OpenCV相机标定及距离估计(单目)
相机标定基本知识


![]()
对于针孔摄像机模型,一幅视图是通过透视变换将三维空间中的点投影到图像平面。投影公式如下:
![s \cdot m' = A\cdot[R|t] \cdot M'](http://img.e-com-net.com/image/info8/45749da114bb4b90b5501dfb7b5c0295.png) 或者
或者
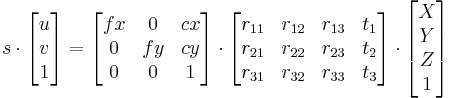
这里(X, Y, Z)是一个点的世界坐标,(u, v)是点投影在图像平面的坐标,以像素为单位。A被称作摄像机矩阵,或者内参数矩阵。(cx, cy)是基准点(通常在图像的中心),fx, fy是以像素为单位的焦距。所以如果因为某些因素对来自于摄像机的一幅图像升采样或者降采样,所有这些参数(fx, fy, cx和cy)都将被缩放(乘或者除)同样的尺度。内参数矩阵不依赖场景的视图,一旦计算出,可以被重复使用(只要焦距固定)。旋转-平移矩阵[R|t]被称作外参数矩阵,它用来描述相机相对于一个固定场景的运动,或者相反,物体围绕相机的的刚性运动。也就是[R|t]将点(X, Y, Z)的坐标变换到某个坐标系,这个坐标系相对于摄像机来说是固定不变的。上面的变换等价与下面的形式(z≠0):
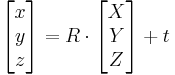
x' = x / z
y' = y / z
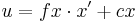
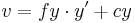
真正的镜头通常有一些形变,主要的变形为径向形变,也会有轻微的切向形变。所以上面的模型可以扩展为:
x' = x / z
y' = y / z
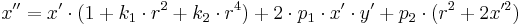
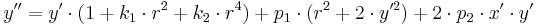
这里 r2 = x'2 + y'2

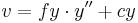
k1和k2是径向形变系数,p1和p1是切向形变系数。OpenCV中没有考虑高阶系数。形变系数跟拍摄的场景无关,因此它们是内参数,而且与拍摄图像的分辨率无关。
OpenCV标定函数
| double cv::calibrateCamera | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints, | ||
| Size | imageSize, | ||
| InputOutputArray | cameraMatrix, | ||
| InputOutputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| OutputArray | stdDeviationsIntrinsics, | ||
| OutputArray | stdDeviationsExtrinsics, | ||
| OutputArray | perViewErrors, | ||
| int | flags = 0, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON) |
||
| ) |
Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern.
Parameters
| objectPoints | In the new interface it is a vector of vectors of calibration pattern points in the calibration pattern coordinate space (e.g. std::vector |
| imagePoints | In the new interface it is a vector of vectors of the projections of calibration pattern points (e.g. std::vector |
| imageSize | Size of the image used only to initialize the intrinsic camera matrix. |
| cameraMatrix | Output 3x3 floating-point camera matrix A=⎡⎣⎢⎢⎢fx000fy0cxcy1⎤⎦⎥⎥⎥ . If CV_CALIB_USE_INTRINSIC_GUESS and/or CALIB_FIX_ASPECT_RATIO are specified, some or all of fx, fy, cx, cy must be initialized before calling the function. |
| distCoeffs | Output vector of distortion coefficients (k1,k2,p1,p2[,k3[,k4,k5,k6[,s1,s2,s3,s4[,τx,τy]]]]) of 4, 5, 8, 12 or 14 elements. |
| rvecs | Output vector of rotation vectors (see Rodrigues ) estimated for each pattern view (e.g. std::vector |
| tvecs | Output vector of translation vectors estimated for each pattern view. |
| stdDeviationsIntrinsics | Output vector of standard deviations estimated for intrinsic parameters. Order of deviations values: (fx,fy,cx,cy,k1,k2,p1,p2,k3,k4,k5,k6,s1,s2,s3,s4,τx,τy) If one of parameters is not estimated, it's deviation is equals to zero. |
| stdDeviationsExtrinsics | Output vector of standard deviations estimated for extrinsic parameters. Order of deviations values: (R1,T1,…,RM,TM) where M is number of pattern views, Ri,Ti are concatenated 1x3 vectors. |
| perViewErrors | Output vector of the RMS re-projection error estimated for each pattern view. |
| flags | Different flags that may be zero or a combination of the following values:
|
| criteria | Termination criteria for the iterative optimization algorithm. |
Returns
the overall RMS re-projection error.
The function estimates the intrinsic camera parameters and extrinsic parameters for each of the views. The algorithm is based on [206] and [17] . The coordinates of 3D object points and their corresponding 2D projections in each view must be specified. That may be achieved by using an object with a known geometry and easily detectable feature points. Such an object is called a calibration rig or calibration pattern, and OpenCV has built-in support for a chessboard as a calibration rig (see findChessboardCorners ). Currently, initialization of intrinsic parameters (when CALIB_USE_INTRINSIC_GUESS is not set) is only implemented for planar calibration patterns (where Z-coordinates of the object points must be all zeros). 3D calibration rigs can also be used as long as initial cameraMatrix is provided.
