Hive从入门到放弃
1 Hive基本概念
1.1 什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序,执行流程如下:
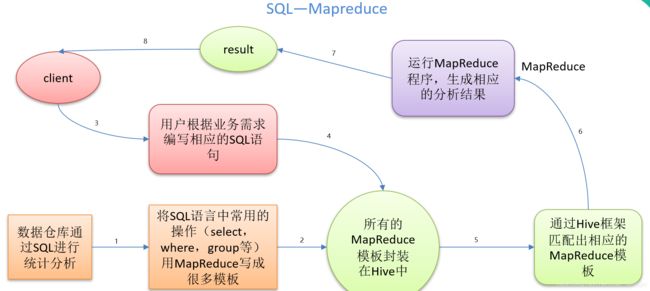
- 1)Hive处理的数据存储在HDFS
- 2)Hive分析数据底层的实现是MapReduce
- 3)执行程序运行在Yarn上
1.2 Hive的优缺点
1.2.1 优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
1.2.2 缺点
- Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长 - Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
1.3 Hive架构原理
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
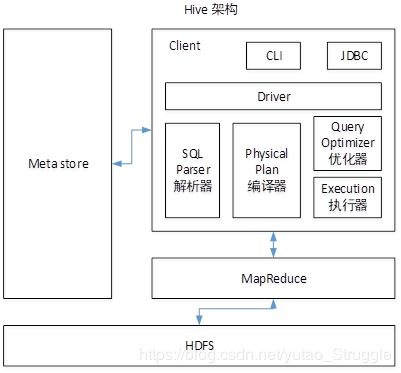
- Client:用户接口,提供CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
- Metastore:元数据,包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- Hadoop:使用HDFS进行存储,使用MapReduce进行计算。
- Driver:驱动器
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
1.4 Hive和数据库对比
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性
1.4.1 查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
1.4.2 数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
1.4.3 数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
1.4.4 索引
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
1.4.5 执行
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
1.4.6 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
1.4.7 可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
1.4.8 数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
2 Hive安装
2.1 安装地址
- Hive官网地址
- 文档查看地址
- 下载地址
- github地址
2.2 Hive安装部署
1.解压apache-hive-1.2.2-bin.tar.gz
[root@iZnq8v4wpstsagZ software]# tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /opt/module
2.修改/opt/module/apache-hive-1.2.2-bin/conf目录下hive-env.sh.template名称为hive-env.sh
[root@iZnq8v4wpstsagZ conf]# mv hive-env.sh.template hive-env.sh
3.配置hive-env.sh文件
[root@iZnq8v4wpstsagZ conf]# vim hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/module/hadoop-2.7.7
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/module/apache-hive-1.2.2-bin/conf
4.hadoop集群配置
#在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
[root@iZnq8v4wpstsagZ hadoop-2.7.7]$ bin/hadoop fs -mkdir /tmp
[root@iZnq8v4wpstsagZ hadoop-2.7.7]$ bin/hadoop fs -mkdir -p /user/hive/warehouse
[root@iZnq8v4wpstsagZ hadoop-2.7.7]$ bin/hadoop fs -chmod g+w /tmp
[root@iZnq8v4wpstsagZ hadoop-2.7.7]$ bin/hadoop fs -chmod g+w /user/hive/warehouse
2.3 MySQL安装(不需要可跳过)
Hive默认使用采用自带的derby数据库存储Metastore,内嵌的derby数据库仅支持单连接,推荐使用MySQL存储Metastore。
- MySQL的安装可参见MySQL笔记
- 将mysql驱动程序copy到/opt/module/apache-hive-1.2.2-bin/lib/目录下
- 配置metastore存储到MySQL
[root@iZnq8v4wpstsagZ conf]# touch hive-site.xml [root@iZnq8v4wpstsagZ conf]# vim hive-site.xml<configuration> <property> <name>javax.jdo.option.ConnectionURLname> <value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=truevalue> <description>JDBC connect string for a JDBC metastoredescription> property> <property> <name>javax.jdo.option.ConnectionDriverNamename> <value>com.mysql.jdbc.Drivervalue> <description>Driver class name for a JDBC metastoredescription> property> <property> <name>javax.jdo.option.ConnectionUserNamename> <value>rootvalue> <description>username to use against metastore databasedescription> property> <property> <name>javax.jdo.option.ConnectionPasswordname> <value>000000value> <description>password to use against metastore databasedescription> property> configuration>
2.4 Hive数据访问
2.4.1 Hive客户端访问
[root@iZnq8v4wpstsagZ bin]# hive
2.4.2 HiveJDBC访问
#启动hive服务端
[root@iZnq8v4wpstsagZ bin]# hiveserver2
