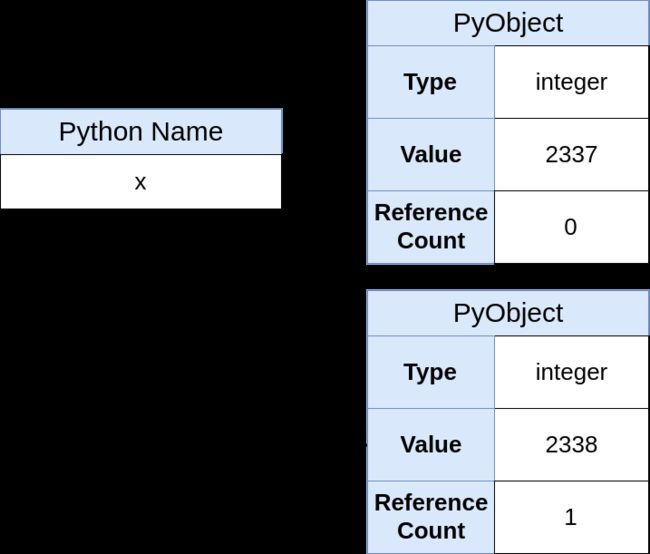
引用计数位为0的原对象,将会被Python的内存管理机制销毁。这说明 x 它不是一个空盒子。
如果是这样呢:y = x
在内存中会新建一个新名称(变量),但不用创建一个新对象,原来对象的引用计数变成了 2:

现在 x 和 y 都指向同一个对象,但是他们还是不可改变对象。
比如如果执行: y += 1
这和执行 y = 2339 的过程是一样的:

这样看来,我们在Python中不是新建变量,而是新建名称并绑定到变量,所以说Python中的变量和C中的变量的意义不是等价的。当然这只是不可变对象的情况,如果 x, y 是 list 这种类型可变对象,上面的代码改为:
x = [1] # 新建一个PyObject1,名称为x,值为 [1],引用计数为 1
x = [2] # 新建一个PyObject2,名称x指向PyObject2,值为 [2],引用计数为1,PyObject1引用计数为0(回收)
y = x # 新建一个名称y,指向PyObject2,值为 [2],引用计数改为 2
y.append(3) # PyObject2的值改为 [2,3],名称x和y依然都指向PyObject2,引用计数还是2
前三行代码执行时,内存情况和不可变对象是一样的,但是最后一行执行时,将不会新建一个新的对象,因为 list 是可变对象,它可以对象的值改成[2,3] , id还是原来的id(其实这里的id和C语言中的地址也不是完全等价的,只是类似)。这就是Python中可变对象和不可变对象的不同之处。
五、总结
综上所述,由Python中的两个例子产生Python中是否像C语言一样也有指针的疑惑,研究了Python中可变对象和不可变对象的区别,接着对比C语言和Python在创建变量时的不同。我以前总是想把Python和C语言联系起来,总是想将C语言中已有的定义和用法套用在Python上,这样虽然方便理解,但是也会产生许多困惑。随着对Python的底层探究地越来越多,我越来越发现Python中有许多新的东西,不能将它们简单地等价于C语言中已有的术语。
回到最开始的问题,Python中有“指针”吗?我的理解是,如果此处的指针是指C语言中的指针,那么答案是没有,如果这里的指针指的是C语言中的指针思想,那么答案是有。
参考链接:
- Pointers in Python: What's the Point? (Logan Jones) :https://realpython.com/pointers-in-python/#real-pointers-with-ctypes