The algorithm performs the following steps:
- Compute the initial intrinsic parameters (the option only available for planar calibration patterns) or read them from the input parameters. The distortion coefficients are all set to zeros initially unless some of CALIB_FIX_K? are specified.
- Estimate the initial camera pose as if the intrinsic parameters have been already known. This is done using solvePnP .
- Run the global Levenberg-Marquardt optimization algorithm to minimize the reprojection error, that is, the total sum of squared distances between the observed feature points imagePoints and the projected (using the current estimates for camera parameters and the poses) object points objectPoints. See projectPoints for details.
Note
If you use a non-square (=non-NxN) grid and findChessboardCorners for calibration, and calibrateCamera returns bad values (zero distortion coefficients, an image center very far from (w/2-0.5,h/2-0.5), and/or large differences between fx and fy (ratios of 10:1 or more)), then you have probably used patternSize=cvSize(rows,cols) instead of using patternSize=cvSize(cols,rows) in findChessboardCorners .
See also
findChessboardCorners, solvePnP, initCameraMatrix2D, stereoCalibrate, undistort
Reference
https://docs.opencv.org/2.4/modules/calib3d/doc/camera_calibration_and_3d_reconstruction.html
杂记
---
一次相机标定仅仅只是对物理相机模型的一次近似,再具体一点来说,一次标定仅仅是对相机物理模型在采样空间范围内的一次近似。所以当你成像物体所在的空间跟相机标定时的采样空间不一样的时候,你可能永远都没办法得到足够高的精度,当你大幅改变相机与成像物体的距离的时候,你最好重新标定相机。
通过摄像机标定我们可以知道些什么:
1.外参数矩阵。告诉你现实世界点(世界坐标)是怎样经过旋转和平移,然后落到另一个现实世界点(摄像机坐标)上。
2.内参数矩阵。告诉你上述那个点在1的基础上,是如何继续经过摄像机的镜头、并通过针孔成像和电子转化而成为像素点的。
3.畸变矩阵。告诉你为什么上面那个像素点并没有落在理论计算该落在的位置上,还tm产生了一定的偏移和变形!!!
总的来说,摄像机标定是通过寻找对象在图像与现实世界的转换数学关系,找出其定量的联系,从而实现从图像中测量出实际数据的目的。
---
每个标定板摆放的角度对应一个单应矩阵。然后每个矩阵根据旋转矩阵的单位正交性,可以构成2个约束,对应2个方程。
内参数矩阵中包含了5个自由度(驻点坐标u0,v0),相机焦距(fx,fy),X轴和Y轴垂直扭曲skew。因此至少3个单应关系,才可以求解,因此至少3个摆放的角度。
另外考虑畸变参数的建模,一般有4个,因此使用LM方法完成非线性优化。实际应用中摆放的角度20个,不同的角度能够保证目标函数更加接近凸函数,便于完成所有参数的迭代优化,使得结果更加准确。
---
通过镜头,一个三维空间中的物体经常会被映射成一个倒立缩小的像(当然显微镜是放大的,不过常用的相机都是缩小的),被传感器感知到。
理想情况下,镜头的光轴(就是通过镜头中心垂直于传感器平面的直线)应该是穿过图像的正中间的,但是,实际由于安装精度的问题,总是存在误差,这种误差需要用内参来描述;
理想情况下,相机对x方向和y方向的尺寸的缩小比例是一样的,但实际上,镜头如果不是完美的圆,传感器上的像素如果不是完美的紧密排列的正方形,都可能会导致这两个方向的缩小比例不一致。内参中包含两个参数可以描述这两个方向的缩放比例,不仅可以将用像素数量来衡量的长度转换成三维空间中的用其它单位(比如米)来衡量的长度,也可以表示在x和y方向的尺度变换的不一致性;
理想情况下,镜头会将一个三维空间中的直线也映射成直线(即射影变换),但实际上,镜头无法这么完美,通过镜头映射之后,直线会变弯,所以需要相机的畸变参数来描述这种变形效果。然后,说到为什么需要20张图片,这只是一个经验值,实际上太多也不好,太少也不好。单纯从统计上来看,可能越多会越好,但是,实际上图片太多可能会让参数优化的结果变差,因为棋盘格角点坐标的确定是存在误差的,而且这种误差很难说是符合高斯分布的,同时,标定过程所用的非线性迭代优化算法不能保证总是得到最优解,而更多的图片,可能会增加算法陷入局部最优的可能性。
---
总结一下就是:外参:另一个(相机或世界)坐标系->这个个相机坐标系,内参:这个相机坐标系->图像坐标系
实际应用中,个人经验是,单目标定板还是不要倾斜角度太大,尽量在摄像机视场范围内的所有地方都出现,远近也可以做一做,但不需要拉的太远。不知道有没有更好的操作,之前这么做误差还行,所以也就先这么搞着。
张正友的标定法论文里结果显示11幅图之后的效果都很好,标定板绕一个轴转动的角度在45度时最好。