#另开一个窗口使用jdbc访问,连接成功服务端返回OK
[root@iZnq8v4wpstsagZ bin]# beeline
Beeline version 1.2.2 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: root
Enter password for jdbc:hive2://localhost:10000: (回车即可)
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| test_db |
| test_db1 |
+----------------+--+
3 rows selected (1.246 seconds)
2.5 Hive基本操作
2.5.1 Hive常用交互命令
[root@iZnq8v4wpstsagZ bin]# hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
–database:指定数据库
-e:不进入hive的交互窗口执行SQL语句
-f:用于执行SQL文件
2.5.2 Hive其他命令操作
1.退出cli
hive> exit;
#或
hive> quit;
在新版的hive中没区别了,在以前的版本是有的:
exit:先隐性提交数据,再退出;
quit:不提交数据,退出;
2.在hive cli命令窗口中如何查看hdfs文件系统
hive> dfs -ls /;
3.在hive cli命令窗口中执行本地文件系统命令
hive> !ls /opt/module/datas;
4.查看在hive中输入的所有历史命令
#进入当前用户的家目录
[root@iZnq8v4wpstsagZ bin]# cat /root/.hivehistory
2.6 Hive常见属性配置
2.6.1 Hive数据仓库位置配置
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
<description>location of default database for the warehousedescription>
property>
- default数据仓库的最原始位置是在hdfs上的:/user/hive/warehouse路径下。
- 在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
- 修改default数据仓库原始位置(将上述配置信息拷贝到hive-site.xml文件中修改)。
2.6.2 查询后信息显示配置
在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置
<!--查询显示表头信息-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--显示当前数据-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2.6.3 Hive运行日志信息配置
Hive的日志配置文件在/opt/module/apache-hive-1.2.2-bin/conf/目录下,修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为hive-log4j.properties。
日志存放目录为:
#/tmp/root
hive.log.dir=${java.io.tmpdir}/${user.name}
可修改该参数更改存放位置。
2.6.4 参数配置方式
查看当前所有的配置信息或某个参数配置
hive (default)> set;
hive (default)> set mapred.reduce.tasks;
1)配置文件:
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
2)命令行参数方式启动hive(仅对本次hive启动有效):
[root@iZnq8v4wpstsagZ bin]# hive -hiveconf mapred.reduce.tasks=10;
3)参数声明方式(仅对本次hive启动有效):
hive (default)> set mapred.reduce.tasks=10;
3 Hive数据类型
3.1 基本数据类型
3.1.1 数值类型
| Hive数据类型 | Java数据类型 | 说明 |
|---|---|---|
| TINYINT | byte | 1byte有符号整数,-128 to 127 |
| SMALINT | short | 2byte有符号整数,-32,768 to 32,767 |
| INT/INTEGER | int | 4byte有符号整数,-2,147,483,648 to 2,147,483,647 |
| BIGINT | long | 8byte有符号整数,-9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| FLOAT | float | 4byte单精度浮点数 |
| DOUBLE | double | 8byte双精度浮点数 |
| DECIMAL | Decimal | Hive 0.11.0开始引入,精度为38位,Hive 0.13.0引入了用户自定义的精度和比例 |
| NUMERIC | Decimal | 类似DECIMAL,开始于Hive 3.0.0 |
3.1.2 日期时间类型
| Hive数据类型 | Java数据类型 | 说明 |
|---|---|---|
| TIMESTAMP | TimeStamp | 时间戳yyyy-mm-dd hh:mm:ss[.f…],开始于Hive 0.8.0 |
| DATE | java.util.Date | 日期yyyy-mm-dd,开始于Hive 0.12.0 |
| INTERVAL | - | 开始于Hive 1.2.0 |
3.1.3 字符串类型
| Hive数据类型 | Java数据类型 | 说明 |
|---|---|---|
| STRING | string | 字符系列,可以指定字符集,可以使用单引号或者双引号,理论上可存储2GB |
| VARCHAR | string | 长度不定字符串,长度1 - 65535,开始于Hive 0.12.0 |
| CHAR | string | 长度固定字符串,长度0-255,开始于Hive 0.13.0 |
3.1.3 其他类型
| Hive数据类型 | Java数据类型 | 说明 |
|---|---|---|
| BOOLEAN | boolean | 布尔类型,true或者false |
| BINARY | - | 字节序列 |
3.2 集合数据类型
| Hive数据类型 | Java数据类型 | 说明 |
|---|---|---|
| STRUCT | 类似C中Struct | STRUCT |
| MAP | 类似Map | MAP |
| ARRAY | 类似Array | ARRAY |
| UNIONTYPE | - | UNIONTYPE |
示例:
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
1.创建本地文件collection.txt
[root@iZnq8v4wpstsagZ datas]# vim collection.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
2.创建表
[root@iZnq8v4wpstsagZ datas]# hive
hive (default)> create table collection(
> name varchar(8),
> friends array<string>,
> children map<string,int>,
> address struct<street:string,city:string>
> )
> row format delimited fields terminated by ',' #列分割符
> collection items terminated by '_' #集合数据类型分隔符
> map keys terminated by ':' #Map中的kv分隔符
> lines terminated by '\n'; #行分隔符
3.导入collection.txt中数据到数据表collection
hive (default)> load data local inpath '/opt/module/datas/collection.txt' into table collection;
4.查询
hive (default)> select * from collection where name='songsong';
songsong ["bingbing","lili"] {"xiao song":18,"xiaoxiao song":19} {"street":"hui long guan","city":"beijing"}
hive (default)> select name,friends[1],children['xiao song'],address.city from collection where name='songsong';
songsong lili 18 beijing
3.3 类型转换
Hive的原子数据类型是可以进行隐式转换的,类似于Java的类型转换。
3.3.1 隐式类型转换
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
- 所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
- TINYINT、SMALLINT、INT都可以转换为FLOAT。
- BOOLEAN类型不可以转换为任何其它的类型。
3.3.2 强制类型转换
使用CAST可以实现强制类型转换,如:
CAST('1' AS INT)
如果强制类型转换失败则会返回NULL。
4 Data Definition Language
- CREATE DATABASE/SCHEMA,TABLE,VIEW,FUNCTION,INDEX
- DROP DATABASE/SCHEMA,TABLE,VIEW,INDEX
- TRUNCATE TABLE
- ALTER DATABASE/SCHEMA,TABLE,VIEW
- MSCK REPAIR TABLE(or ALTER TABLE RECOVER PARTITIONS)
- SHOW DATABASES/SCHEMAS,TABLES,TBLPROPERTIES,VIEWS,PARTITIONS,FUNCTION,INDEX[ES], COLUMNS, CREATE TABLE
- DESCRIBE DATABASE/SCHEMA, table_name, view_name, materialized_view_name
partitions除了show partitions table_name,通常都用于table语句的选项。
4.1 数据库操作
4.1.1 创建数据库
#创建一个数据库
hive (default)> create database db_hive
#避免要创建的数据库已经存在错误,增加if not exists判断
hive (default)> create database if not exists db_hive;
#创建一个数据,指定数据库在HDFS上的存放位置,默认在/user/hive/warehouse/目录下创建db_hive_loc.db
hive (default)> create database if not exists db_hive_loc location '/user/hive/warehouse/db_hive_loc.db';
4.1.2 查询数据库
#显示所有数据库
hive (default)> show databases;
#过滤显示数据库
hive (default)> show databases like 'db_hive*';
#显示数据库信息
hive (db_hive)> desc database db_hive;
#显示数据库详细信息,extended
hive (default)> desc database extended db_hive;
4.1.2 修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置kv属性,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
#添加数据库属性,可通过desc database extended db_hive查看
hive (default)> alter database db_hive set dbproperties('createTime'='20170830','updateTime'='20191012');
4.1.3 删除数据库
#删除空数据库
hive (default)> drop database if exists db_hive1;
#数据库不为空可使用cascade级联删除(慎用)
drop database if exists db_hive cascade;
4.2 表操作
4.2.1 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
字段分析:
CREATE TABLE创建表,使用IF NOT EXISTS判断表是否存在,避免异常。EXTERNAL创建外部表。COMMENT为表和列添加注释。PARTITIONED BY创建分区表CLUSTERED BY创建分桶表SORTED BY排序ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]。SerDe是Serialize/Deserilize的简称,目的用于序列化和反序列化。用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。STORED AS指定存储文件类型,常用的有SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)LOCATION指定表在HDFS上的存储位置LIKE复制现有的表结构,不复制数据
4.2.1.1 管理表
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
#普通创建表
hive (default)> create table if not exists student2(
> id int,
> name string
> )
> row format delimited fields terminated by '\t'
> stored as textfile
> location '/user/hive/warehouse/student2';
#根据查询结果创建表
hive (default)> create table if not exists student3 as select id, name from student;
#复制表结构
hive (default)> create table if not exists student4 like student;
#查询表的类型,管理表或外部表
hive (default)> desc formatted student2;
4.2.1.2 外部表
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
#普通创建表
hive (default)> create external table if not exists student3(
> id int,
> name string
> )
> row format delimited fields terminated by '\t'
> stored as textfile
> location '/user/hive/warehouse/student3';
4.2.1.3 管理表与外部表的互相转换
#将外部表转换为管理表
hive (default)> alter table student3 set tblproperties('EXTERNAL'='FALSE');
#查看表详情
hive (default)> desc formatted student3;
4.2.1.4 分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
#创建分区表,根据月份分区
hive (default)> create table dept_partition(
> deptno int,
> dname string,
> loc string
> )
> partitioned by(month string)
> row format delimited fields terminated by '\t';
#加载数据到分区表
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table dept_partition partition(month='201910');
#查询分区表数据
hive (default)> select * from dept_partition where month='201910';
#查看分区表分区
hive (default)> show partitions dept_partition;
#创建单个分区
hive (default)> alter table dept_partition add partition(month='201909');
#创建多个分区
hive (default)> alter table dept_partition add partition(month='201907') partition(month='201908');
#删除单个分区
hive (default)> alter table dept_partition drop partition (month='201907');
#删除多个分区,注意逗号分割
hive (default)> alter table dept_partition drop partition (month='201908'), partition (month='201909');
多级分区则会创建多级目录。
几种加载数据的方式:
普通表加载数据可以直接通过dfs命令上传数据文件到表目录下,分区表与之不同,需要关联。
1.正常加载数据到分区表:
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table dept_partition partition(month='201910');
2.把数据直接上传到HDFS目录上,让分区、数据与分区表产生关联
#创建分区目录
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition/month=201912
#上传数据文件
hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition/month=201912;
#执行修复命令或添加分区,即可查询到分区和数据
hive (default)> msck repair table dept_partition;
#or
hive (default)> alter table dept_partition add partition(month='201912');
3.创建文件夹后load数据到分区
#创建分区目录
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition/month=201901
#加载数据到分区目录
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table dept_partition partition(month='201901');
4.2.1.5 分桶表
详见6.1.5 分桶及抽样查询
4.2.2 修改表
4.2.2.1 重命名表
hive (default)> alter table dept rename to dept_normal;
4.2.2.2 增加/修改/删除表分区
详见4.2.1.4 分区表
4.2.2.3 增加/修改/替换列信息
更新列语法:ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
增加和替换列语法:ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
#添加列
hive (default)> alter table dept_normal add columns(location string);
#更新列
hive (default)> alter table dept_normal change column loc loc string;
#调整列的顺序,将location列放到deptno列后
hive (default)> alter table dept_normal change column location location string after deptno;
#替换表中所有字段,相当于重新定义表字段
hive (default)> alter table dept_normal replace columns(deptno int,dname string,loc string);
4.2.2.4 删除表
hive (default)> drop table dept_normal;
5 Data Manipulation Language
5.1 数据导入
5.1.1 Load
语法:LOAD DATA [LOCAL] INPATH path_name [OVERWRITE] INTO TABLE table_name [PARTITION (partcol1=val1,…)] [INPUTFORMAT 'inputformat' SERDE 'serde'];
- LOCAL:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
- OVERWRITE:表示覆盖表中已有数据,否则表示追加
- PARTITION :表示上传到指定分区(分区表)
- INPUTFORMAT :从Hive 3.0开始
5.1.2 Insert
语法:
INSERT INTO|OVERWRITE TABLE table_name [PARTITION (partcol1=val1,…)] VALUES (val1,val2,...),...
INSERT INTO|OVERWRITE table_name [PARTITION (partcol1=val1,…)] SELECT ...
#插入多条数据
hive (default)> insert into table dept_partition partition(month='201910') values(1,'c','luan'),(2,'py','hefei');
#插入查询结果
hive (default)> insert into table dept_partition partition(month='201907') select deptno,dname,loc from dept_partition where month='201911';
5.1.3 As Select
#根据查询结果创建表
hive (default)> create table if not exists student3 as select id, name from student;
5.1.4 Location
#指定表加载数据路径
hive (default)> create table if not exists student5(
> id int, name string
> )
> row format delimited fields terminated by '\t'
> location '/user/hive/warehouse/student5';
#上传数据
hive (default)> dfs -put /opt/module/datas/student.txt /user/hive/warehouse/student5;
5.1.5 Import
hive (default)> import table dept_partition partition(month='201909') from
'/user/hive/warehouse/export/dept';
5.2 数据导出
5.2.1 Insert
#结果导出到本地目录(数据未格式化)
hive (default)> insert overwrite local directory '/opt/module/datas/export/dept' select * from dept_partition;
#格式化导出到本地目录
hive (default)> insert overwrite local directory '/opt/module/datas/export/dept' row format delimited fields terminated by '\t' select * from dept_partition;
#格式化导出到HDFS上
hive (default)> insert overwrite directory '/user/yutao/dept' row format delimited fields terminated by '\t' select * from dept_partition;
5.2.2 Hadoop
hive (default)> dfs -get /user/hive/warehouse/dept_partition/month=201909/000000_0
/opt/module/datas/export/dept_hadoop.txt;
5.2.3 Hive Shell
[root@iZnq8v4wpstsagZ bin]# hive -e 'select * from dept_partition;' > /opt/module/datas/export/dept_hive.txt;
5.2.4 Export
#导出到HDFS上
hive (default)> export table dept_partition to '/user/hive/warehouse/export/dept';
5.2.5 Sqoop
//TODO
5.3 数据清除
#truncate只能删除管理表中数据,不能删除外部表中数据
hive (default)> truncate table student;
6 Data Retrieval: Query
查询语法:
[WITH CommonTableExpression (, CommonTableExpression)*] (从Hive 0.13.0开始可用)
SELECT
[ALL | DISTINCT] select_expr, select_expr, ...
[FROM table_reference] #从Hive 0.13.0开始可选,如:SELECT 1+1;
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows] #offset从Hive 2.0.0开始支持
- SELECT语句可以是联合查询或另一个查询的子查询的一部分
- table_reference可以是常规表,视图,联接构造或子查询
- 表名和列名不区分大小写
- 在Hive 0.12和更早版本中,表和列名称中仅允许使用字母数字和下划线字符。在Hive 0.13和更高版本中,列名称可以包含任何 Unicode 字符。反引号(`)中指定的任何列名均按字面意义处理。在反引号字符串中,使用双反引号(``)表示反引号字符。
- 要恢复到0.13.0之前的行为并将列名限制为字母数字和下划线字符,请将配置属性设置 hive.support.quoted.identifiers 为 none,带反引号的名称被解释为正则表达式。
6.1 普通查询
6.1.1 基本查询
支持的算术运算符有:
+(加) -(减) *(乘) /(除) %(取余) &(按位取与) |(按位取或) ^ (按位异或)~(按位取反)
#查询所有列
hive (default)> select * from dept;
#查询当前数据库(从Hive 0.13.0开始)
hive (default)> SELECT current_database();
#指定数据库查询(从Hive 0.7开始的)
hive (default)> select * from db_hive.emp;
#查询具体的列,可取别名,as可省略
hive (default)> select deptno as no,dname from dept_normal
#运算符
hive (default)> select sal+1 from emp;
#统计数量
hive (default)> select count(*) cnt from emp;
#取最大值
hive (default)> select max(sal) max_sal from emp;
#取最小值
hive (default)> select min(sal) min_sal from emp;
#取和
hive (default)> select sum(sal) sum_sal from emp;
#取平均值
hive (default)> select avg(sal) avg_sal from emp;
#偏移量默认为0,查询5行
hive (default)> select * from emp limit 5;
#偏移量为2,查询2行,从Hive 2.0.0开始支持偏移量
hive (default)> select * from emp limit 2,2;
6.1.2 WHERE条件查询
#where条件查询,用法与mysql相同
hive (default)> select * from emp where sal >1000;
比较运算符:
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,其他的和等号(=)操作符的结果一致,如果任一为NULL则结果为NULL |
| A<>B,A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
A| 基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
|
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(val1,val2,…) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B,A REGEXP B | STRING 类型 | B是一个正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
逻辑运算符:
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
6.1.3 Group By分组 与 Having分组筛选
运行mr
#分组查询+having筛选,用法与mysql相同
hive (default)> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
6.1.4 Order By/Sort By排序
Order By:全局排序,一个Reducer。
#与mysql中用法相同
hive (default)> select ename, sal*2 twosal from emp order by twosal,ename;
Sort By:每个Reducer内部进行排序,对全局结果集来说不是排序。
#与order by用法相似
hive (default)> select * from emp sort by empno desc;
Distribute By:分区排序,类似MR中partition,进行分区,可以结合sort by一起使用。
#先对deptno进行分区,再按照empno排序
hive (default)> select * from emp distribute by deptno sort by empno desc;
Cluster By:当distribute by和sorts by字段相同时,可以使用cluster by方式。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
hive (default)> select * from emp cluster by deptno;
#等价于
hive (default)> select * from emp distribute by deptno sort by deptno;
6.1.5 分桶及抽样查询
分区与分桶:
- 分区针对的是数据的存储路径;分桶针对的是数据文件。
- 分区提供了一种隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是要确定合适的划分大小。
- 分桶是将数据集分解成更容易管理的若干部分的另一种技术。
6.1.5.1 分桶表
#根据id创建4个分桶
hive (default)> create table stu_buck(
> id int,
> name string
> )
> clustered by(id)
> into 4 buckets
> row format delimited fields terminated by '\t';
#属性必须设置为true
hive (default)> set hive.enforce.bucketing=true;
#添加的数据无法分桶
hive (default)> load data local inpath '/opt/module/datas/students.txt' into table stu_buck;
#运行的是MR,可以分桶
hive (default)> insert into table stu_buck select id,name from stu;
6.1.5.2 抽样查询
语法:TABLESAMPLE(BUCKET x OUT OF y [ON col_name])
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);
- x表示从哪个bucket开始抽取,如果需要取多个bucket,以后的bucket为当前bucket加上y
- y必须是table总bucket数的倍数或者因子
- x的值必须小于等于y的值
6.2 连接查询
连接查询中的笛卡儿积会在以下几种情况下产生:
- 省略连接条件
- 连接条件无效
- 所有表中的所有行互相连接
连接查询中join…on不支持or
6.2.1 等值连接
Hive支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。
hive (default)> select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;
6.2.2 内连接
内连接是相对于外连接的,只有满足关联条件才输出,而关联条件未必是等值关联,从集合论角度看:等值连接是内连接的子集。
hive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
6.2.3 左外连接
JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;
6.2.4 右外连接
JOIN操作符右边表中符合WHERE子句的所有记录将会被返回
hive (default)> select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
6.2.5 满外连接
将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
hive (default)> select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
7 函数
7.1 系统内置函数
#查看系统自带的函数
hive (default)> show functions;
#显示自带的函数的用法
hive (default)> desc function upper;
#详细显示自带的函数的用法
hive (default)> desc function extended upper;
常用函数:
- current_database():查询当前数据库。
- nvl(expr1,expr2):判断expr1是否为null,如果为null用expr2替代,与mysql中ifnull用法相同。
- case when:与mysql中用法相同。
- concat(str1,str2,…):拼接字符串。
- concat_ws(separator,str1,str2,…):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间。
- collect_set(col):仅支持基本数据类型,将某字段的值进行去重汇总,产生array类型字段。
7.2 自定义函数
用户自定义函数有三种:
(1)UDF(User-Defined-Function):一进一出
(2)UDAF(User-Defined Aggregation Function):聚集函数,多进一出,类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions):一进多出,如lateral view explore()
自定义函数步骤:
- 创建一个Maven工程
- 导入依赖
<dependencies> <dependency> <groupId>org.apache.hivegroupId> <artifactId>hive-execartifactId> <version>1.2.1version> dependency> dependencies> - 创建类继承
org.apache.hadoop.hive.ql.exec.UDF,实现evaluate函数package com.yutao.hive; public class MyLower extends UDF { public String evaluate (final String s) { if (s == null) { return null; } return s.toLowerCase(); } } - 打成jar包上传到服务器
/opt/module/jars/udf.jar - 将jar包添加到hive的classpath
hive (default)> add jar /opt/module/datas/udf.jar; - 创建临时函数与开发好的java class关联
hive (default)> create temporary function mylower as "com.yutao.hive.MyLower"; - 即可在hql中使用自定义的函数strip
hive (default)> select ename, MyLower(ename) lowername from emp;
未完待续。。。